进入第五章:《Spark SQL 和 DataFrame:对接外部数据源》。
- Spark SQL 与 Hive
- 使用 Spark SQL Shell,Beeline,Tableau
- 外部数据源
- DataFrames和Spark SQL中的高阶函数
- DataFrames 和 Spark SQL 的常用操作
Spark SQL 与 Hive
Spark SQL是Apache Spark的基础组件,该组件将关系处理与Spark的功能编程API集成在一起。 Spark SQL使Spark程序员可以利用更快的性能和关系编程(例如声明式查询和优化的存储)以及调用复杂的分析库(例如机器学习)的好处。
自定义函数UDF
尽管Apache Spark具有大量内置函数,但Spark的灵活性允许数据工程师和数据科学家也定义自己的功能。 这些被称为用户定义函数(UDF)。
1. Spark SQL UDFs
// In Scala
// Create cubed function
val cubed = (s: Long) => {
s*s*s
}
// Register UDF
spark.udf.register("cubed", cubed)
// Create temporary view
spark.range(1, 9).createOrReplaceTempView("udf_test")
# In Python
from pyspark.sql.types import LongType
# Create cubed function
def cubed(s): returns*s*s
# Register UDF
spark.udf.register("cubed", cubed, LongType())
# Generate temporary view
spark.range(1, 9).createOrReplaceTempView("udf_test")
使用Spark SQL 调用 cubed 函数:
// In Scala/Python
// Query the cubed UDF
spark.sql("SELECT id, cubed(id) AS id_cubed FROM udf_test").show()
2. Spark SQL中的评估顺序和空检查
Spark SQL(包括SQL,DataFrame API和Dataset API)不保证子表达式的求值顺序。 例如,以下查询不能保证在strlen(s) > 1子句之前执行s is NOT NULL子句:
spark.sql("SELECT s FROM test1 WHERE s IS NOT NULL AND strlen(s) > 1")
因此,要执行正确的空检查,有如下的建议:
- 使UDF本身了解Null,并在UDF内部进行Null检查。
- 使用IF或CASE WHEN表达式进行空检查,并在条件分支中调用UDF。
3. 使用Pandas UDF加速和分发PySpark UDF
之前使用PySpark UDF存在的主要问题之一是,它们的性能比Scala UDF慢。 这是因为PySpark UDF需要在JVM和Python之间进行数据移动,这非常昂贵。 为了解决此问题,Pandas UDF(也称为矢量化UDF)作为Apache Spark 2.3的一部分引入。 Pandas UDF使用Apache Arrow传输数据,使用Pandas处理数据。 您可以使用关键字pandas_udf作为装饰器来定义Pandas UDF,或者包装函数本身。 一旦数据以Apache Arrow格式存储,就不再需要对数据进行序列化/处理,因为它已经是Python进程可使用的格式。 您不是在逐行操作单个输入,而是在Pandas Series或DataFrame上进行操作(即矢量化执行)。
从具有Python 3.6及更高版本的Apache Spark 3.0起,Pandas UDF分为两类API:Pandas UDF和Pandas Function API。
Pandas UDFs
使用Apache Spark 3.0,Pandas UDF从Pandas UDF中的Python类型提示(例如pandas.Series,pandas.DataFrame,Tuple和Iterator)推断Pandas UDF类型。 以前,您需要手动定义和指定每种Pandas UDF类型。 当前,Pandas UDF中支持的Python类型提示的情况包括:“序列到序列”,“序列到迭代器”,“序列到迭代器”,“多个序列”到“序列迭代器”以及“序列到标量”(单个值)。
Pandas Function APIs
Pandas函数API允许您将本地Python函数直接应用于PySpark DataFrame,其中输入和输出均为Pandas实例。 对于Spark 3.0,受支持的Pandas Function API为 grouped map, map, cogrouped map.
