定义
SVM的全称是Support Vector Machine,即支持向量机,主要用于解决模式识别领域中的数据分类问题,属于有监督学习算法的一种。
通俗来讲,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,其学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。
线性分类的一个例子
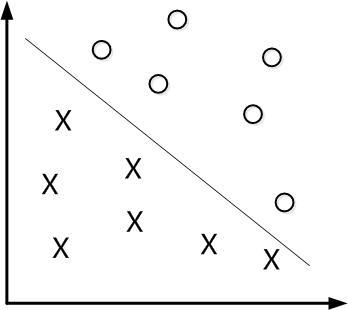
如下图所示,现在有一个二维平面,平面上有两种不同的数据,分别用圈和叉表示。由于这些数据是线性可分的,所以可以用一条直线将这两类数据分开,这条直线就相当于一个超平面,超平面一边的数据点所对应的y全是-1 ,另一边所对应的y全是1。
这个超平面可以用分类函数 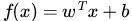 表示,当f(x) 等于0的时候,x便是位于超平面上的点,而f(x)大于0的点对应 y=1 的数据点,f(x)小于0的点对应y=-1的点,如下图所示:
表示,当f(x) 等于0的时候,x便是位于超平面上的点,而f(x)大于0的点对应 y=1 的数据点,f(x)小于0的点对应y=-1的点,如下图所示:
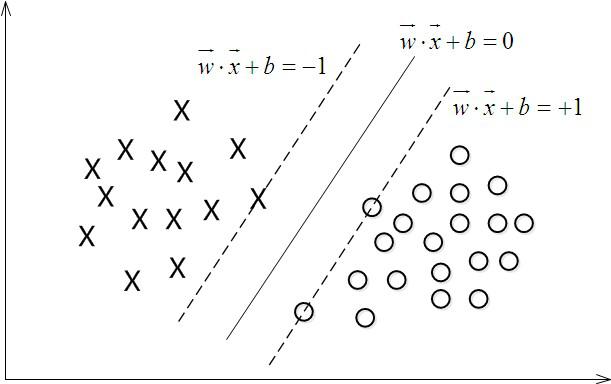
在进行分类的时候,遇到一个新的数据点x,将x代入f(x) 中,如果f(x)小于0则将x的类别赋为-1,如果f(x)大于0则将x的类别赋为1。
接下来的问题是,如何确定这个超平面呢?从直观上而言,这个超平面应该是最适合分开两类数据的直线。而判定“最适合”的标准就是这条直线离直线两边的数据的间隔最大。所以,得寻找有着最大间隔的超平面。
核函数Kernel
事实上,大部分时候数据并不是线性可分的,这个时候满足这样条件的超平面就根本不存在。
那对于非线性的数据SVM怎么处理呢?对于非线性的情况,SVM 的处理方法是选择一个核函数 κ(⋅,⋅) ,通过将数据映射到高维空间,来解决在原始空间中线性不可分的问题。
具体来说,在线性不可分的情况下,支持向量机首先在低维空间中完成计算,然后通过核函数将输入空间映射到高维特征空间,最终在高维特征空间中构造出最优分离超平面,从而把平面上本身不好分的非线性数据分开。如图所示,一堆数据在二维空间无法划分,从而映射到三维空间里划分:
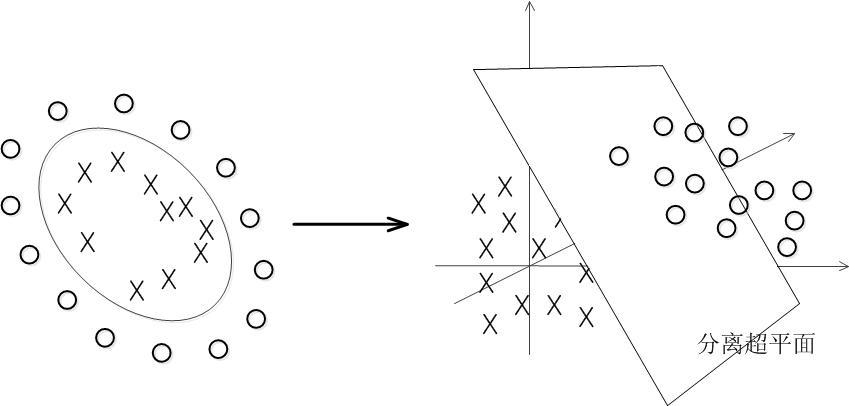
核函数分类
线性核函数
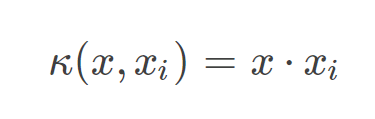
