Spark 使用 **master/worker **结构。
这里有一个driver 程序与一个名为master的协调器进行通信,这个 master 管理运行着 executors 的 workers 。
总览
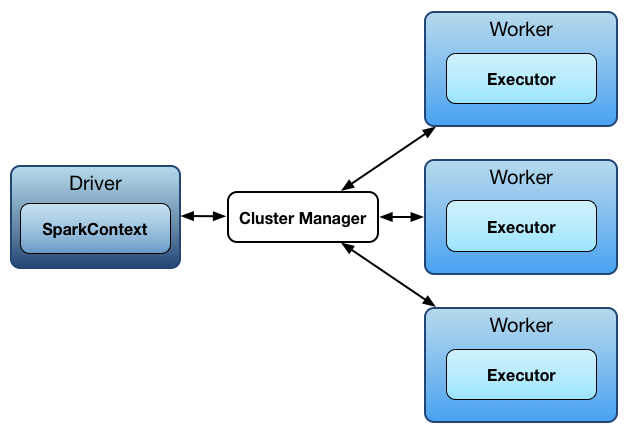
driver 和 executors 们都运行在它们各自的 Java 进程中。
您可以在相同机器上(称为水平集群),或单独的计算机(称为垂直集群)上或在混合计算机配置中运行它们。
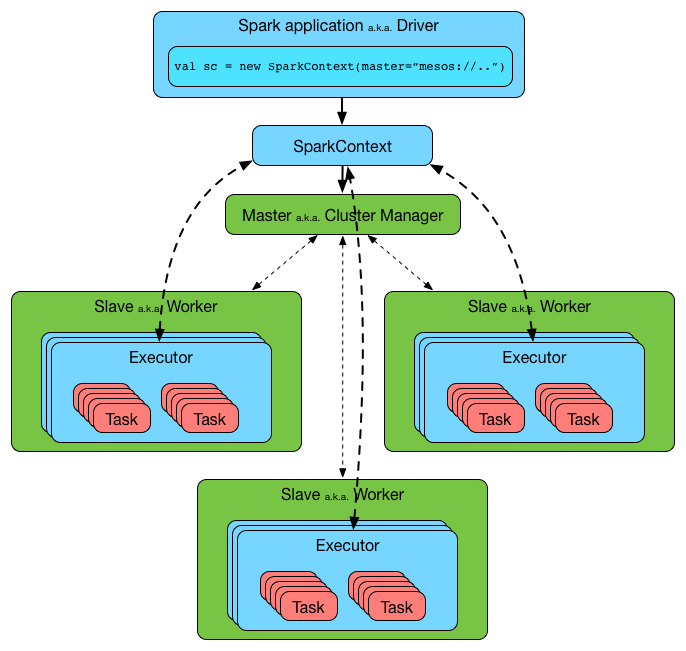
物理机器们被叫做 hosts 或者 nodes。
Driver
Spark driver (又名Spark应用的 driver 进程),是一个JVM进程,它为Spark应用程序托管SparkContext。它是Spark应用程序中的主节点。
它是作业和任务执行的驾驶舱(使用DAGScheduler 和 Task Scheduler)。它为环境托管了Web UI。

它将Spark应用程序拆分为 tasks 并安排它们在 executors 上运行。
driver 是task scheduler 所在的位置,并在 workers 之间生成 tasks。
driver 协调 workers 和 tasks 的总体执行。
Spark shell是Spark应用程序和driver。它创建一个可用作sc的SparkContext。
Driver 需要额外的服务(除了常见的服务,如ShuffleManager,MemoryManager,BlockTransferService,BroadcastManager,CacheManager):
- Listener Bus
- RPC Environment
- MapOutputTrackerMaster
- BlockManagerMaster
- HttpFileServer
- MetricsSystem
- OutputCommitCoordinator
Driver’s Memory
它可以先使用spark-submit的--driver-memory命令行选项或spark.driver.memory设置,如果之前没有设置则可以回退到SPARK_DRIVER_MEMORY。
它以spark-submit的详细模式( verbose mode)打印到标准错误输出。
Driver’s Cores
可以首先使用spark-submit的--driver-cores命令行选项设置 cluster 部署模式。
在 client 部署模式下,driver 的内存对应于Spark应用程序运行的JVM进程的内存。
Settings
spark.driver.extraClassPath
spark.driver.extraClassPath 系统属性设置应在 cluster 部署模式下添加到driver 类路径的其他类路径条目(例如jar和目录)。
注意事项:
- 对于 cluster 模式,你可以使用命令行或者配置文件来设置这个属性。
- 对于client 模式, 不要使用 SparkConf 来设置这个属性,因为它为时已晚,此时JVM已经设置为启动Spark应用程序。
- 有关如何在内部处理它的非常low-level的详细信息,请参阅 buildSparkSubmitCommand 内部方法。
spark.driver.extraClassPath 使用操作系统分隔符。
可以在命令行上使用spark-submit的--driver-class-path命令行选项来覆盖Spark属性文件中的spark.driver.extraClassPath。
Executor
Executor是一个负责执行 tasks 的分布式代理。
Executor是在以下时候被创建:
CoarseGrainedExecutorBackend接收RegisteredExecutor消息(对于Spark Standalone和YARN)- Mesos 模式下
MesosExecutorBackend执行registered - 本地模式下,