以下是用于Spark 3.0的标量Pandas UDF的示例:
# In Python
# Import pandas
import pandas as pd
# Import various pyspark SQL functions including pandas_udf
from pyspark.sql.functions import col, pandas_udf
from pyspark.sql.types import LongType
# Declare the cubed function
def cubed(a: pd.Series) -> pd.Series:
return a*a*a
# Create the pandas UDF for the cubed function
cubed_udf = pandas_udf(cubed, returnType=LongType())
前面的代码片段声明了一个称为cubes()的函数,该函数执行立方体操作。 这是一个常规的Pandas函数,带有附加的 cubed_udf = pandas_udf()调用,以创建我们的Pandas UDF。
For pandas series:
# Create a Pandas Series
x = pd.Series([1, 2, 3])
# The function for a pandas_udf executed with local Pandas data
print(cubed(x))
For Spark DataFrame:
# Create a Spark DataFrame, 'spark' is an existing SparkSession
df = spark.range(1, 4)
# Execute function as a Spark vectorized UDF
df.select("id", cubed_udf(col("id"))).show()
与局部函数相反,使用向量化的UDF将导致执行Spark作业。 先前的本地函数是仅在Spark driver 上执行的Pandas函数。 当查看此pandas_udf函数的其中一个阶段的Spark UI时,这一点变得更加明显:
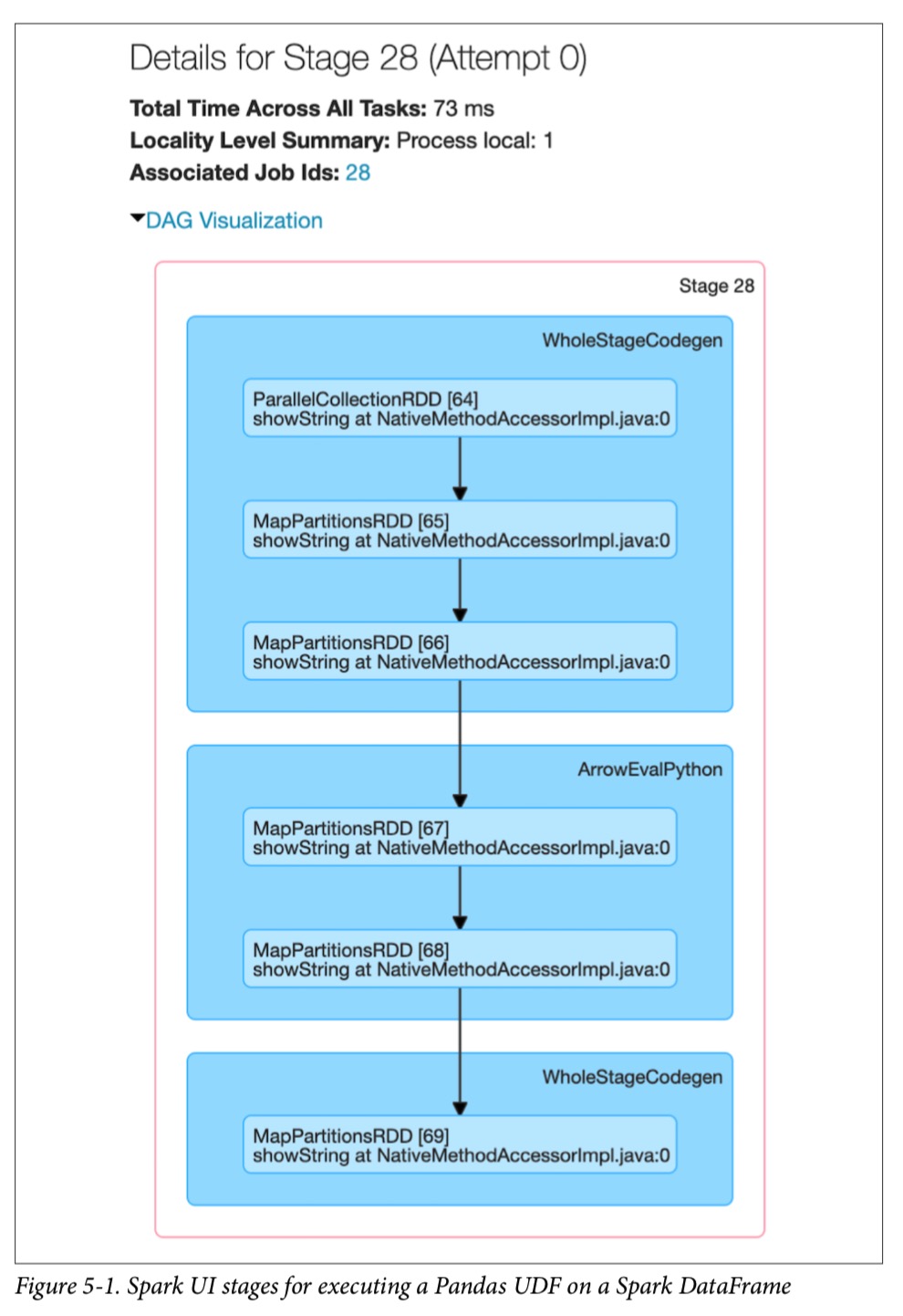
像许多Spark作业一样,该 job 从parallelize()开始以将本地数据(Arrow binary batches)发送给exectutors,并调用mapPartitions()将Arrow binary batches转换为Spark的内部数据格式,该格式可以分发给Spark workers 。有很多 WholeStageCodegen的步骤,代表了性能上的根本提升(由于Project Tungsten的整个阶段代码生成,可以显着提高CPU效率和性能)。 但是,正是在 ArrowEvalPython 步骤执行了 Pandas UDF。
使用 Spark SQL Shell,Beeline,Tableau
有多种查询Apache Spark的机制,包括Spark SQL Shell,Beeline CLI实用程序以及诸如Tableau和Power BI之类的报告工具。
使用 Spark SQL Shell
一个执行Spark SQL查询的便捷工具是spark-sql CLI。 虽然此实用程序在本地模式下与Hive Metastore服务进行通信,但它不会与Thrift JDBC / ODBC服务器(也称为Spark Thrift Server或STS)通信。 STS允许JDBC / ODBC客户端在Apache Spark上通过JDBC和ODBC协议执行SQL查询。
要启动Spark SQL CLI,请在$SPARK_HOME文件夹中执行以下命令:
./bin/spark-sql
Create a table
spark-sql> CREATE TABLE people (name STRING, age int);
Insert data into the table
spark-sql> INSERT INTO people VALUES (“Michael”, NULL);
Running a Spark SQL query
spark-sql> SHOW TABLES;
spark-sql> SELECT * FROM people WHERE age < 20;
使用 Beeline
如果您使用过Apache Hive,那么您可能会熟悉命令行工具Beeline,这是用于针对HiveServer2运行HiveQL查询的通用实用程序。 Beeline是基于SQLLine CLI的JDBC客户端。 您可以使用同一实用程序对Spark Thrift服务器执行Spark SQL查询。 请注意,当前实现的Thrift JDBC / ODBC服务器与Hive 1.2.1中的HiveServer2相对应。 您可以使用Spark或Hive 1.2.1随附的以下Beeline脚本测试JDBC服务器。
启动 Thrift server
在$SPARK_HOME文件夹中执行以下命令:
./sbin/start-thriftserver.sh
通过Beeline 连接 Thrift server
./bin/beeline
!connect jdbc:hive2://localhost:10000
执行Spark SQL 查询