线性核,主要用于线性可分的情况,我们可以看到特征空间到输入空间的维度是一样的,其参数少速度快,对于线性可分数据,其分类效果很理想,因此我们通常首先尝试用线性核函数来做分类,看看效果如何,如果不行再换别的。
多项式核
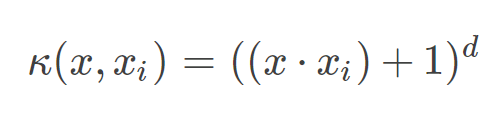
多项式核函数可以实现将低维的输入空间映射到高纬的特征空间,但是多项式核函数的参数多,当多项式的阶数比较高的时候,核矩阵的元素值将趋于无穷大或者无穷小,计算复杂度会大到无法计算。
高斯核
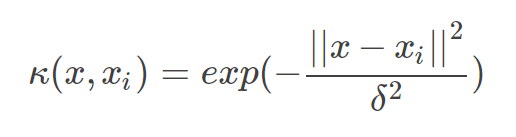
高斯核函数是一种局部性强的核函数,其可以将一个样本映射到一个更高维的空间内,该核函数是应用最广的一个,无论大样本还是小样本都有比较好的性能,而且其相对于多项式核函数参数要少,因此大多数情况下在不知道用什么核函数的时候,优先使用高斯核函数。
sigmoid核函数
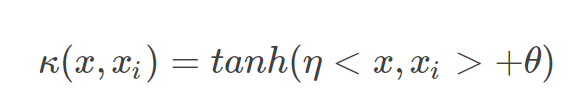
采用sigmoid核函数,支持向量机实现的就是一种多层神经网络。
如何选择
- 如果特征的数量大到和样本数量差不多,则选用LR或者线性核的SVM;
- 如果特征的数量小,样本的数量正常,则选用SVM+高斯核函数;
- 如果特征的数量小,而样本的数量很大,则需要手工添加一些特征从而变成第一种情况。
优缺点
优点
SVM理论提供了一种避开高维空间的复杂性,直接用此空间的内积函数(既是核函数),再利用在线性可分的情况下的求解方法直接求解对应的高维空间的决策问题。
当核函数已知,可以简化高维空间问题的求解难度。同时SVM是基于小样本统计理论的基础上的,这符合机器学习的目的,而且支持向量机比神经网络具有较好的泛化推广能力。
缺点
对于每个高维空间在此空间的映射F,如何确定F也就是核函数,现在还没有合适的方法,所以对于一般的问题,SVM只是把高维空间的复杂性的困难转为了求核函数的困难。而且即使确定核函数以后,在求解问题分类时,要求解函数的二次规划,这就需要大量的存储空间。这也是SVM的一个问题。
参考
- https://blog.csdn.net/v_july_v/article/details/7624837
- https://baike.baidu.com/item/%E6%94%AF%E6%8C%81%E5%90%91%E9%87%8F%E6%9C%BA/9683835?fromtitle=svm&fromid=4385807
- https://blog.csdn.net/fengzhizizhizizhizi/article/details/23911699
- https://blog.csdn.net/batuwuhanpei/article/details/52354822