进入第七章:《Spark 应用的优化与调整》。
优化和调整Spark以提高效率
查看和设置 Spark 的配置
通常有三种方式来读取和设置Spark 属性。
第一种是通过配置文件。 在 $SPARK_HOME 目录下,有许多配置文件:conf/spark-defaults.conf.template, conf/ log4j.properties.template, 和 conf/spark-env.sh.template。 修改其中某些值,并保存为不带 template 后缀的新文件。
第二种是直接在使用 spark-submit 命令行提交应用时,使用 --conf 指:
spark-submit \
--conf spark.sql.shuffle.partitions=5 \
--conf "spark.executor.memory=2g" \
--class main.scala.chapter7.SparkConfig_7_1 jars/main-scala-chapter7_2.12-1.0.jar
或者在代码里:
// In Scala
import org.apache.spark.sql.SparkSession
def printConfigs(session: SparkSession) = {
// Get conf
val mconf = session.conf.getAll
// Print them
for (k <- mconf.keySet) {
println(s"${k} -> ${mconf(k)}\n")
}
}
def main(args: Array[String]) {
// Create a session
val spark = SparkSession.builder
.config("spark.sql.shuffle.partitions", 5)
.config("spark.executor.memory", "2g")
.master("local[*]")
.appName("SparkConfig")
.getOrCreate()
printConfigs(spark)
spark.conf.set("spark.sql.shuffle.partitions",
spark.sparkContext.defaultParallelism)
println(" ****** Setting Shuffle Partitions to Default Parallelism")
printConfigs(spark)
}
spark.driver.host -> 10.8.154.34
spark.driver.port -> 55243
spark.app.name -> SparkConfig
spark.executor.id -> driver
spark.master -> local[*]
spark.executor.memory -> 2g
spark.app.id -> local-1580162894307
spark.sql.shuffle.partitions -> 5
第三种是通过Spark shell 的编程接口。与Spark中的所有其他内容一样,API是交互的主要方法。 通过SparkSession对象,您可以访问大多数Spark配置设置。
scala> val mconf = spark.conf.getAll
...
scala> for (k <- mconf.keySet) { println(s"${k} -> ${mconf(k)}\n") }
spark.driver.host -> 10.13.200.101
spark.driver.port -> 65204
spark.repl.class.uri -> spark://10.13.200.101:65204/classes
...
或者Spark SQL:
// In Scala
spark.sql("SET -v").select("key", "value").show(5, false)
# In Python
spark.sql("SET -v").select("key", "value").show(n=5, truncate=False)
或者你也可以通过Spark UI 里的 Environment 页来看。
在修改配置之前,可以使用 spark.conf.isModifiable("*<config_name>*") 来查看该配置是否可以更改。
