进入第六章:《Spark SQL 和 Datasets》。
Datasets 和 DataFrames的内存管理
Spark是一个密集的内存分布式大数据引擎,因此对其内存的有效使用对其执行速度至关重要。在其整个发行历史中,Spark的内存使用已发生了重大变化:
- Spark 1.0使用基于RDD的Java对象进行内存存储,序列化和反序列化,这在资源和速度方面都非常昂贵。 另外,存储空间是分配在Java堆上的,因此您只能依靠JVM的大型数据集的垃圾回收(GC)。
- Spark 1.x引入了Project Tungsten。 它的突出特点之一是基于一种新的基于行的内部格式,可使用偏移量和指针在堆内存中对数据集和数据帧进行布局。 Spark使用一种称为 Encodes 的有效机制在JVM及其内部Tungsten格式之间进行序列化和反序列化。 将内存分配到堆外意味着Spark较少受到GC的阻碍。
- Spark 2.x引入了第二代Tungsten引擎,具有完整的代码生成和基于列的矢量化内存布局的功能。 该新版本以现代编译器的思想和技术为基础,还利用现代CPU和缓存体系结构,以“单指令,多数据”(SIMD)方法进行快速并行数据访问。
Dataset Encoder
编码器将堆外内存中的数据从Spark的内部Tungsten格式转换为JVM Java对象。 换句话说,他们将Dataset对象从Spark的内部格式序列化和反序列化为JVM对象,包括原始数据类型。 例如,一个Encoder [T]将从Spark的内部钨格式转换为Dataset [T]。 Spark具有内置支持,可自动为原始类型(例如字符串,整数,长整数),Scala案例类和JavaBeans生成编码器。 与Java和Kryo的序列化和反序列化相比,Spark编码器明显更快。
在我们先前的Java示例中,我们显式创建了一个编码器:
Encoder<UsageCost> usageCostEncoder = Encoders.bean(UsageCost.class);
但是,对于Scala,Spark会自动生成字节码以实现这些高效转换器。 让我们看一下Spark内部基于Tungsten行的格式。
Spark 内部格式对比Java object格式
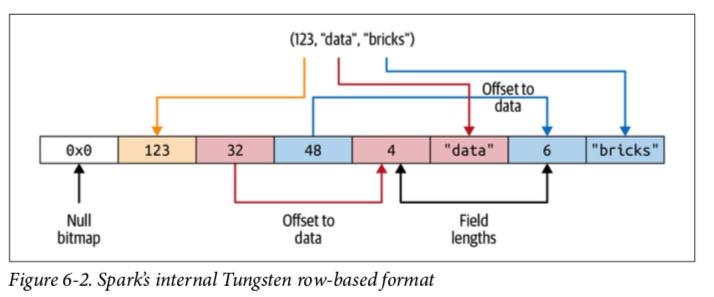
Java对象开销很大,包括标头信息,哈希码,Unicode信息等。即使是简单的Java字符串(如“ abcd”)也需要48字节的存储空间,而不是您可能期望的4字节。 想象一下创建一个MyClass(Int,String,String)对象的开销。 Spark不会为数据集或DataFrame创建基于JVM的对象,而是分配堆外Java内存来布置其数据,并使用编码器将数据从内存中表示形式转换为JVM对象。 例如,下图显示了如何在内部存储JVM对象MyClass(Int,String,String)。

当数据以这种连续的方式存储并且可以通过指针算术和offets访问时,编码器可以快速序列化或反序列化该数据。
序列号与反序列化 (SerDe)
在分布式计算中,SerDe 不是一个新概念。在分布式计算中,数据经常要进行SerDe,以便在集群计算机节点之间通过网络传播。序列化和反序列化是这样的过程,类型化对象被sender编码成字节码(serialized),然后receiver 把字节码格式转为类型化对象(deserialized)。
JVM拥有自己的内置Java序列化器和反序列化器,但效率低下,因为 JVM 在堆内存中创建的Java对象非常臃肿。 因此,该过程很慢。
出于以下几个原因,这是Dataset编码器可以解决的地方:
- Spark的内部Tungsten二进制格式将对象存储在Java堆内存之外,并且结构紧凑,因此这些对象占用的空间更少。
- 编码器可以通过使用带有内存地址和偏移量的简单指针算法在内存中遍历来快速进行序列化
- 在接收端,编码器可以快速将二进制表示形式反序列化为Spark的内部表示形式。 编码器不受JVM的垃圾回收暂停的影响。
使用Dataset的代价
与在Spark中引入 Encoder 之前使用的其他串行器相比,它开销较小且可以忍受。 但是,在较大的数据集和许多查询中,这会产生费用并且会影响性能。
降低成本的策略
减轻过度序列化和反序列化的一种策略是在查询中使用DSL表达式,并避免过度使用lambda作为匿名函数作为高阶函数的参数。 由于lambda在运行前一直是匿名且对Catalyst优化器不透明,因此当您使用它们时,它不能有效地识别您在做什么(您没有告诉Spark该怎么做),因此无法优化查询。
第二种策略是将查询链接在一起,以最大程度减少序列化和反序列化。 将查询链接在一起是Spark的一种常见做法。
让我们用一个简单的例子来说明。 假设我们有一个类型为Person的Dataset,其中Person被定义为Scala case class:
// In Scala
Person(id: Integer, firstName: String, middleName: String, lastName: String, gender: String, birthDate: String, ssn: String, salary: String)
我们想使用函数式编程对此数据集发出一组查询。
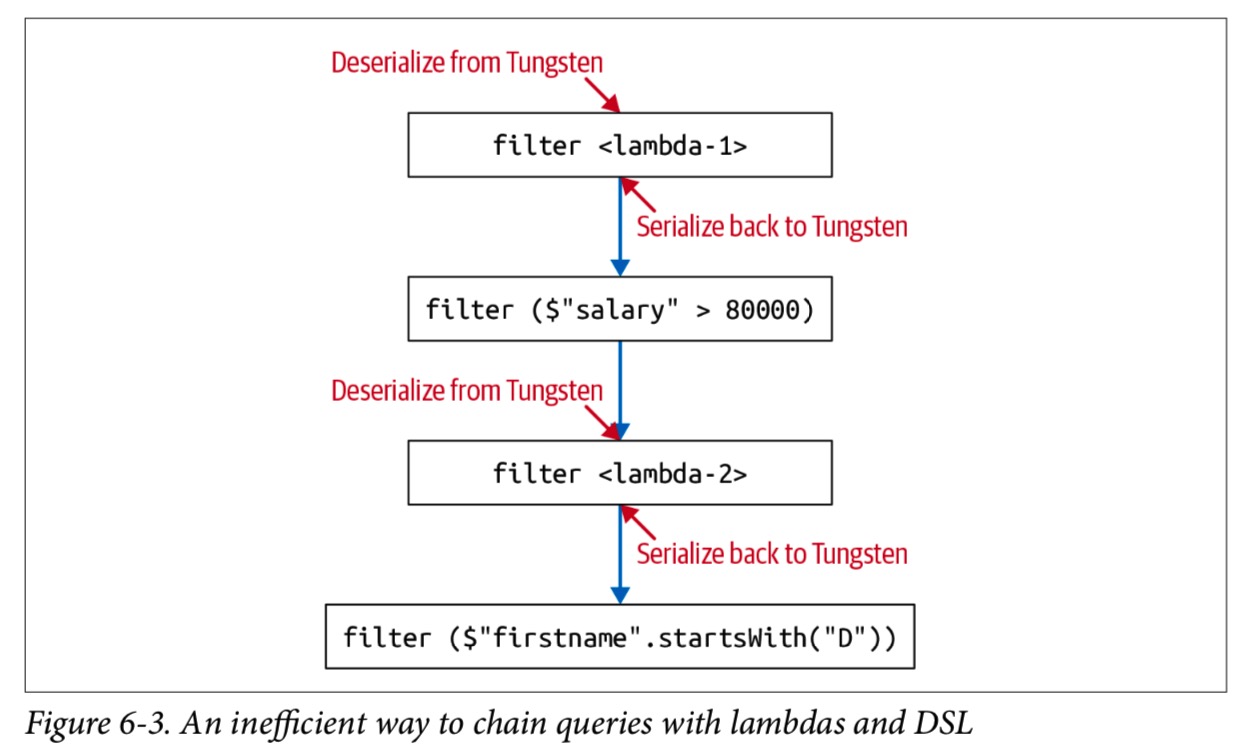
让我们来研究一下这样一种情况,在这种情况下,我们低效地编写查询,这种方式会无意间导致重复序列化和反序列化的成本:
import java.util.Calendar
val earliestYear = Calendar.getInstance.get(Calendar.YEAR) - 40
personDS
// Everyone above 40: lambda-1
.filter(x => x.birthDate.split("-")(0).toInt > earliestYear)
// Everyone earning more than 80K
.filter($"salary" > 80000)
// Last name starts with J: lambda-2
.filter(x => x.lastName.startsWith("J"))
// First name starts with D
.filter($"firstName".startsWith("D"))
.count()
如下图所示,每次我们从lambda迁移到DSL(filter($”salary” > 8000))时,都会产生序列化和反序列化Person JVM对象的成本。
相比之下,以下查询仅使用DSL,不使用lambda。 结果,它的效率更高-整个组合查询和链接查询都不需要序列化/反序列化:
personDS
.filter(year($"birthDate") > earliestYear) // Everyone above 40
.filter($"salary" > 80000) // Everyone earning more than 80K
.filter($"lastName".startsWith("J")) // Last name starts with J
.filter($"firstName".startsWith("D")) // First name starts with D
.count()