LocalEndpoint被创建
Executor 通常在Spark应用程序的整个生命周期内运行,该应用程序称为执行程序的静态分配(static allocation of executors)(但您也可以选择动态分配)。
Executors 被 executor backends 专门负责。
Executors 向 driver上的HeartbeatReceiver RPC Endpoint报告活动任务的心跳和部分指标。
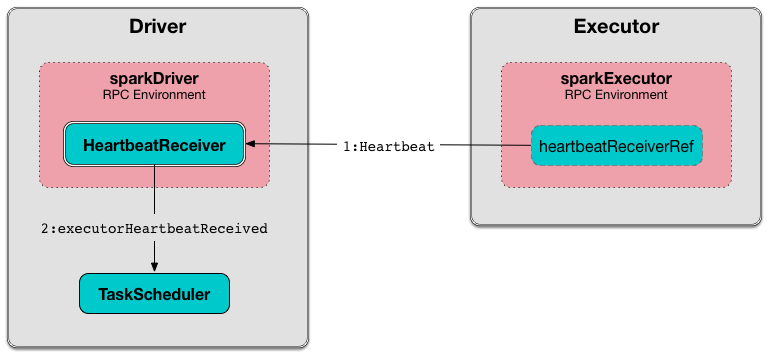
Executors 为在Spark应用程序中缓存的RDD提供内存存储(通过块管理器(Block Manager))。
当一个 executor 启动时,它首先向 driver 注册并直接与之通信来执行任务。
Executor offers 由executor id和执行程序运行的host描述。
Executors 可以在其生命周期内并行和顺序地运行多个任务。它们跟踪运行任务(通过runningTasks内部注册表中的任务ID)。请参阅启动任务部分。
Executors 使用Executor任务启动工作线程池来启动任务。
Executors 使用内部心跳器(Heartbeat Sender Thread)发送指标(和心跳)。
建议您拥有与数据节点一样多的executors,以及和能从集群中获得的一样多的核心数量。
Executors 被描述为它们的 id, hostname, environment (SparkEnv), 和 classpath (而且,对于内部优化而言,更重要的是,它们是以本地模式还是集群模式运行)。
Tip:
为
org.apache.spark.executor.Executor记录器启用INFO或DEBUG日志记录级别,以查看内部发生的情况。将以下行添加到conf/log4j.properties:log4j.logger.org.apache.spark.executor.Executor=DEBUG
创建Executor 实例
在创建时执行以下操作:
-
Executor ID
-
Executor’s host name
-
SparkEnv
-
Collection of user-defined JARs (to add to tasks’ class path). Empty by default
用户定义的JAR是使用CoarseGrainedExecutorBackend的
--user-class-path命令行选项定义的,可以使用spark.executor.extraClassPath属性进行设置。 -
Flag that says whether the executor runs in local or cluster mode (default:
false, i.e. cluster mode is preferred)isLocal专门为LocalEndpoint启用(对于本地模式下的Spark)
-
Java’s
UncaughtExceptionHandler(default:SparkUncaughtExceptionHandler)
创建后,您应该在日志中看到以下INFO消息:
INFO Executor: Starting executor ID [executorId] on host [executorHostname]
(只对于非local模式)Executor 将SparkUncaughtExceptionHandler设置为当线程由于未捕获的异常而突然终止时调用的默认处理程序。
(仅适用于非local模式)Executor 请求BlockManager初始化(使用SparkConf的Spark Application ID)。
(仅适用于非本地模式)Executor 请求MetricsSystem注册BlockManager的ExecutorSource和shuffleMetricsSource。
Executor创建一个任务类加载器 Task class loader(可选择使用REPL支持),这是当前的Serializer需要使用的(稍后反序列化任务时)。