虽然有很多种方式来设置配置。但是它们也是有读取顺序的,spark-defaults.conf 首先被读出来,然后是 spark-submit 的命令行,最后是 SparkSession。所有这些属性将被合并,并且所有重复属性会按优先顺序进行去重。 比如,在命令行中提供的值将取代配置文件中的设置,前提是它们不会在应用程序本身中被覆盖。
调整或提供正确的配置有助于提高性能,正如您将在下一部分中看到的那样。 这里的建议来自社区中从业人员的观察,并且侧重于如何最大程度地利用Spark的群集资源以适应大规模工作负载。
扩展Spark以处理大工作量
大型Spark工作负载通常是批处理工作,有些是每晚运行的,有些则是每天定期执行的。 无论哪种情况,这些作业都可能处理数十TB字节的数据或更多。 为了避免由于资源匮乏或性能逐步下降而导致作业失败,可以启用或更改一些Spark配置。 这些配置影响三个Spark组件:Spark driver,executor 和在 executor 上运行的 shuffle 服务。
Spark driver 的职责是与集群管理器协调,以在集群中启动executor,并在其上安排Spark任务。 对于大工作量,您可能有数百个任务。 本节介绍了一些可以调整或启用的配置,以优化资源利用率、任务并行度,来避免出现大任务的瓶颈。
静态与动态资源分配
如前所述,当您将计算资源指定为spark-submit的命令行参数时,您便设置了上限。 这意味着,如果由于工作负载超出预期而导致以后在驱动程序中排队任务时需要更多资源,Spark将无法容纳或分配额外的资源。
相反,如果您使用Spark的动态资源分配配置( dynamic resource allocation configuration),则Spark driver 会随着大型工作负载的需求不断增加和减少,可以请求更多或更少的计算资源。 在工作负载是动态的情况下(即,它们对计算能力的需求各不相同),使用动态分配有助于适应突然出现的峰值。
一种可能有用的用例是streaming,其中数据流量可能不均匀。 另一个是按需数据分析,在高峰时段您可能需要大量SQL查询。 启用动态资源分配可以使Spark更好地利用资源,在不使用执行器时释放它们,并在需要时获取新的执行器。
要启用和配置动态分配,可以使用如下设置。 注意这里的数字是任意的; 适当的设置将取决于您的工作负载的性质,应进行相应的调整。 其中一些配置无法在Spark REPL内设置,因此您必须以编程方式进行设置:
spark.dynamicAllocation.enabled true spark.dynamicAllocation.minExecutors 2 spark.dynamicAllocation.schedulerBacklogTimeout 1m spark.dynamicAllocation.maxExecutors 20 spark.dynamicAllocation.executorIdleTimeout 2min
默认情况下,spark.dynamicAllocation.enabled设置为 false。 当使用此处显示的设置启用时,Spark驱动程序将要求集群管理器创建两个执行程序作为最低启动条件(spark.dynamicAllocation.minExecutor)。 随着任务队列积压的增加,每次超过积压超时(spark.dynamicAllocation.schedulerBacklogTimeout)都将请求新的执行者。 在这种情况下,每当有未计划的待处理任务超过1分钟时,驱动程序将请求启动新的执行程序以计划积压的任务,最多20个(spark.dynamicAllocation.maxExecutor)。 相比之下,如果执行者完成任务并空闲2分钟(spark.dynamicAllocation.executorIdleTimeout),Spark驱动程序将终止它。
配置 Spark executors’ memory 和 shuffle service
仅启用动态资源分配是不够的。 您还必须了解Spark如何布置和使用执行程序内存,以便使执行程序不会因内存不足而受JVM垃圾回收的困扰。
每个执行器可用的内存量由spark.executor.memory控制。 如图所示,它分为三个部分:执行内存,存储内存和保留内存。 在保留300 MB的预留内存之后,默认内存划分为60%的执行内存和40%的存储内存,以防止OOM错误。 Spark文档建议此方法适用于大多数情况,但是您可以调整希望哪一部分用作基准的spark.executor.memory比例。 当不使用存储内存时,Spark可以获取它以供执行内存用于执行目的,反之亦然。
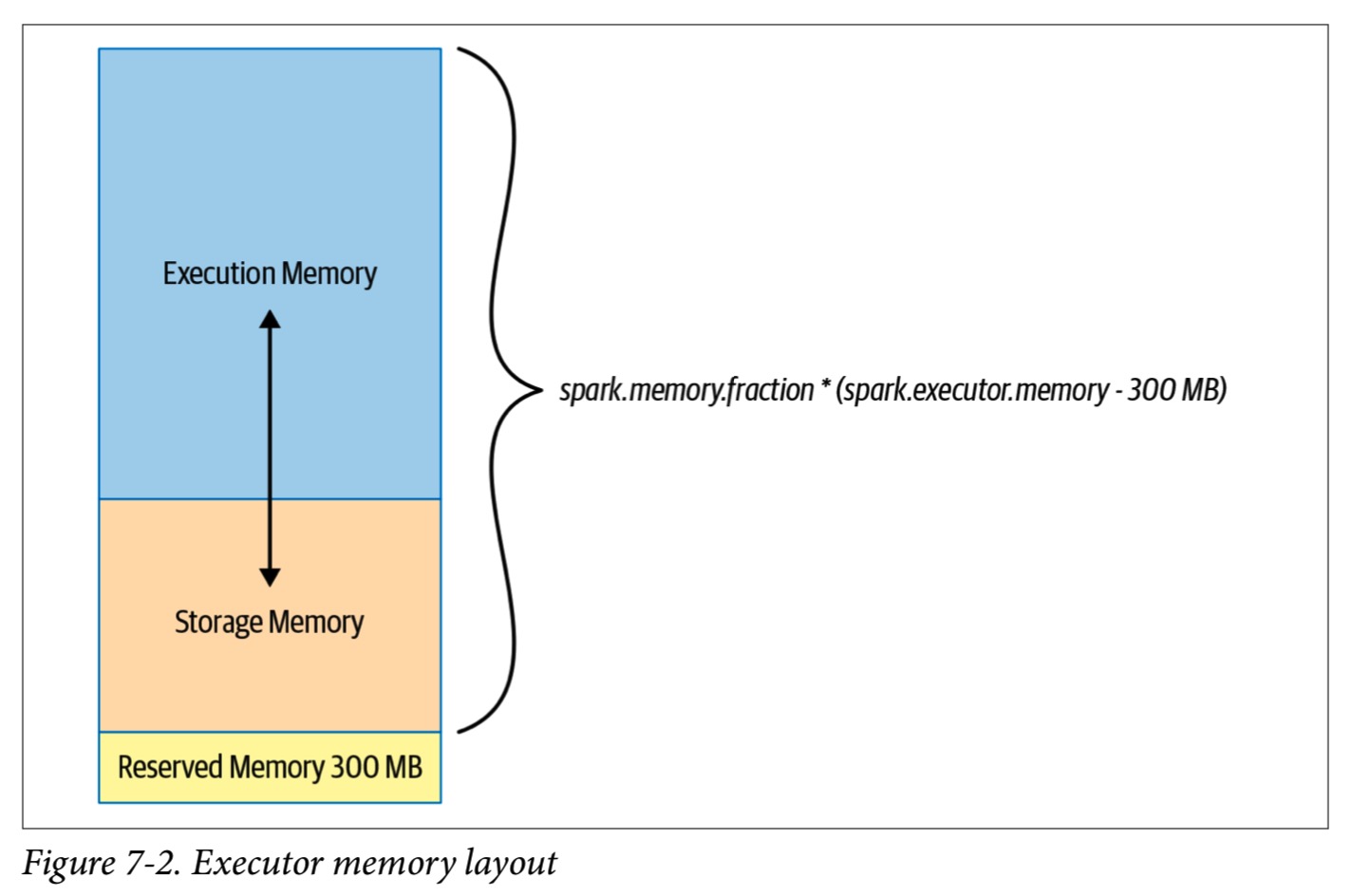
