今天接手一个任务,心血来潮用Spark跑一下。 第一次任务花费时间9.6 min,最终调优结果为1.9 min,提升约80%。 还是很有成效的,所以记录一下过程,以便以后参考。
背景
现有集群大小:23台机器,单核CPU、7.5G内存。
输入文件 Size / Records: 1186.5 MB / 38890711
处理逻辑: 首先根据输入文件的某一列field,进行分组,并把组中成员当作一个家族,然后根据5种输出条件,对家族中成员的所属国家country情况进行判别,然后输出到不同的目录下。
准备工作
1. Web UI
调优第一步,就是要有任务运行情况的详细记录。不然也是“巧妇难为无米之炊”。
根据官方文档描述, Spark 提供了web UI来帮助我们分析 application 的运行情况。
本地模式下,默认启动sc时,就会启动一个server来展示Web UI。但是它只能当 application 在运行时有效。 application 一旦结束, Web UI也会关闭。 所以如果我们想要后续分析某个 application, 只需要在运行它时,确认spark.eventLog.enabled 为ture,spark就会记录这个 application 运行情况。
2. Spark 基本概念
首先要清楚spark中的几个概念,如application、job、stage、executor、task。对它们的了解,会有助于下面的工作。
Application
我们使用 spark-submit 提交的就是一个 application, 一个 application 可以有很多job。
Job
当在代码中对 RDD 进行 action操作时,就会产生一个Job。 如果不了解什么是RDD的action,可以看这里.
Stage
每一个Job 又会根据 shuffle 操作,分为多个stage。
Task
一个stage会根据RDD的分区数,分为多个task。
executor
这个可以参考Yarn中的executor概念。简单来说,就是一个task 节点上,可以运行多个executor,一个executor上可以运行多个task。
调优
1. 第一次运行
在第一次运行结束后,查看Web UI,如下:
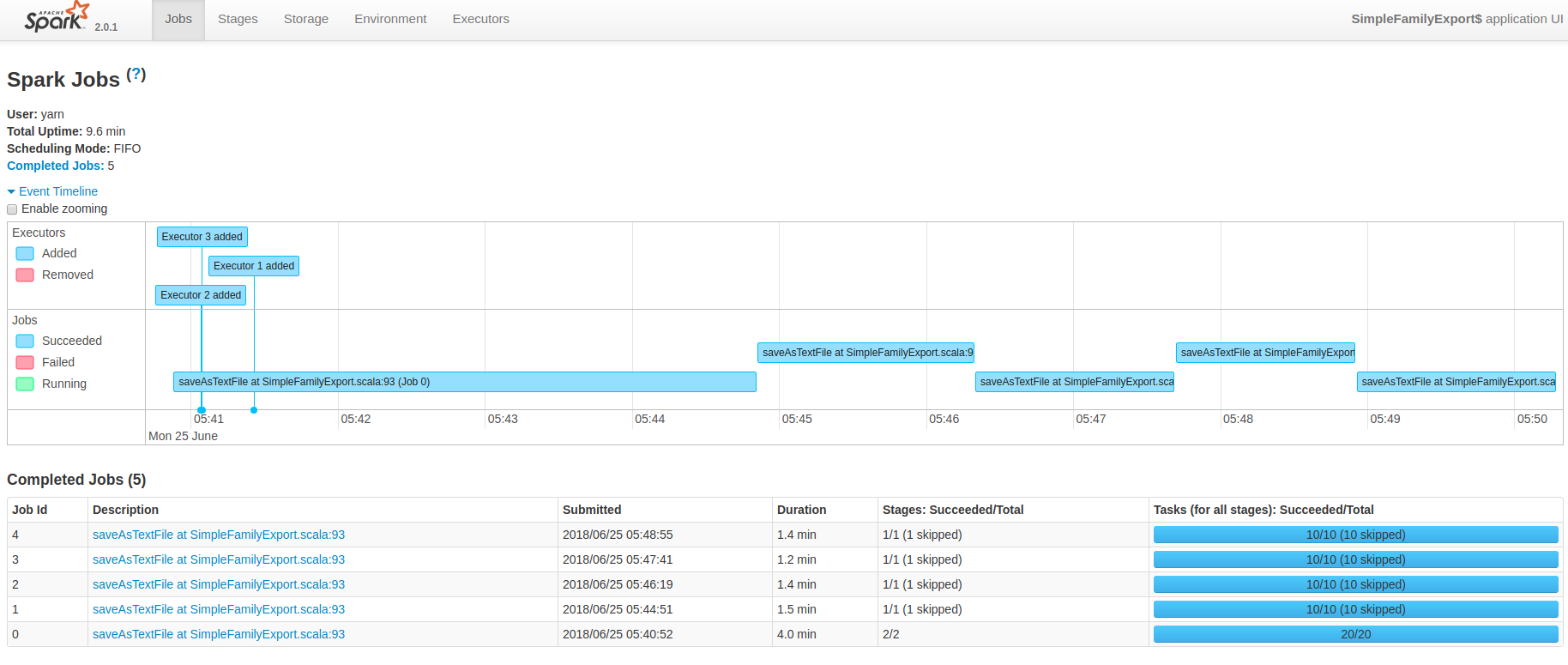
可以看出对于这个 application,共启动了5个job,另外根据 Event Timeline 来看,这5个job是串行处理的。
所以如果在完成任务目标的情况下,job的适当减少,application的速度就可以更快。那么我们先来看看能不能减少些job。
修改之前,首先要回答一个问题,为什么有5个job呢?
根据上面提到的处理逻辑,应该一个job分两个stage就结束了啊。 第一个stage读取文件,然后进入map阶段,然后shuffle到第二个stage,第二个stage对数据依次进行5个规则的check,输出就好了啊。
回顾一下上面提到的,application在什么时候会分job呢? 当在代码中对 RDD 进行 action操作时。知道了这个,来看看我自己的代码。