0: jdbc:hive2://localhost:10000> SHOW tables;
0: jdbc:hive2://localhost:10000> SELECT * FROM people;
停止 Thrift Server
./sbin/stop-thriftserver.sh
外部数据源
JDBC 和 SQL 数据库
Spark SQL包含一个数据源API,可以使用以下命令从其他数据库读取数据 JDBC。 当它以Dataframe形式返回结果时,它简化了对这些数据源的查询,从而提供了Spark SQL的所有优势(包括性能和与其他数据源的连接能力)。 首先,您需要为JDBC数据源指定JDBC驱动程序,并且该驱动程序必须位于Spark类路径上。 在$SPARK_HOME文件夹中,您将发出如下命令:
./bin/spark-shell –driver-class-path $database.jar –jars $database.jar
分区的重要性
在Spark SQL和JDBC外部源之间传输大量数据时,对数据源进行分区很重要。 您的所有数据都通过一个驱动程序连接进行,这可能导致饱和并显着降低提取性能,并可能使源系统的资源饱和。 尽管这些JDBC属性是可选的,但对于任何大规模操作,强烈建议使用表5-2中所示的属性。

用一个例子来说明以上几个参数的作用。比如根据以下设置:
- numPartitions:10
- lowerBound:1000
- upperBound:10000
那么步长就是1000, 然后将会创建 10 个 partition。这等同于十个查询:
- SELECT * FROM table WHERE partitionColumn BETWEEN 1000 and 2000
- SELECT * FROM table WHERE partitionColumn BETWEEN 2000 and 3000
- …
- SELECT * FROM table WHERE partitionColumn BETWEEN 9000 and 10000
虽然不包含所有内容,但在使用这些属性时,请牢记以下提示:
- numPartitions的最好是使用数量为Spark工作者数的倍数。 例如,如果有四个Spark工作节点,则可能从4个或8个分区开始。 但是,注意源系统可以很好地处理读取请求也很重要。 对于具有处理窗口(processing windows)的系统,您可以最大程度地增加对源系统的并发请求数。 对于缺少处理窗口的系统(例如OLTP系统连续处理数据),应减少并发请求的数量以防止源系统饱和。
- 最初,根据最小和最大partitionColumnColumn实际值计算lowerBound和upperBound。 例如,如果您选择
{numPartitions:10,lowerBound:1000,upperBound:10000},但是所有值都在2000到4000之间,则10个查询中只有2个(每个分区一个)将执行所有工作。 在这种情况下,更好的配置将是{numPartitions:10,lowerBound:2000,upperBound:4000}。 - 选择可以均匀分布的partitionColumn以避免数据倾斜。 例如,如果您的partitionColumn的大多数值为2500,且
{numPartitions:10,lowerBound:1000,upperBound:10000},大部分工作将由请求2000到3000之间的值的任务执行。 选择不同的partitionColumn,或者在可能的情况下生成一个新的(也许是多个列的哈希),以便更均匀地分配您的分区。
连接其他数据源
- PostgreSQL
- MySQL
- Azure Cosmos DB
- MS SQL Server
- Apache Cassandra
- Snowflake
- MongoDB
DataFrames和Spark SQL中的高阶函数
由于复杂数据类型是简单数据类型的组合,因此很容易直接对其进行操作。 有两种用于处理复杂数据类型的典型解决方案:
- 将嵌套结构分解为单独的行,应用某些函数,然后重新创建嵌套结构
- 构建用户定义的函数
这些方法的好处是允许您以表格格式考虑问题。 它们通常涉及(但不限于)使用统一函数(utility functions),例如 get_json_object(), from_json(), to_json(), explode(), and selectExpr()。
选项1:分解和收集
在此嵌套的SQL语句中,我们首先 explode(values),它为值内的每个元素(value)创建一个新行(带有id):
-- In SQL
SELECT id, collect_list(value + 1) AS values
FROM (SELECT id, EXPLODE(values) AS value
FROM table) x
GROUP BY id
尽管collect_list()返回具有重复项的对象列表,但是GROUP BY语句需要随机操作,这意味着重新收集的数组的顺序不一定与原始数组的顺序相同。 由于 values 可以是任意数量的维度(一个非常宽和/或非常长的数组),而且我们正在执行GROUP BY,所以这种方法可能会非常昂贵。
选择2: UDF
和上述例子完成同样的功能,可以创建一个UDF,它遍历values中所有的值并加一:
spark.sql("SELECT id, plusOneInt(values) AS values FROM table").show()
尽管这比使用 explode()和collect_list()更好,因为不会出现任何排序问题,但是序列化和反序列化过程本身可能会很昂贵。 另外,还必须注意,collect_list()可能会使 executor遇到大型数据集的内存不足问题,而使用UDF可以缓解这些问题。
高阶函数
Spark SQL 还有一些将匿名lambda函数作为参数的高阶函数。 下面是一个高阶函数的示例:
-- In SQL
transform(values, value -> lambda expression)
transform() 函数将 array(values) 和匿名函数(lambda表达式)作为输入。 通过将匿名函数应用于每个元素,然后将结果分配给输出数组,该函数可以透明地创建一个新数组(类似于UDF方法,但效率更高)。
举个例子,先来创建一个数据集:
# In Python
from pyspark.sql.types import *
schema = StructType([StructField("celsius", ArrayType(IntegerType()))])
t_list = [[35, 36, 32, 30, 40, 42, 38]], [[31, 32, 34, 55, 56]]
t_c = spark.createDataFrame(t_list, schema)
t_c.createOrReplaceTempView("tC")
# Show the DataFrame
t_c.show()
// In Scala
// Create DataFrame with two rows of two arrays (tempc1, tempc2)
val t1 = Array(35, 36, 32, 30, 40, 42, 38)
val t2 = Array(31, 32, 34, 55, 56)
val tC = Seq(t1, t2).toDF("celsius")
tC.createOrReplaceTempView("tC")
// Show the DataFrame
tC.show()
输出:
+--------------------+
| celsius|
+--------------------+
|[35, 36, 32, 30, ...|
|[31, 32, 34, 55, 56]|
+--------------------+
transform()
// In Scala/Python
// Calculate Fahrenheit from Celsius for an array of temperatures
spark.sql("""
SELECT celsius,
transform(celsius, t -> ((t * 9) div 5) + 32) as fahrenheit
FROM tC
""").show()
输出:
+--------------------+--------------------+
|celsius| fahrenheit|
+--------------------+--------------------+
|[35, 36, 32, 30, ...|[95, 96, 89, 86, ...|
|[31, 32, 34, 55, 56]|[87, 89, 93, 131,...|
+--------------------+--------------------+
filter()
// In Scala/Python
// Filter temperatures > 38C for array of temperatures
spark.sql("""
SELECT celsius,
filter(celsius, t -> t > 38) as high
FROM tC
""").show()
输出:
+--------------------+--------+
|celsius|high|
+--------------------+--------+
|[35, 36, 32, 30, ...|[40, 42]|
|[31, 32, 34, 55, 56]|[55, 56]|
+--------------------+--------+
exists()
// In Scala/Python
// Is there a temperature of 38C in the array of temperatures
spark.sql("""
SELECT celsius,
exists(celsius, t -> t = 38) as threshold
FROM tC
""").show()
输出:
+--------------------+---------+
| celsius| threshold|
+--------------------+---------+
|[35, 36, 32, 30, ...| true|
|[31, 32, 34, 55, 56]| false|
+--------------------+---------+
reduce()
reduce(array
, B, function<B, T, B>, function<B, R>)
