提起 Spark 调优,通常的目标都是如何让运行时间短,但最近看到一篇有趣的文章,它的调优目标却是如何让云服务费用越低,而做到了在保证不增加运行时间、不减少处理的数据的情况下,将云服务的费用降低了 60 %,很酷很新颖,来看看。
前言
让我们先重新审视一下什么是调优。所谓调优就是在固定的资源条件下,让程序产生更高的输出,即提高资源产出率。反过来说,在完成同样的工作的条件下,需要的资源就少了,那么相应的费用就会下降。作者就是基于这个思路对云服务费用进行调优。
先重温两点基础知识。
1. Spark 的基础知识
Spark 通常通过 4 个参数来调整Spark job的性能,分别是:
- –num-executors:控制多少个executor 来处理数据
- –executor-cores:控制每个executor 使用多少个 CPU core
- –executor-memory: 控制每个executor 使用多少 memory
- –driver-memory: driver的内存
更多关于driver、executor的知识,可以到这里更详细的了解。
2. 集群资源
那么对于一个集群来讲,资源包括 CPU、memory、network、disk 等,但是和计算相关的主要是CPU 和 memory。
CPU
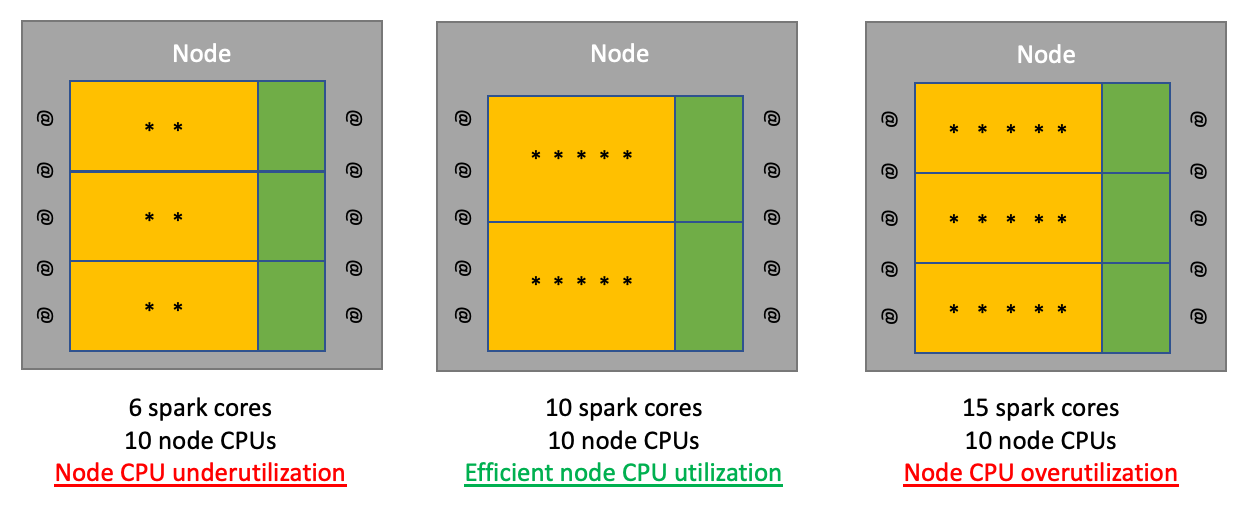
CPU 有三种使用状态:
- underutilization:有空闲的core
- efficient utilization:所有core都在忙,而且主要时间用在计算上。(这个状态是我们最希望达到的)
- ovetutilization:所有的core都在忙,但是task太多,由于 Time Slicing 策略,内核会频繁切换计算,那么大量的CPU时间就浪费切换动作上了。
内存
memory 不像 CPU 存在 time-slicing 策略,所以两个executor 使用的内存不会有重叠。那么在节点 memory size 固定的情况下,节点上能运行多少个 executor 其实 executor-memory 来决定的。 不严谨的算法就是 executor count = memory size / executor-memory, 为什么不严谨呢?因为存在两个原因:
- 节点不能把所有 memory 给executor,它要保留一些给操作系统和 Cluster Manager
- 因为存在 overhead memory, 所以executor 实际使用的比 executor-memory 多
那么严谨的算法其实:executor count = available node memory / total executor memory size (executor_memory + overhead memory).
后面会详细说明这两点。
开始
0. 定义cost基准
不管做什么调优,我们首先就是要定义基准 (benchmark)。那么怎么定义云服务费用的基准呢?