执行内存用于Spark shuffles,joins, sorts, 和 aggregations。 由于不同的查询可能需要不同的内存量,因此专用于此的可用内存的fraction(默认情况下,spark.memory.fraction为0.6)可能很难最优,但是它很易调整。另外,存储内存主要用于缓存从DataFrame派生的用户数据结构和分区。
在 map 和 shuffle 操作期间,Spark会写入和读取本地磁盘的shuffle文件,因此 I/O 活动繁重。 这可能会导致瓶颈,因为对于大型Spark作业,默认配置并不理想。 在Spark作业的此阶段,知道要进行哪些配置调整可以减轻这种风险。
我们捕获了一些建议的配置进行调整,以使这些操作期间的map、spill、merge过程,不会因效率低下的I / O所困扰,并使这些操作能够在将最终的shuffle分区写入磁盘之前使用缓冲内存。 调整在每个executor上运行的shuffle服务还可以帮助提高大型Spark工作负载的整体性能。
| 配置 | 默认值、推荐值及介绍 |
|---|---|
| spark.driver.memory | 默认值为1g(1 GB)。 这是分配给Spark驱动程序以从执行程序接收数据的内存量。 这通常在spark-submit 时使用--driver-memory进行更改。仅当您希望驱动程序从诸如 collect()之类的操作中接收到大量数据,或者驱动程序内存用完时,才更改此设置。 |
| spark.shuffle.file.buffer | 默认值为32 KB。 推荐为1 MB。 这允许Spark在将最终map结果写入磁盘之前做更多缓冲。 |
| spark.file.transferTo | 默认为true。 将其设置为false将强制Spark在最终写入磁盘之前使用文件缓冲区传输文件; 这将减少I / O活动。 |
| spark.shuffle.unsafe.file.output.buffer | 默认值为32 KB。 这可以控制在shuffle操作期间合并文件时可能的缓冲量。 通常,较大的值(例如1 MB)更适合较大的工作负载,而默认值可以适用于较小的工作负载。 |
| spark.io.compression.lz4.blockSize | 默认值为32 KB。 增加到512 KB。 您可以通过增加块的压缩大小来减少shuffle文件的大小。 |
| spark.shuffle.service.index.cache.size | 默认值为100m。 缓存条目限制为指定的内存占用空间(以字节为单位)。 |
| spark.shuffle.registration.timeout | 默认值为5000毫秒。 增加到120000 ms。 |
| spark.shuffle.registration.maxAttempts | 默认值为3。如果需要,请增加到5。 |
最大化Spark的并行度
Spark的大部分效率归功于其能够大规模并行运行多个任务的能力。 要了解如何最大程度地提高并行度(即尽可能并行地读取和处理数据),您必须研究Spark如何将数据从存储中读取到内存中以及分区对Spark意味着什么。
用数据管理的话来说,分区是一种将数据安排到多个可配置可读的数据子集中的方式。 这些数据子集可以在一个进程中由多个线程独立或并行读取或处理(如有必要)。 这种独立性很重要,因为它允许大规模并行处理数据。
Spark在并行处理任务方面非常高效。 对于大规模工作负载,Spark作业将具有多个阶段(stage),并且在每个阶段中将有许多任务(task)。 Spark最多会为每个内核(core)的每个任务(task)计划一个线程(thread),并且每个任务将处理一个不同的分区。 为了优化资源利用率并最大程度地提高并行度,理想的情况是分区至少与执行程序上的内核一样多。 如果每个执行程序上的分区数量多于核心数量,则所有核心都将保持繁忙状态。 您可以将分区视为并行性的基本单位:在单个内核上运行的单个线程可以在单个分区上工作。

如何创建分区。 如前所述,Spark的任务是处理从磁盘读入内存的分区的数据。 磁盘上的数据按块或连续的文件块进行布局,具体取决于存储。 默认情况下,数据存储上的文件块大小范围从64 MB到128 MB。 例如,在HDFS和S3上,默认大小为128 MB(这是可配置的)。 这些块的连续集合构成一个分区。
Spark中分区的大小由spark.sql.files.maxPartitionBytes决定。 默认值为128 MB。 您可以减小大小,但这可能会导致所谓的“小文件问题”,即许多小分区文件,由于文件系统操作(例如,打开,关闭和列出目录)而引入了过多的磁盘I / O和性能下降,这在分布式系统上会很慢。