reduce()函数通过使用function <B,T,B>将元素合并到缓冲区B中,并在最终缓冲区B 上调用function<B,R>,来实现将数组的元素减少为单个值:
// In Scala/Python
// Calculate average temperature and convert to F
spark.sql("""
SELECT celsius,
reduce(
celsius,
0,
(t, acc) -> t + acc,
acc -> (acc div size(celsius) * 9 div 5) + 32
) as avgFahrenheit
FROM tC
""").show()
输出:
+--------------------+-------------+
| celsius| avgFahrenheit|
+--------------------+-------------+
|[35, 36, 32, 30, ...| 96|
|[31, 32, 34, 55, 56]| 105|
+--------------------+-------------+
DataFrames 和 Spark SQL 的常用操作
Spark SQL的部分功能来自其支持的各种DataFrame操作(也称为无类型数据集操作)。 操作列表非常广泛,包括:
- Aggregate functions
- Collection functions
- Datetime functions
- Math functions
- Miscellaneous functions (混杂)
- Non-aggregate functions
- Sorting functions
- String functions
- UDF functions
- Window functions
在本章中,我们将重点介绍以下常见的关系操作:
- Unions and joins
- Windowing
- Modifications
先准备一些数据:
# In Python
# Set file paths
from pyspark.sql.functions import expr
tripdelaysFilePath = "/databricks-datasets/learning-spark-v2/flights/departuredelays.csv"
airportsnaFilePath = "/databricks-datasets/learning-spark-v2/flights/airport-codes-na.txt"
# Obtain airports data set
airportsna = (spark.read
.format("csv")
.options(header="true", inferSchema="true", sep="\t")
.load(airportsnaFilePath))
airportsna.createOrReplaceTempView("airports_na")
# Obtain departure delays data set
departureDelays = (spark.read
.format("csv")
.options(header="true")
.load(tripdelaysFilePath))
departureDelays = (departureDelays
.withColumn("delay", expr("CAST(delay as INT) as delay"))
.withColumn("distance", expr("CAST(distance as INT) as distance")))
departureDelays.createOrReplaceTempView("departureDelays")
# Create temporary small table
foo = (departureDelays
.filter(expr("""origin == 'SEA' and destination == 'SFO' and
date like '01010%' and delay > 0""")))
foo.createOrReplaceTempView("foo")
数据内容如下:
// Scala/Python
spark.sql("SELECT * FROM airports_na LIMIT 1").show()
+-----------+-----+-------+----+
| City|State|Country|IATA|
+-----------+-----+-------+----+
|Abbotsford| BC|Canada|YXX|
| Aberdeen| SD| USA| ABR|
+-----------+-----+-------+----+
spark.sql("SELECT * FROM departureDelays LIMIT 10").show()
+--------+-----+--------+------+-----------+
| date|delay|distance|origin|destination|
+--------+-----+--------+------+-----------+
|01011245| 6| 602| ABE| ATL|