- 关闭 dynamic allocation : 因为动态分配会使估计过程复杂化,executor的数量在整个job中变化很大。后续确定好最优参数后,生产上运行时可以再把它打开。
- 确定所使用的机器类型的费用。作者用的是 AWS EC2 r5.4xlarge,参数是 16 cores / 128 G,要记住这两个指标,非常重要,后面会用到。
- 最终费用 = 节点数量* 运行时间 * 节点价格
确定好benchmark后,就可以开始调节参数了。
1. 调整参数
executor-cores
因为每个节点需要保留一个core给操作系统和 Cluster Manager,所以每个节点的可用core数量其实是 total core - 1。在这个例子中就是 16 - 1 = 15 cores。
那么每个executor应该用多少个core 呢?有4种方案:
| 每个节点Spark可用的core数量 | executor 数量 | 每个executor用的core数量 |
|---|---|---|
| 15 | 1 | 15 |
| 15 | 3 | 5 |
| 15 | 5 | 3 |
| 15 | 15 | 1 |
第一种方案的问题在于,支持这么多core的executor通常会有一个很大的内存池 memory pool(64GB+),它的垃圾收集会很多,那么GC延迟会不合理地减慢job的速度。 因此,排除此配置。
第四种是另外一个极端,每个executor一个core,但这是非常低效的,因为它们没有利用executor内多个核启用的并行性。此外,为单核executor找到最佳的 overhead memory 可能很困难。
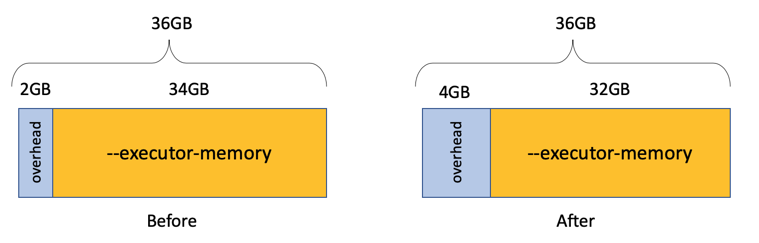
顺便来谈谈什么是 overhead memory。它是给每个executor分配的额外内存,默认是 executor memory的 10 % 或者是固定的大小 384 M。如果它太小,会让你的job出现问题。另外当它是固定size的时候,越多的executor数量会占用越多的overhead memory ,也会导致executor真正能使用的memory减少。到官方文档搜索 spark.executor.memoryOverhead可以了解更多。
排除了第一和第四种之后,该怎么选择剩下两种呢?答案是 3 executor * 5 cores。为什么呢?原因有二:
- 大多数 Spark 调优指南的共识是,5 个 core 是每个executor 并行处理的最佳数量。(注:这里超出我的理解范围了,可能就是一个共识吧,没人解释为什么,记住就好)。
- 另外 3 个 executor 比起 5个 executor 可以使用更少的 overhead memory
所以最终 executor-cores 就确定了,为 5。另外我们也希望每个node上只跑3个executor。
executor-memory
先确定一下一个node可以有多少可用内存。这个打开 Cluster Manager 就可以看到了:
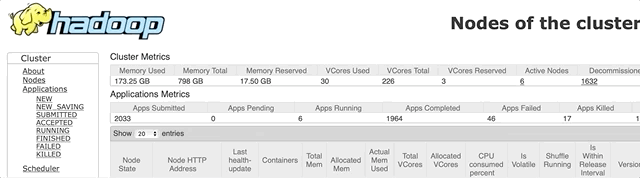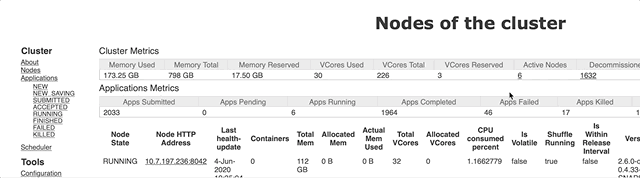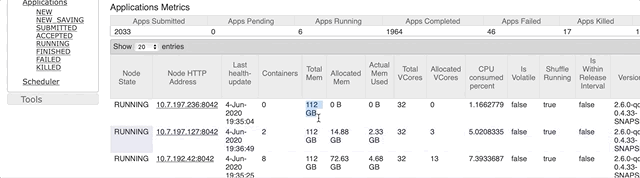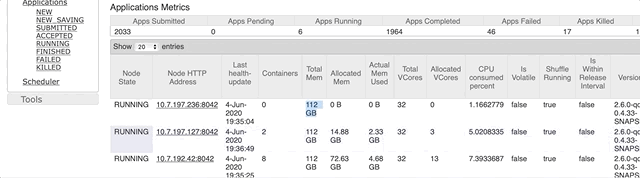
显示是 112 G,所以系统和cluster manager 用了 16 G。
现在来计算每个executor用多少内存:
- 当overhead memory是固定的:112/3 = 37– 2.3 (384M) = 34.7 = 34
- 当overhead memory 是executor memory 的 10% 时: 112/3 = 37 / 1.1 = 33.6 = 33
因为这个作者发现memory是固定的情况下,效率最高,所以他选择使用了固定size的overhead memory,那么 executor-memory 就是34 G。
executor-numbers