当您显式使用DataFrame API的某些方法时,也会创建分区。 例如,在创建大型DataFrame或从磁盘读取大型文件时,您可以显式指示Spark创建一定数量的分区:
// In Scala
val ds = spark.read.textFile("../README.md").repartition(16)
ds: org.apache.spark.sql.Dataset[String] = [value: string]
ds.rdd.getNumPartitions
res5: Int = 16
val numDF = spark.range(1000L * 1000 * 1000).repartition(16)
numDF.rdd.getNumPartitions
numDF: org.apache.spark.sql.Dataset[Long] = [id: bigint]
res12: Int = 16
最后,在shuffle阶段创建shuffle分区。 默认情况下,spark.sql.shuffle.partitions中的shuffle分区数设置为200。 您可以根据拥有的数据集的大小来调整此数字,以减少通过网络发送给执行者任务的小分区的数量。
在诸如groupBy()或join()之类的操作(也称为宽转换)期间创建的 shuffle 分区会占用网络和磁盘I / O资源。 在执行这些操作期间,shuffle 会将结果溢出到spark.local.directory指定的位置的executor 的本地磁盘上。 拥有高性能的SSD磁盘来执行此操作将提高性能。
对于shuffle阶段设置的shuffle分区数量没有神奇的公式。 该数目可能会因您的使用情况,数据集,内核数和可用的执行器内存量而异,这是一种反复试验的方法。
除了为大型工作负载扩展Spark外,要提高性能,您还需要考虑缓存或持久存储经常访问的DataFrames或表。
缓存和持久化数据
缓存和持久性有什么区别? 在Spark中,它们是同义的。 两个API调用cache()和persist()提供了这些功能。 后者可以更好地控制数据的存储方式和位置,包括在内存和磁盘中(序列化和非序列化)。 两者都有助于提高频繁访问的DataFrame或表的性能。
DataFrame.cache()
cache() 将在内存允许的范围,在跨Spark executor 的内存中读取的所有分区。 虽然DataFrame可能会被部分缓存,但partition无法被部分缓存(例如,如果您有8个分区,但内存中只能容纳4.5个分区,则仅会缓存4个)。 但是,如果不是所有分区都被缓存,则当您想再次访问数据时,必须重新计算未缓存的分区,这会降低Spark作业的速度。
让我们看一个示例,该示例说明在访问DataFrame时缓存大型DataFrame如何提高性能:
// In Scala
// Create a DataFrame with 10M records
val df = spark.range(1 * 10000000).toDF("id").withColumn("square", $"id" * $"id") df.cache() // Cache the data
df.count() // Materialize the cache
res3: Long = 10000000
Command took 5.11 seconds
df.count() // Now get it from the cache
res4: Long = 10000000
Command took 0.44 seconds
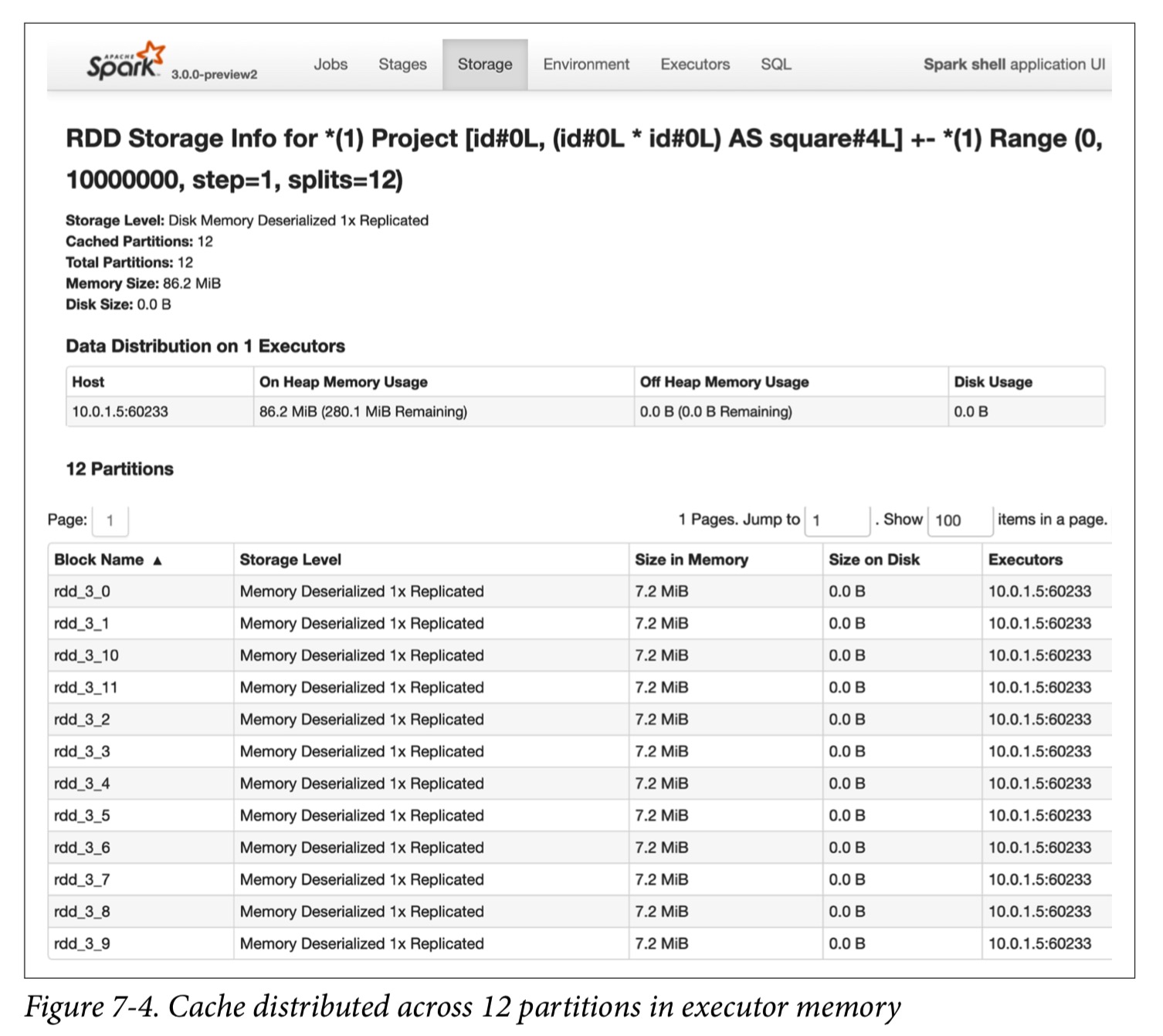
第一个count()实现了缓存,而第二个 count()实现了缓存,因此对该数据集的访问时间快了将近12倍。
如下图所示,观察DataFrame如何跨本地主机上的一个执行器存储,我们可以看到它们都存在内存。
DataFrame.persist()
persist(StorageLevel.LEVEL)是微妙的,可控制如何通过StorageLevel缓存数据。 下表总结了不同的存储级别。 磁盘上的数据始终使用Java或Kryo序列化进行序列化。
| StorageLevel | Description |
|---|---|
| MEMORY_ONLY | 数据直接作为对象存储,并且仅存储在内存中。 |