Executor 开始发送心跳和活动任务指标。
Executor 在此期间初始化内部注册表和计数器(不一定在最后)。
方法
launchTask
launchTask(
context: ExecutorBackend,
taskId: Long,
attemptNumber: Int,
taskName: String,
serializedTask: ByteBuffer): Unit
launchTask会同时执行输入serializedTask任务。
在内部,launchTask创建一个TaskRunner,在runningTasks内部注册表中注册它(通过taskId),最后在“Executor task launch worker”线程池上执行它。
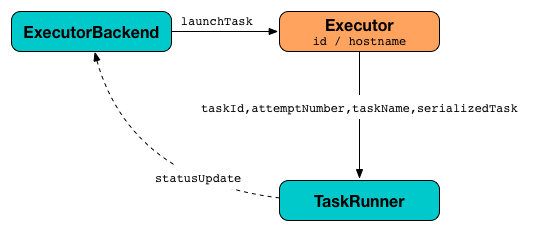
startDriverHeartbeater
Executor 每隔spark.executor.heartbeatInterval向驱动程序发送活动任务的度量标准(默认为10s,随机初始延迟一些,因此来自不同执行程序的心跳不会堆积在驱动程序上)。
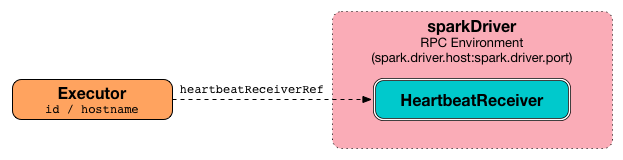
Executor 使用内部心跳发送心跳 - Heartbeat Sender Thread。
对于TaskRunner中的每个任务(在runningTasks内部注册表中),计算任务的度量(即mergeShuffleReadMetrics和setJvmGCTime),它们成为心跳的一部分(带累加器)。
Executor 跟踪运行任务的TaskRunner。当Executor 发送心跳时,可能还没有将任务分配给TaskRunner。
包含执行程序ID、所有累加器更新(每个任务ID)的阻塞Heartbeat消息和BlockManagerId将发送到HeartbeatReceiver RPC端点(使用spark.executor.heartbeatInterval超时)。
TaskRunner
TaskRunner 是一个执行单个任务的线程。
TaskRunner 是在请求Executor启动任务时专门创建的。

TaskRunner可以运行或终止,这意味着分别运行或终止此TaskRunner对象管理的任务。
创建TaskRunner实例
TaskRunner在创建时采用以下内容:
- ExecutorBackend
- TaskDescription
Lifecycle
当请求执行程序启动任务时,将创建TaskRunner对象。
它是使用ExecutorBackend(发送任务的状态更新),任务和尝试ID,任务名称和任务的序列化版本(作为ByteBuffer)创建的。
运行Task — run 方法
run(): Unit
初始化
执行时,run 初始化threadId作为当前线程标识符(使用Java的Thread)。
run 然后将当前线程的名称设置为threadName(使用Java的线程)。
run创建一个TaskMemoryManager(使用当前的MemoryManager和taskId)。
run开始跟踪反序列化任务的时间。
run设置当前线程的上下文类加载器(使用replClassLoader)。
run创建一个闭包Serializer。
run 通知 ExecutorBackend 这个taskId 已经为 TaskState.RUNNING 状态了。
run计算startGCTime。
run更新依赖关系。
run反序列化任务(使用上下文类加载器)并设置其localProperties和TaskMemoryManager。 run设置任务内部引用以保存反序列化的任务。
如果启用了killed flag,则run会抛出TaskKilledException。
在debug 级别的日中中将会显示:
DEBUG Executor: Task [taskId]'s epoch is [task.epoch]
run 给MapOutputTracker 通知task的epoch。