val familyMembers = firstStage(lines)
for (i <- 0 until rulesArray.length) {
val result = check(familyMembers, rulesArray(i))
result.saveAsTextFile(outputPath + i)
}
RDD的函数 saveAsTextFile ,就是一个action操作,所以for循环的每次循环,都会生成一个RDD:result,并且调用它的 saveAsTextFile 方法。
2. 减少 Job
明白了多个 Job 产生的原因就可以进行代码的修改了。其实也很简单,我们只需要把for循环移到check函数中就可以了。
主函数大概如下:
val familyMembers = firstStage(lines)
val result = familyMembers.flatMap(line => check(line))
result.saveAsTextFile(outputPath)
check函数主体大概如下:
def check(line: String): List[(Int, String)] = {
val array = line.split(";").toList
var allList = new ListBuffer[(Int, String)]()
for (i <- 1 until countriesArray.length) {
val output = getCheckResult(array, i)
allList.+=((i, output))
}
allList.toList
}
这样子,saveAsTextFile 就只执行了一次。
web UI截图如下:
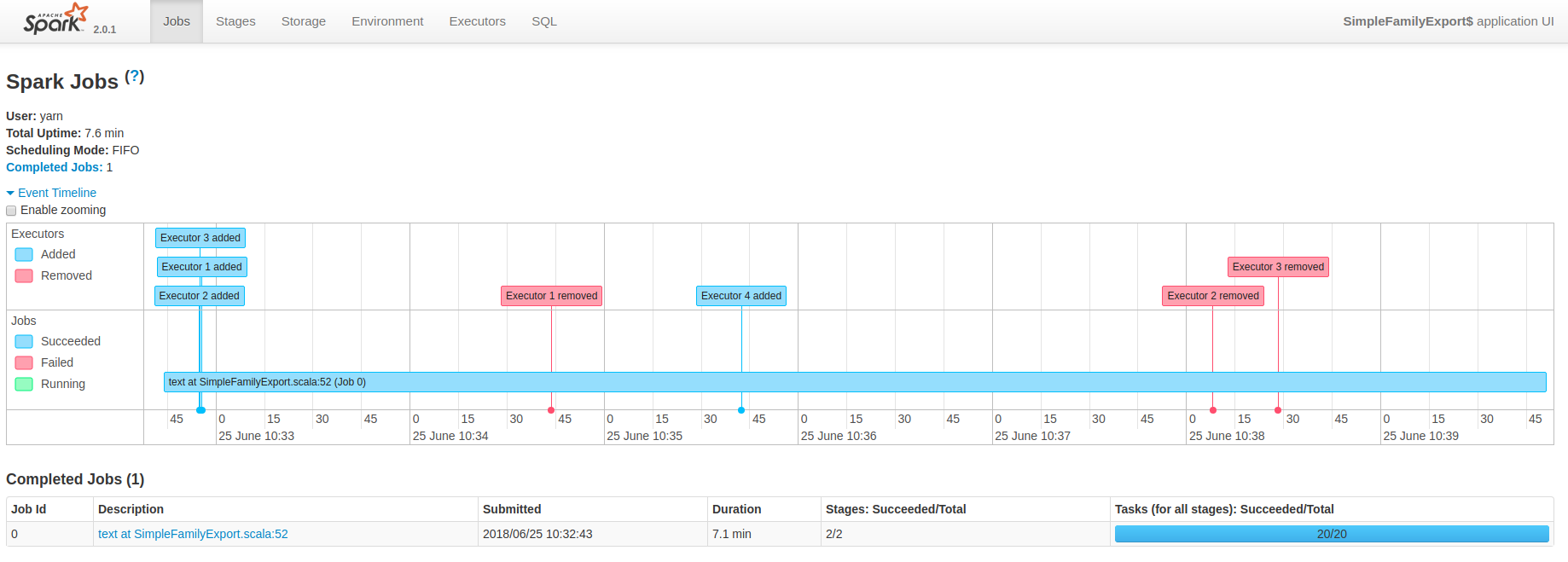
可以看出,这次只有一个Job了,执行时间降低到了 7.1 min。
3. 增加task数量
注意到上图中 “Tasks (for all stages): Succeeded/Total ”,spark只启动了20个task。
对于一个拥有23台机器的集群,20个task显得太小菜一碟了,那能不能进一步“压榨”集群的能力呢?换句话说,就是如何增加task的数量呢?
我们点进 Job 的 Description 中,如下图:
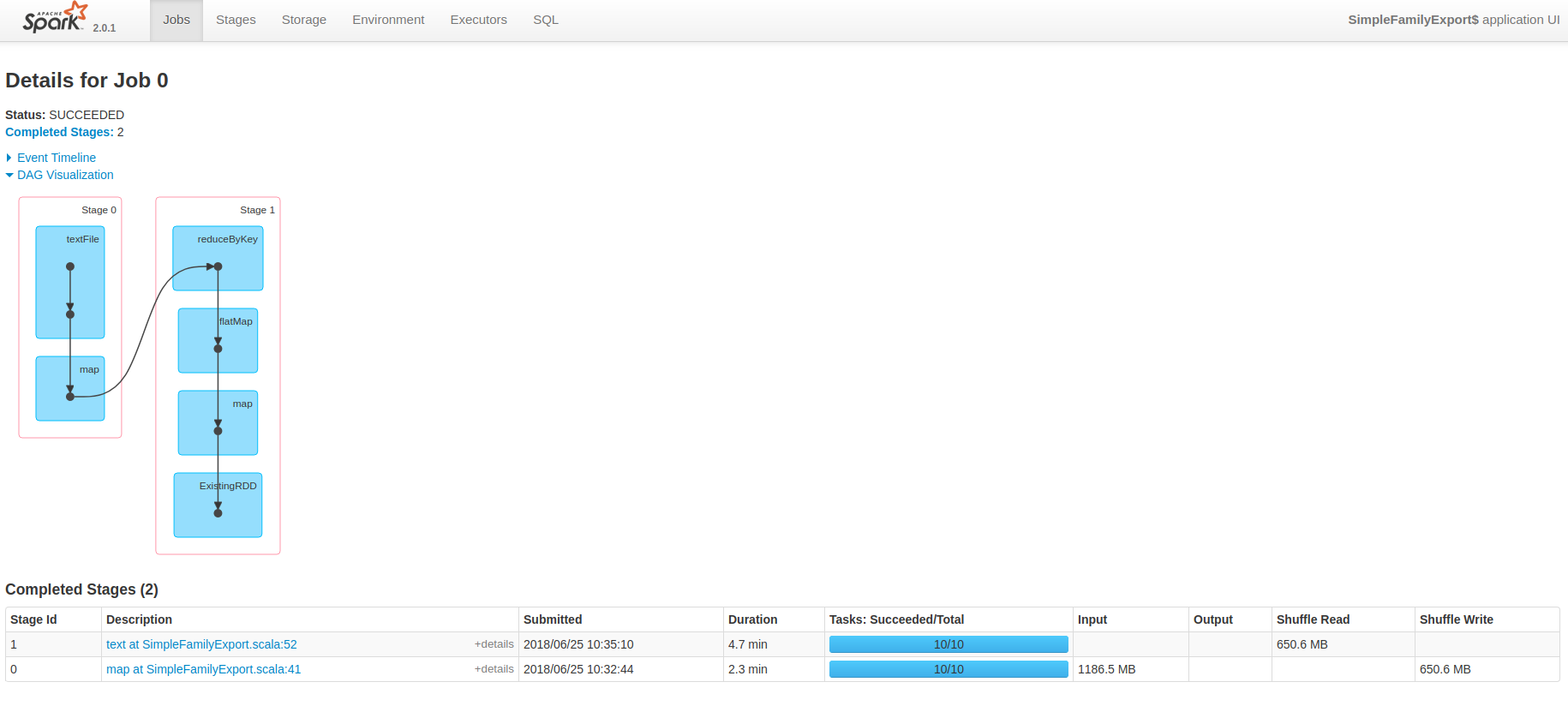
可以看出这个job被分为了两个stage,每个stage都是10个task。 我们分别来看一看是什么因素影响了这两个stage的task数目。
1. 第一个stage
第一个stage主要做的工作有两个:textFile, map。
在 textFile阶段, Spark 默认会根据文件的块数来启动对应的task。 比如这个文件size为 1186.5M, hadoop 2.7中 hdfs 默认block大小为128M, 所以 1186/128 = 9.2, 向上取整就是10。