| MEMORY_ONLY_SER | 数据被序列化为紧凑字节数组表示形式,并且仅存储在内存中。 要使用它,必须将其反序列化,但要付出一定的代价。 |
| MEMORY_AND_DISK | 数据直接作为对象存储在内存中,但是如果没有足够的内存,其余数据将被序列化并存储在磁盘上。 |
| DISK_ONLY | 数据被序列化并存储在磁盘上。 |
| OFF_HEAP | 数据存储在堆外。 |
| MEMORY_AND_DISK_SER | 与MEMORY_AND_DISK类似,但是数据存储在内存中时会被序列化。 (数据总是存储在磁盘上时已序列化。) |
每个StorageLevel(OFF_HEAP除外)都有一个等效的LEVEL_NAME_2,这意味着在两个不同的Spark执行程序(MEMORY_ONLY_2,MEMORY_AND_DISK_SER_2等)上复制两次。虽然此选项很昂贵,但它允许在两个地方进行数据本地化,从而提供容错能力并为Spark提供计划在数据副本本地执行任务的选项。
让我们看与上一节相同的示例,但是使用persist方法:
// In Scala
import org.apache.spark.storage.StorageLevel
// Create a DataFrame with 10M records
val df = spark.range(1 * 10000000).toDF("id").withColumn("square", $"id" * $"id") df.persist(StorageLevel.DISK_ONLY) // Serialize the data and cache it on disk
df.count() // Materialize the cache
res2: Long = 10000000
Command took 2.08 seconds
df.count() // Now get it from the cache res3: Long = 10000000
Command took 0.38 seconds
要取消持久化缓存的数据,只需调用DataFrame.unpersist()。
什么时候Cache和Persist
缓存的常见用例是需要重复访问大数据集以进行查询或转换的方案。 一些示例包括:
- 迭代机器学习train中常用的DataFrames
- 经常访问的DataFrame,以在ETL期间进行频繁的转换或建立数据管道
什么时候不要 Cache和Persist
并非所有用例都表明需要缓存。 某些情况可能无法保证您使用DataFrames,其中包括:
- 太大而无法容纳在内存中的DataFrame
- 在DataFrame上进行廉价转换,而无需考虑使用它的大小
通常,应谨慎使用内存缓存,因为它可能会导致序列化和反序列化中的资源成本,具体取决于所使用的StorageLevel。 接下来,我们将重点转移到几个常见的Spark连接操作上,这些操作会触发昂贵的数据移动,需要来自集群的计算和网络资源,以及如何通过组织数据来减轻这种移动。
Spark Join 家族
Join 操作是大数据分析中一种常见的转换类型,其中两个表或DataFrames形式的数据集通过一个通用的匹配键进行合并。 与关系数据库类似,Spark DataFrame和Dataset API以及Spark SQL提供了一系列联接转换:inner joins, outer joins, left joins, right joins, etc。所有这些操作都触发了跨Spark执行程序的大量数据移动。
这些转换的核心是Spark该如何计算:生成什么数据、哪些keys和相关数据应该写入磁盘,以及如何将这些 key 和 data 作为groupBy,join,agg , sortBy, reduceByKey等操作的一部分传输到节点。 这种运动通常称为 shuffle。
Spark具有五种不同的联接策略,通过它可以在执行程序之间交换,移动,排序,分组和合并数据:
- broadcast hash join(BHJ)
- shuffle hash join(SHJ)
- shuffle sort merge join(SMJ)
- broadcast nested loop join(BNLJ)
- shuffle-and- replicated nested loop join(又称为 Cartesian product join)
在这里,我们仅关注其中的两个(BHJ和SMJ),因为它们是您会遇到的最常见的情况。
Broadcast Hash Join