最佳实践如图所示,要保留一个位置给driver。
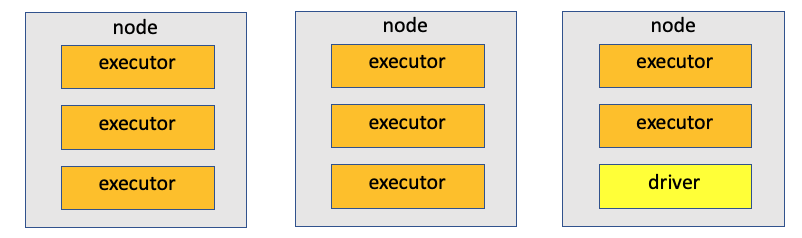
所以 num-executors = (3x - 1) , x 为节点数量。
drive 相关参数
通常我们都把 driver 的memory 设置的比executor 少的多,但是 AWS 其实是建议保持 driver memory和executor 一致的。所以将 driver-memory 设置为 34G。
如果在某个情况下,你让 driver memory 是 executor memory的2倍,那么你就要更改 executor number 为 3x - 2。 因为相当于一个driver 占了两个executor。
默认driver的core数量为一,但是作者发现,当Spark job 使用超过 500 个 cores 时,将driver core设置为与executor core可以获得性能优势。 不过,默认情况下不要更改driver core,只有当你对大型作业进行测试时,可以试着改一下,看看是否有性能改善。
思考:一组配置走遍天下?
不一定,你需要根据自己 job 的实际情况,多多尝试不同组合。
2. 迁移jobs
经过上一节,我们拿到了最有效的spark config:
--driver-memory 34G --executor-memory 34G --num-executors (3x-1) --executor-cores 5
那么接下来就是迁移现有的job了。
哪类job应该先迁移?
- executor core 是 1 或者 2 的 (注:我理解这种情况是指优化空间大的 jobs)
- Spark core minutes(Executor count * cores per executor * run time (in minutes) ) >= 3000 (注:这种情况是指比较费钱的 jobs)
注意事项
- 保持使用的资源一致。改变 executor core count的同时也要改 executor count ,这样子对比效率才有意义。比如:
- Old configuration (100 Spark cores): num-executor=50 * executor-cores=2
- New configuration (100 Spark cores): num-executor=20 * executor-cores=5
- 在对转换的job进行测试时,禁用dynamic allocation。
- 当发觉 job 有很多 CPU wait 时间的话,就是有大量的IO操作时,可以考虑让 node 处于 over-utilization 的状态,这样子效率可能会更高 (类比多线程读取数据库):
- 增加 executor core count
- 降低 executor memory,以便让一个node上可以有更多的executor
- 建议增加核心数量,直到达到 5,然后一旦达到该限制,将内存减少到允许在您的节点上增加一个执行程序的数量。
- 换一个更大的机器类型。因为作者发现,Spark 的 job 在具有更大内存与 CPU 比率的节点上运行会更有效率。
- 如果没有使用所有节点 CPU,那么应该考虑在内存与 CPU 比率较低的集群上运行。
- 如果 CPU 利用率和内存利用率均为 100%,那么在这种情况下,内存通常会成为瓶颈,因此切换到更松散的节点将导致作业通常运行得更快、成本更低。
意外情况
运行时间可能会变慢,但不要担心,新配置运行成本会更低。
3. 解决常见的错误
有时,当切换到高效的执行程序配置时,执行程序会出现内存问题。 如果/当发生这种情况时,说明执行程序没有有效地处理数据,需要进一步调整。 您可以通过检查在 Spark 运行期间是否有任何失败的任务来查看您的执行程序是否没有有效工作。

查看失败的task
要查看失败的任务,请单击 Spark U/I 中的failed stage。 然后,向下滚动到“task”部分的底部以查看任务详细信息。