run 记录任务开始时间。
开始运行
run 开始运行任务(把taskId当作taskAttemptId,从taskDescription中拿到 attemptNumber ,把 metricsSystem 作为当前的 MetricsSystem)。
结束运行后
在任务运行完成之后(在监视的块中的最后一个数据块),run 通知 BlockManager 释放所有这个任务的所有锁(通过taskId)。锁稍后用于锁泄露检查。
run 然后会请求 TaskMemoryManager 来释放所有获取的内存 (这个将有助于找到内存泄漏)。如果发现了内存泄露(也就是释放的内存大于0),同时spark.unsafe.exceptionOnMemoryLeak被设置为true(默认为false),而且在运行中task也没有抛出异常,run 就会报告一个 SparkException:
Managed memory leak detected; size = [freedMemory] bytes, TID = [taskId]
否则,如果spark.unsafe.exceptionOnMemoryLeak为false,就会打印出ERROR信息:
ERROR Executor: Managed memory leak detected; size = [freedMemory] bytes, TID = [taskId]
如果锁泄露被发现,而且spark.storage.exceptionOnPinLeak设置为true,打印SparkException:
[releasedLocks] block locks were not released by TID = [taskId]:
[releasedLocks separated by comma]
否则就是ERROR日志信息。
在“被监视”块之后,运行将当前时间记录为任务的完成时间(作为taskFinish)。
如果task在运行时被kill,那么它就会抛出一个TaskKilledException 。
更新指标与输出结果
run 创造出一个序列器来序列化结果,同时记录所花费的时间。
run 记录task的指标:
- executorDeserializeTime
- executorDeserializeCpuTime
- executorRunTime
- executorCpuTime
- jvmGCTime
- resultSerializationTime
run收集任务中使用的内部和外部累加器的最新值。
run创建一个DirectTaskResult(带有序列化结果和累加器的最新值)。
run序列化DirectTaskResult并获取字节缓冲区的限制。
run在将结果发送到ExecutorBackend之前选择正确的序列化版本的结果。
Workers
Workers(也称为slaves)是指那些正在运行Spark的实例,executors在其中执行任务。它们是Spark中的计算节点。
工作程序接收在线程池中运行的序列化任务。
它托管一个本地块管理器,为Spark集群中的其他workers 提供块。workers 使用他们的Block Manager实例进行相互通信。
解释Spark中的任务执行并理解Spark的底层执行模型。
创建SparkContext时,每个worker都会启动一个执行程序。这是一个单独的进程(JVM),它也会加载你的jar。执行程序连接回驱动程序。现在驱动程序可以发送命令,如flatMap,map和reduceByKey。当驱动程序退出时,执行程序关闭。
不会为每个步骤启动新进程。构建SparkContext时,将在每个worker上启动一个新进程。
executor 反序列化命令(这是可能的,因为它已经加载了你的jar),并在分区上执行它。
简而言之,Spark中的应用程序分三步执行:
- 创建RDD图,即RDD的DAG(有向无环图)以表示整个计算。
- 创建阶段图,即基于RDD图的逻辑执行计划的阶段DAG。通过在随机边界处打破RDD图来创建阶段。
- 根据计划,在worker上安排和执行任务。