也称为 map-side-only join,当需要在某些条件或列上联接两个数据集(其中一个很小,可以放进driver和executor的内存,和另一个足够大以至于可以避免移动的数据集)结合使用时,将使用 BHJ。 使用Spark broadcast variable,driver 将较小的数据集分发给所有Spark执行程序,如下图所示,随后将其与每个执行程序上的较大数据集合并。 这种策略避免了大量数据交换。
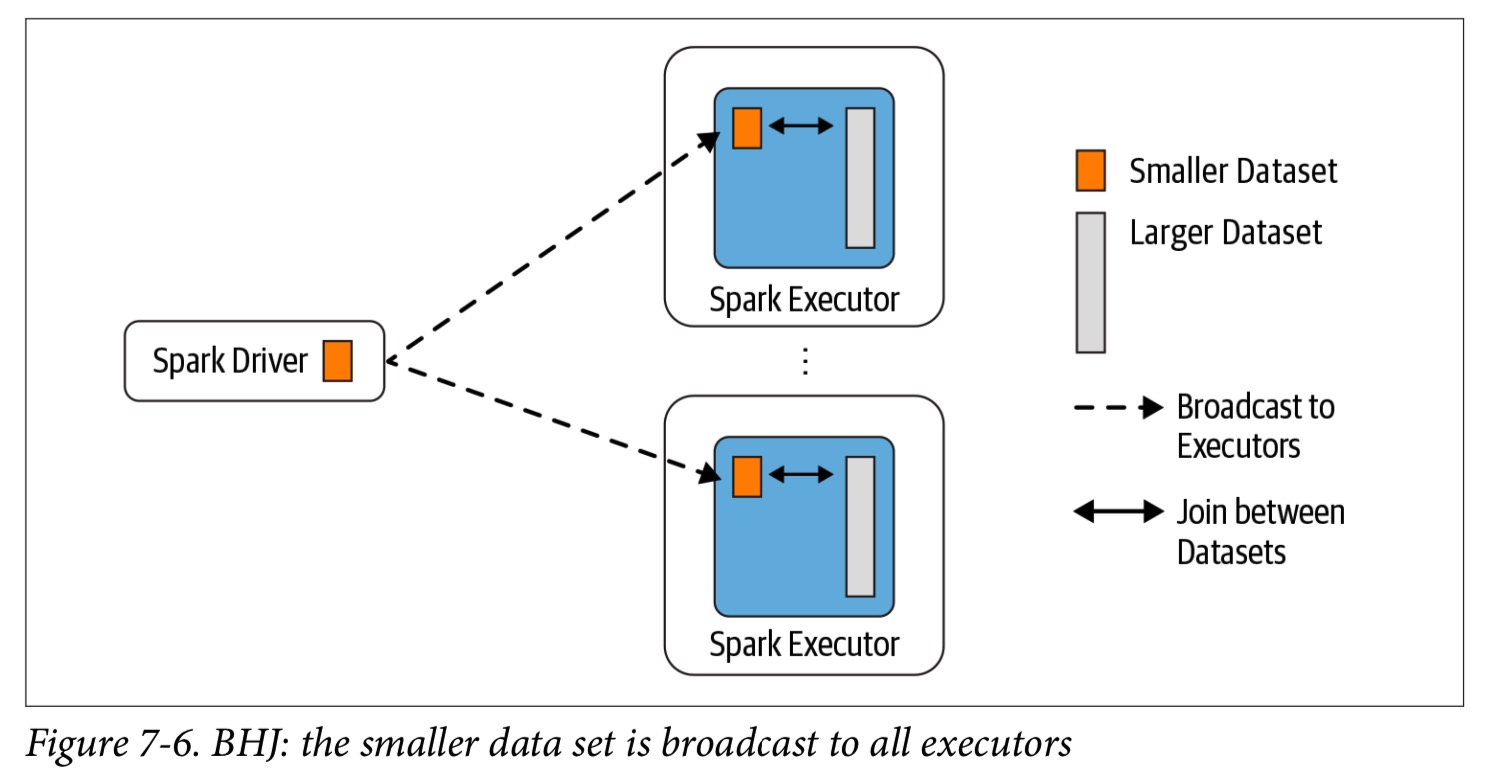
默认情况下,如果较小的数据集小于10 MB,Spark将使用 BHJ。 此配置在spark.sql.autoBroadcastJoinThreshold中设置。 您可以根据每个执行器和驱动程序中的内存量来减小或增大大小。 如果您确信有足够的内存,则可以对大于10 MB(甚至最大100 MB)的DataFrame使用广播联接。
一个常见的用例是,当您在两个 dataframe 之间拥有一组通用的键时,其中一个键的信息少于另一个,并且您需要两者的合并视图。 例如,考虑一个简单的情况,您有一个来自世界各地的足球运动员的大数据集,playersDF,和一个他们所服务的足球俱乐部的小数据集,clubsDF,并且希望通过一个通用key 来 join 它们:
// In Scala
import org.apache.spark.sql.functions.broadcast
val joinedDF = playersDF.join(broadcast(clubsDF), "key1 === key2")
在此代码中,我们强制Spark进行广播连接,但是默认情况下,如果较小数据集的大小小于spark.sql.autoBroadcastJoinThreshold,它就会使用 BHJ。
BHJ是Spark提供的最简单,最快的联接,因为它不涉及任何 shuffle。broadcast后,所有数据都可以在本地executor使用。 您只需要确保Spark驱动程序和执行程序侧都具有足够的内存,即可将较小的数据集保存在内存中。
在操作之后的任何时间,您都可以通过执行以下操作在物理计划中查看执行了哪些联接操作:
joinedDF.explain(mode)
在 Spark 3.0 中,你可以使用 joinedDF.explain('mode') 来展示一个可读的输出。mode 包括 simple、extended、codegen、cost 和 formatted。
什么时候用BHJ
在以下条件下使用这种类型的联接以获取最大利益:
- 当较小和较大数据集中的每个键通过Spark散列到同一分区时
- 当一个数据集比另一个数据集小得多时(并且在默认配置10 MB内,如果有足够的内存,可以设置的更大)
- 当您只想执行等值联接时,而不需要根据匹配的key来进行排序两个数据集
- 当您不必担心过多的网络带宽使用或OOM错误时,因为较小的数据集将广播给所有Spark执行者
在spark.sql.autoBroadcastJoinThreshold中指定值 -1将使Spark始终使用 SMJ (sort merge join)。
Shuffle Sort Merge Join
sort-merge 算法是一个用来合并两个大的数据集高效的方式。它会让两个数据集通过共有的key来进行排序、去重,并且会将拥用相同 hash key的数据放到同一个executor上。很显然这会产生executor之间数据的移动。
从名字也可以看出,它分为两个阶段:sort ,然后 merge。排序阶段按所需的join key对每个数据集进行排序; 合并阶段从每个数据集中迭代行中的每个键,如果两个键匹配,则合并行。
默认情况下,通过spark.sql.join.preferSortMergeJoin启用SortMergeJoin。
看下面的例子:获取两个具有一百万条记录的大型 dataframe ,并将它们连接到两个公用键uid == users_id上。
// In Scala
import scala.util.Random
// Show preference over other joins for large data sets
// Disable broadcast join
// Generate data
...
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", "-1")
// Generate some sample data for two data sets
var states = scala.collection.mutable.Map[Int, String]()