|01020600| -8| 369| ABE| DTW|
spark.sql("SELECT * FROM foo").show()
+--------+-----+--------+------+-----------+
| date|delay|distance|origin|destination|
+--------+-----+--------+------+-----------+
|01010710| 31| 590| SEA| SFO|
|01010955| 104| 590| SEA| SFO|
|01010730| 5| 590| SEA| SFO|
+--------+-----+--------+------+-----------+
Unions
Apache Spark中的常见模式是将具有相同模式的两个不同的DataFrame联合在一起。 这可以使用union()方法实现:
# In Python
# Union two tables
bar = departureDelays.union(foo)
bar.createOrReplaceTempView("bar")
# Show the union (filtering for SEA and SFO in a specific time range)
bar.filter(expr("""origin == 'SEA' AND destination == 'SFO'
AND date LIKE '01010%' AND delay > 0""")).show()
DataFrame bar 是delays 和 foo的并集。 使用相同的过滤条件在DataFrame栏中显示结果,按预期,我们看到了foo数据的重复:
-- In SQL
spark.sql(""" SELECT *
FROM bar
WHERE origin = 'SEA'
AND destination = 'SFO'
AND date LIKE '01010%'
AND delay > 0
""").show()
+--------+-----+--------+------+-----------+
| date|delay|distance|origin|destination|
+--------+-----+--------+------+-----------+
|01010710| 31| 590| SEA| SFO|
|01010955| 104| 590| SEA| SFO|
|01010730| 5| 590| SEA| SFO|
|01010710| 31| 590| SEA| SFO|
|01010955| 104| 590| SEA| SFO|
|01010730| 5| 590| SEA| SFO|
+--------+-----+--------+------+-----------+
Joins
常见的DataFrame操作是将两个DataFrame(或表)连接在一起。 默认情况下,Spark SQL连接是 inner join,其选项包括:inner, cross, outer, full, full_outer, left, left_outer, right, right_outer, left_semi, 和 left_anti。
// In Scala
foo.join(
airports.as('air),
$"air.IATA" === $"origin"
).select("City", "State", "date", "delay", "distance", "destination").show()
-- In SQL
spark.sql("""
SELECT a.City, a.State, f.date, f.delay, f.distance, f.destination
FROM foo f
JOIN airports_na a
ON a.IATA = f.origin
""").show()
Windowing 窗口函数
窗口函数使用窗口(某个范围)中行的值来返回一组值,通常以另一行的形式返回。 使用窗口函数,可以在一组行上进行操作,同时仍为每个输入行返回一个值。 在本节中,我们将展示如何使用dense_rank()窗口功能;同时,还有很多其他窗口函数:

-- In SQL
DROP TABLE IF EXISTS departureDelaysWindow;
CREATE TABLE departureDelaysWindow AS
SELECT origin, destination, SUM(delay) AS TotalDelays
FROM departureDelays
WHERE origin IN ('SEA', 'SFO', 'JFK')
AND destination IN ('SEA', 'SFO', 'JFK', 'DEN', 'ORD', 'LAX', 'ATL')
GROUP BY origin, destination;
SELECT * FROM departureDelaysWindow
+------+-----------+-----------+
|origin|destination|TotalDelays|
+------+-----------+-----------+
| JFK| ORD| 5608|
| SEA| LAX| 9359|