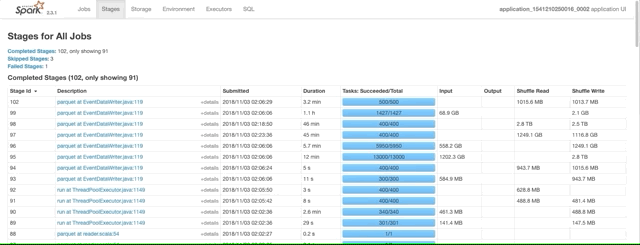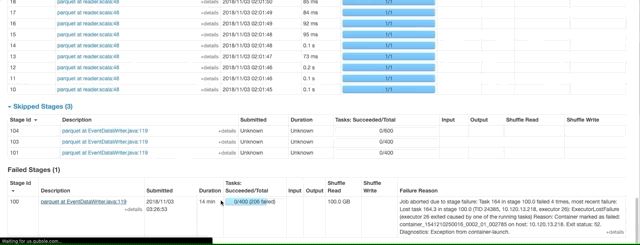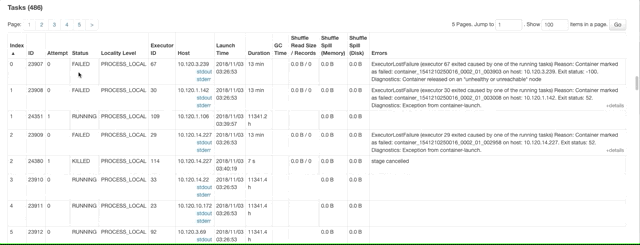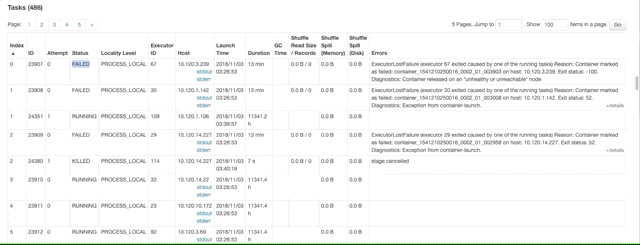
Overhead memory error
错误日志:
ExecutorLostFailure (executor X exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 34.4 GB of 34.3 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
解决方法:以 1000 的倍数增加overhead memory,同时减少相同数量的executor memory
Shuffle memory errors
错误日志:
ExecutorLostFailure (executor X exited caused by one of the running tasks) Reason: Container marked as failed: container_1541210250016_0002_01_003278 on host: 10.120.8.88. Exit status: -100. Diagnostics: Container released on an *unhealthy or unreachable* node
解决方法: 提高Spark的并行度,数值为 X = num-executors * executor-cores * 2,然后
--conf spark.sql.shuffle.partitions = X
--conf spark.default.parallelism = X
当其他一切都失败时……
将executor的core 数量减少 1。这将增加executor的内存与核心比率。 这种特殊的更改应该作为最后的手段进行,因为它会减少节点上Spark 运行的内核数量,从而降低节点效率。
总结
作者根据云服务中集群机器的实际情况,调整 Spark executor-cores 、executor-memory等参数,来获取最大的计算效率,从而降低了云服务的费用。
但仔细想想,作者的这个调优方式,不一定适合本地集群环境。原因有二:
- 在本地集群下,可能存在多种类型的节点机器,所以我们再设置 executor memory 和 core的时候,总不是很大,因为我们希望能够更充分的利用所有节点。但是云环境下,所有机器节点类型都是在创建集群前设置好的,而且会保持一致。
- 另外本地集群不会只运行你一个人的任务,所以通过调参把整个集群的资源压榨干净是无法接受的,即使你通过调参有这个能力。但是云环境就不一样了,通常一个集群只会有你一个人的任务,所以你就可以充分的“压榨”集群所有资源。
原文链接
感兴趣的同学可以直接阅读原文,更加原汁原味,一共6个part:
- Part 1: Cloud Spending Efficiency Guide for Apache Spark on EC2 Instances
- Part 2: Real World Apache Spark Cost Tuning Examples
- Part 3: Cost Efficient Executor Configuration for Apache Spark
- Part 4: How to Migrate Existing Apache Spark Jobs to Cost Efficient Executor Configurations
- Part 5: How to Resolve Common Errors When Switching to Cost Efficient Apache Spark Executor Configurations
- Part 6: Summary of Apache Spark Cost Tuning Strategy & FAQ