var items = scala.collection.mutable.Map[Int, String]()
val rnd = new scala.util.Random(42)
// Initialize states and items purchased
states += (0 -> "AZ", 1 -> "CO", 2-> "CA", 3-> "TX", 4 -> "NY", 5-> "MI")
items += (0 -> "SKU-0", 1 -> "SKU-1", 2-> "SKU-2", 3-> "SKU-3", 4 -> "SKU-4",
5-> "SKU-5")
// Create DataFrames
val usersDF = (0 to 1000000)
.map(id => (id, s"user_${id}", s"user_${id}@databricks.com", states(rnd.nextInt(5))))
.toDF("uid", "login", "email", "user_state")
val ordersDF = (0 to 1000000)
.map(r => (r, r, rnd.nextInt(10000), 10 * r* 0.2d, states(rnd.nextInt(5)), items(rnd.nextInt(5))))
.toDF("transaction_id", "quantity", "users_id", "amount", "state", "items")
// Do the join
val usersOrdersDF = ordersDF.join(usersDF, $"users_id" === $"uid") // Show the joined results
usersOrdersDF.show(false)
+--------------+--------+--------+--------+-----+-----+---+---+----------+ |transaction_id|quantity|users_id|amount |state|items|uid|...|user_state|
+--------------+--------+--------+--------+-----+-----+---+---+----------+
|3916 |3916 |148 |7832.0 |CA |SKU-1|148|...|CO |
|36384 |36384 |148 |72768.0 |NY |SKU-2|148|...|CO |
检查最终的执行计划,可以看到Spark执行了 SortMergeJoin 来join两个dataframe。 Exchange 操作是将每个executor上 map的结果进行shuffle的动作。
usersOrdersDF.explain()
== Physical Plan ==
InMemoryTableScan [transaction_id#40, quantity#41, users_id#42, amount#43,
state#44, items#45, uid#13, login#14, email#15, user_state#16]
+- InMemoryRelation [transaction_id#40, quantity#41, users_id#42, amount#43,
state#44, items#45, uid#13, login#14, email#15, user_state#16],
StorageLevel(disk, memory, deserialized, 1 replicas)
+- *(3) SortMergeJoin [users_id#42], [uid#13], Inner
:- *(1) Sort [users_id#42 ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(users_id#42, 16), true, [id=#56]
: +- LocalTableScan [transaction_id#40, quantity#41, users_id#42, amount#43, state#44, items#45]
+- *(2) Sort [uid#13 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(uid#13, 16), true, [id=#57]
+- LocalTableScan [uid#13, login#14, email#15, user_state#16]
