定义
聚类算法是一种无监督学习算法。
k均值算法是其中应用最为广泛的一种,算法接受一个未标记的数据集,然后将数据聚类成不同的组。
K均值是一个迭代算法,假设我们想要将数据聚类成K个组,其方法为:
- 随机选择K个随机的点(称为聚类中心);
- 对与数据集中的每个数据点,按照距离K个中心点的距离,将其与距离最近的中心点关联起来,与同一中心点关联的所有点聚成一类;
- 计算每一组的均值,将该组所关联的中心点移动到平均值的位置;
- 重复执行2-3步,直至中心点不再变化
数学表示
在聚类问题中,给我们的训练样本是 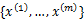 ,每个
,每个 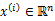 。
。
-
随机选取k个聚类质心点(cluster centroids)为
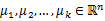
-
重复下面过程直到收敛 {
对于每一个样例i,计算其应该属于的类:
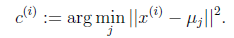
对于每一个类j,重新计算该类的质心:
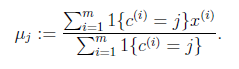
}
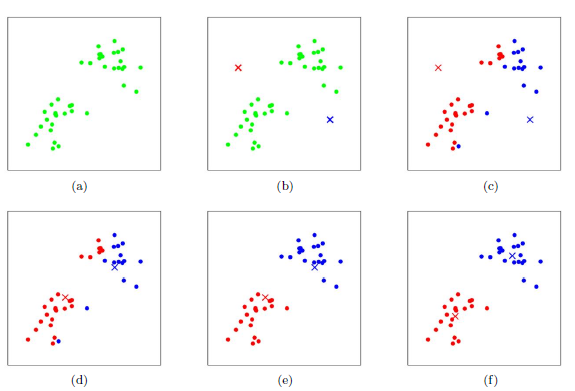
下图展示了对n个样本点进行K-means聚类的效果,这里k取2。
优缺点
当结果簇是密集的,而且簇和簇之间的区别比较明显时,K-Means 的效果较好。对于大数据集,K-Means 是相对可伸缩的和高效的,它的复杂度是 O(nkt),n 是对象的个数,k 是簇的数目,t 是迭代的次数,通常 k « n,且 t « n,所以算法经常以局部最优结束。
K-Means 的最大问题是要求先给出 k 的个数。k 的选择一般基于经验值和多次实验结果,对于不同的数据集,k 的取值没有可借鉴性。另外,K-Means 对孤立点数据是敏感的,少量噪声数据就能对平均值造成极大的影响。
参考
- http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006910.html
- https://www.cnblogs.com/gaochundong/p/kmeans_clustering.html