那如何让task多一些呢? sc.textFile有第二个参数:minPartitions, 我们就可以更改这个参数来增加task数量。如下,启动100个task读取文件。
val lines = sc.textFile(args(1), 100)
2. 第二个stage
第二个stage进行了shuffle操作。在shuffle后端的task数量,默认和shuffle前端的task数量一致。
那该怎么增加task数量呢? 这里有两个方法。
第一种: 为reduceByKey方法传入第二个参数:numPartitions,用来控制分区数。 第二种:设置全局并行度,也就是设置 ”spark.default.parallelism“。
我选择了第二种,并把并行度设为了100.
4. 查看结果
来看看Job:
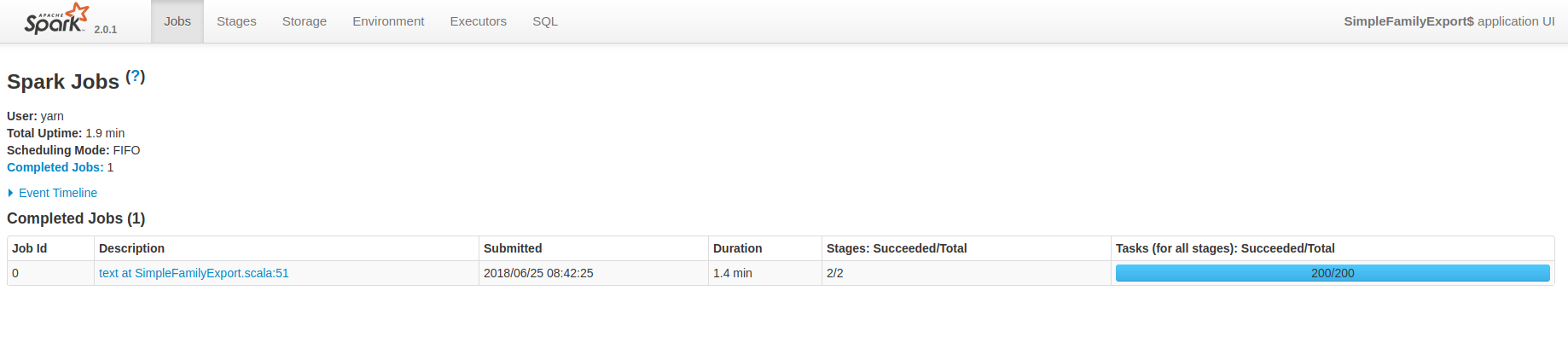
和 Stage:
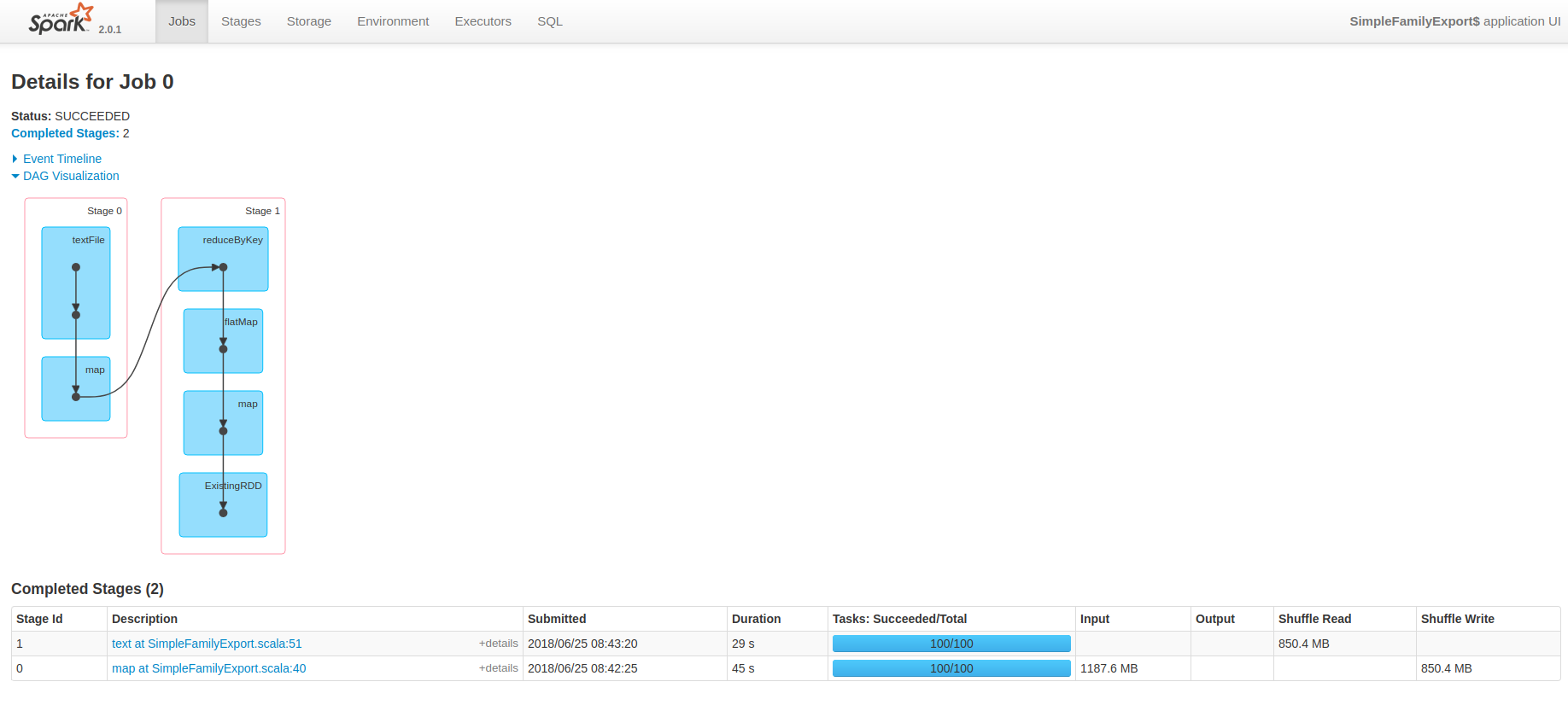
在上图中可以看到,Total Uptime 降到了 1.9 min。
总结
至此为止,任务时间从 9.6 min 降为1.9 min,提升约80%。
总结如下:
- 适当的减少job数量,可以增加效率
- 要了解集群的计算能力,也就是同时可以运行多少个task,计算公式为:total task = spark.executor.instances × spark.executor.cores
- 为application选择合适的task数量,推荐为集群能承受的task数目的2-3倍
我相信,还有其他的调优方式,以后继续学习。