此外,Spark UI显示了整个作业的三个阶段:交换和排序操作发生在最后一个阶段,然后合并结果。 Exchange成本很高,并且需要在执行者之间通过网络对分区进行shuffle。
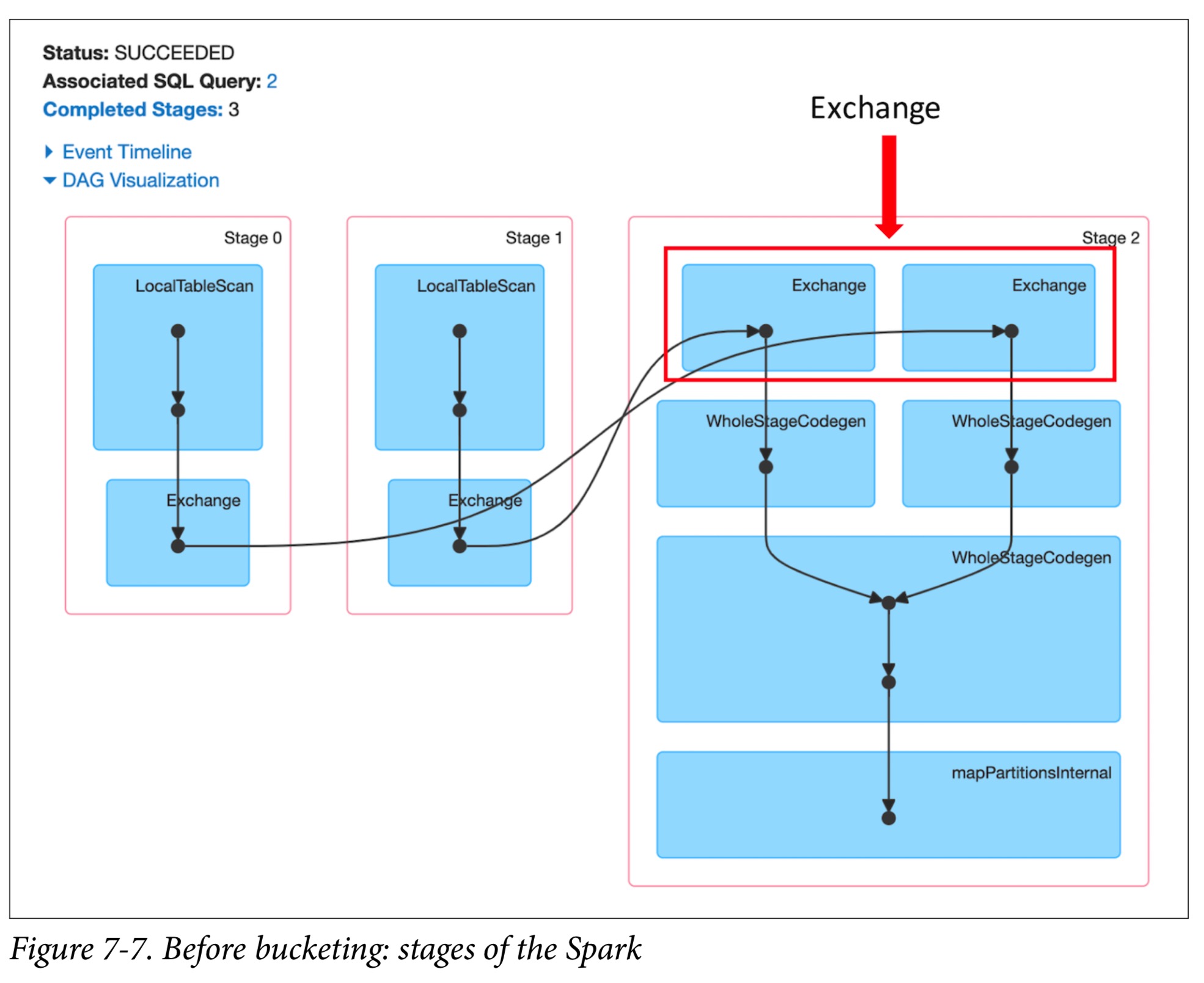
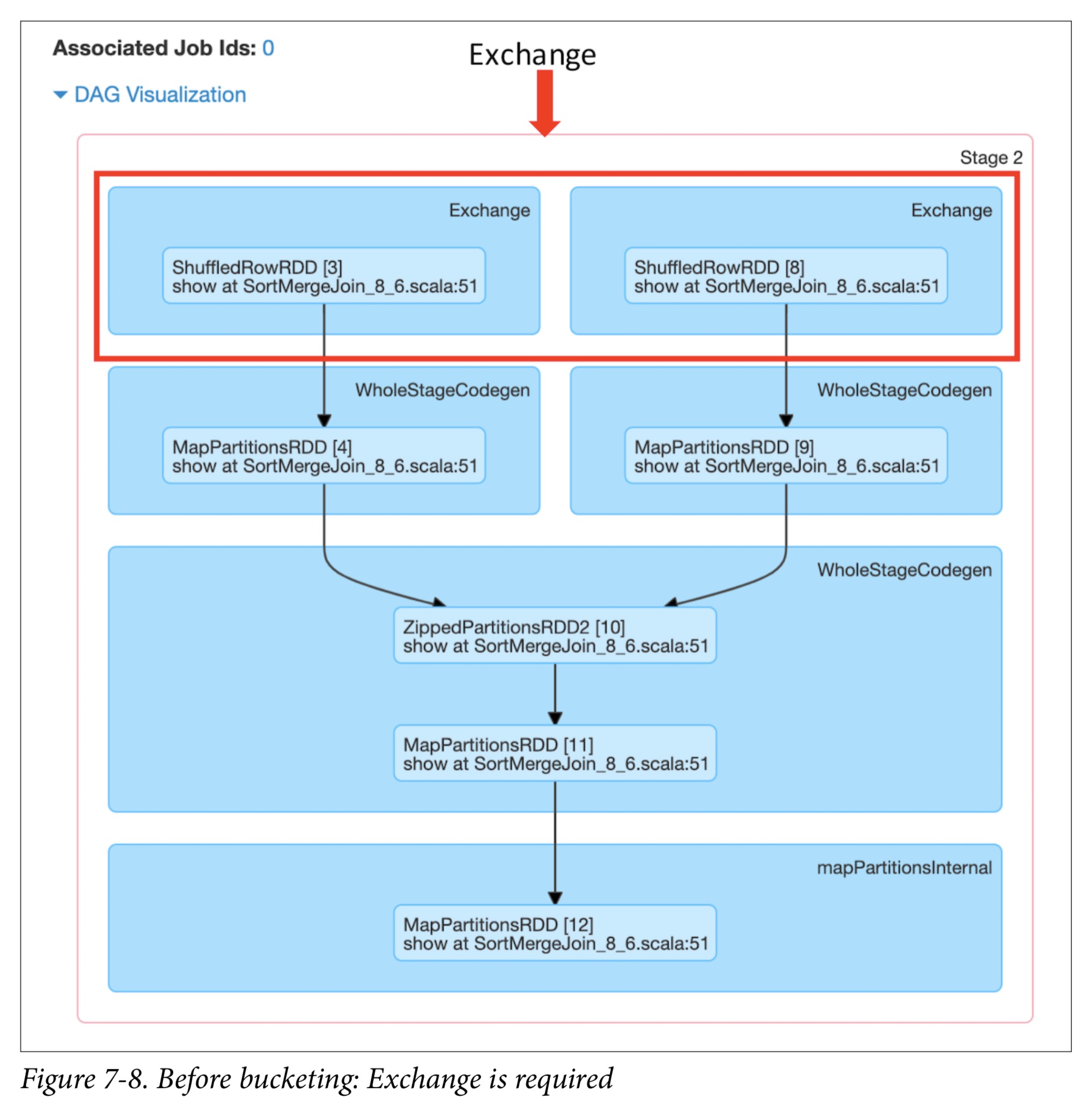
优化 shuffle sort merge join
如果我们提前为那些执行频繁等值连接的连接 key 或列创建分区存储桶,则可以从该执行计划中消除“Exchange”步骤。 也就是说,我们可以创建大量的存储桶来存储特定的已排序列(每个存储桶一个 key)。 通过这种方式对数据进行预排序和重组可以提高性能,因为它使我们可以跳过昂贵的Exchange操作,直接进入WholeStageCodegen。
// In Scala
import org.apache.spark.sql.functions._
import org.apache.spark.sql.SaveMode
// Save as managed tables by bucketing them in Parquet format
usersDF.orderBy(asc("uid"))
.write.format("parquet")
.bucketBy(8, "uid")
.mode(SaveMode.OverWrite)
.saveAsTable("UsersTbl")
ordersDF.orderBy(asc("users_id"))
.write.format("parquet")
.bucketBy(8, "users_id")
.mode(SaveMode.OverWrite)
.saveAsTable("OrdersTbl")
// Cache the tables
spark.sql("CACHE TABLE UsersTbl")
spark.sql("CACHE TABLE OrdersTbl")
// Read them back in
val usersBucketDF = spark.table("UsersTbl")
val ordersBucketDF = spark.table("OrdersTbl")
// Do the join and show the results
val joinUsersOrdersBucketDF = ordersBucketDF
.join(usersBucketDF, $"users_id" === $"uid")
joinUsersOrdersBucketDF.show(false)
与bucket之前的物理计划相比,该物理计划还显示未执行任何交换:
== Physical Plan ==
*(3) SortMergeJoin [users_id#165], [uid#62], Inner
:- *(1) Sort [users_id#165 ASC NULLS FIRST], false, 0
: +- *(1) Filter isnotnull(users_id#165)
: +- Scan In-memory table `OrdersTbl` [transaction_id#163, quantity#164,
users_id#165, amount#166, state#167, items#168], [isnotnull(users_id#165)]
: +- InMemoryRelation [transaction_id#163, quantity#164, users_id#165,
amount#166, state#167, items#168], StorageLevel(disk, memory, deserialized, 1
replicas)
: +- *(1) ColumnarToRow
: +- FileScan parquet
...
什么时候使用 shuffle sort merge join
在以下条件下使用这种类型的联接以获取最大利益:
- 当两个大型数据集中的每个键可以排序并通过Spark散列到同一分区时
- 当您只想执行等值联接以根据匹配的排序键组合两个数据集时
- 当您要防止进行Exchange和Sort操作以避免在网络上大型shuffle时
到目前为止,我们已经介绍了与调整和优化Spark有关的操作方面,以及Spark如何在两次常见的联接操作期间交换数据。 我们还演示了如何通过使用存储桶来避免大量数据交换来提高随机排序合并合并连接操作的性能。