| JFK| SFO| 35619|
| SFO| ORD| 27412|
| JFK| DEN| 4315|
| SFO| DEN| 18688|
| SFO| SEA| 17080|
| SEA| SFO| 22293|
| JFK| ATL| 12141|
| SFO| ATL| 5091|
| SEA| DEN| 13645|
| SEA| ATL| 4535|
| SEA| ORD| 10041|
| JFK| SEA| 7856|
| JFK| LAX| 35755|
| SFO| JFK| 24100|
| SFO| LAX| 40798|
| SEA| JFK| 4667|
+------+-----------+-----------+
only showing top 10 rows
如果您想为每个这些始发机场找到三个延误最多的目的地怎么办? 您可以通过为每个始发点运行三个不同的查询,然后将结果合并在一起来实现此目的,如下所示:
-- In SQL
SELECT origin, destination, SUM(TotalDelays) AS TotalDelays
FROM departureDelaysWindow
WHERE origin = '[ORIGIN]'
GROUP BY origin, destination
ORDER BY SUM(TotalDelays) DESC
LIMIT 3
这里的 [ORIGIN] 是三个不同的起点:JFK, SEA, SFO.
但是更好的方法是使用诸如dense_rank()之类的窗口函数来执行以下计算:
-- In SQL
spark.sql("""
SELECT origin, destination, TotalDelays, rank
FROM (
SELECT origin, destination, TotalDelays,
dense_rank() OVER (
PARTITION BY origin ORDER BY TotalDelays DESC
) as rank
FROM departureDelaysWindow
) t
WHERE rank <= 3
""").show()
+------+-----------+-----------+----+
|origin|destination|TotalDelays|rank|
+------+-----------+-----------+----+
| SEA| SFO| 22293| 1|
| SEA| DEN| 13645| 2|
| SEA| ORD| 10041| 3|
| SFO| LAX| 40798| 1|
| SFO| ORD| 27412| 2|
| SFO| JFK| 24100| 3|
| JFK| LAX| 35755| 1|
| JFK| SFO| 35619| 2|
| JFK| ATL| 12141| 3|
+------+-----------+-----------+----+
only showing top 10 rows
重要的是要注意,每个窗口分组都需要容纳在一个执行程序中,并且在执行过程中将组成一个分区。 因此,您需要确保查询不受限制(即限制窗口的大小)。
Modifications 修改
另一个常见的操作是对DataFrame进行修改。 尽管DataFrames本身是不可变的,但是您可以通过创建新的,不同的DataFrames(例如具有不同的列)的操作来修改它们。
添加新列
withColumn
删除列
drop
重命名列
withColumnRenamed
旋转
处理数据时,有时您需要将列换为行,即,旋转数据。 让我们获取一些数据来证明这个概念:
-- In SQL
SELECT destination, CAST(SUBSTRING(date, 0, 2) AS int) AS month, delay
FROM departureDelays
WHERE origin = 'SEA'
+-----------+-----+-----+
|destination|month|delay|
+-----------+-----+-----+
| ORD| 1| 92|
| JFK| 1| -7|
| DFW| 1| -5|
| MIA| 1| -3|
| DFW| 1| -3|
| DFW|1|1|
| ORD| 1| -10|
| DFW| 1| -6|
| DFW| 1| -2|
| ORD| 1| -3|
+-----------+-----+-----+
only showing top 10 rows
通过 pivoting,您可以在month列中放置名称(而不是分别显示1月和2月的1和2),也可以按destination 和 month对 delay 执行汇总计算(在这种情况下为平均值和最大值):
-- In SQL
SELECT * FROM (
SELECT destination, CAST(SUBSTRING(date, 0, 2) AS int) AS month, delay
FROM departureDelays WHERE origin = 'SEA'
)
PIVOT (
CAST(AVG(delay) AS DECIMAL(4, 2)) AS AvgDelay, MAX(delay) AS MaxDelay
FOR month IN (1 JAN, 2 FEB)
)
ORDER BY destination
