TaskScheduler 负责提交在Spark应用程序中执行的任务(根据调度策略)。
TaskScheduler 使用executorHeartbeatReceived和executorLost方法跟踪Spark应用程序中的执行程序,这些方法分别用于通知活动和丢失的执行程序。
Spark附带以下自定义 TaskSchedulers:
- TaskSchedulerImpl - 默认的TaskScheduler(以下两个特定于YARN的TaskSchedulers扩展)。
- 在客户端部署模式下,YARN上的Spark的YarnScheduler。
- 在集群部署模式下,YARN上的Spark的YarnClusterScheduler。
TaskScheduler的生命周期
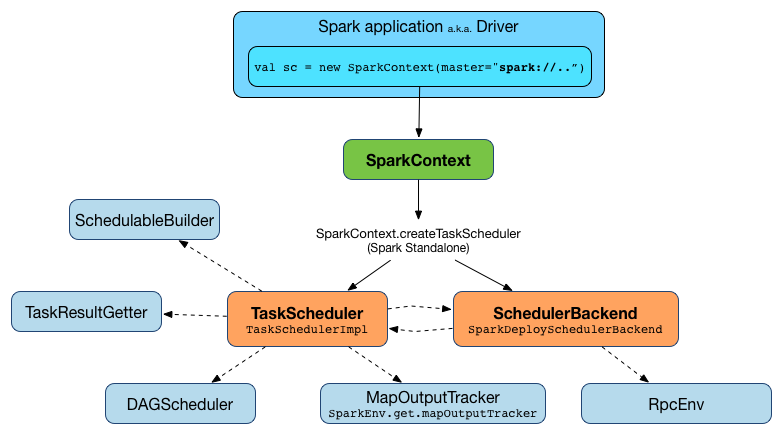
在创建SparkContext时创建 TaskScheduler(通过为给定的主URL和部署模式调用SparkContext.createTaskScheduler)。
在SparkContext的生命周期中,内部 _taskScheduler 指向 TaskScheduler(并通过向HeartbeatReceiver RPC端点发送阻塞的TaskSchedulerIsSet消息来“通知”)。
在阻塞TaskSchedulerIsSet消息收到响应后,立即启动TaskScheduler。
application ID 和 application’s attempt ID 就是此时设定的(SparkContext使用应用程序ID设置spark.app.id Spark属性,并配置SparkUI和BlockManager)。
在SparkContext完全初始化之前,调用 TaskScheduler.postStartHook。
当SparkContext被停止时,内部_taskScheduler被清除(即设置为null)。
在DAGScheduler停止时,TaskScheduler停止。
Task
Task(也叫 command)是为计算RDD分区而启动的最小的单独执行单元。
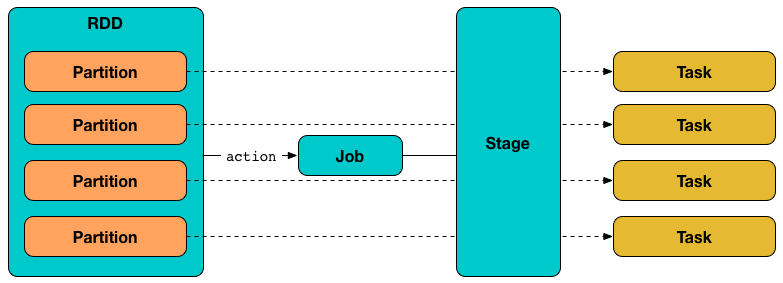
一个 task, 拥有一个 runTask 方法和一个可选的偏好引用来选择正确的 executor。
Task 有两个具体实现:
- ShuffleMapTask,执行任务并将任务的输出分成多个桶(基于任务的分区)。
- ResultTask 执行任务并将任务的输出发送回驱动程序应用程序。
Spark作业的最后一个 stage 包含多个ResultTasks,而早期 stage 只能是ShuffleMapTasks。
Task 在执行程序上启动,并在 TaskRunner 启动时运行。
用更技术性的话来说,Task 是对某个 job 中的某个 stage 中的某个 RDD 的某个分区中的记录进行计算。
任务只能属于一个阶段并在单个分区上运行。阶段中的所有任务必须在后续阶段开始之前完成。
每个 stage 和 partition 都会逐个生成任务。
run 方法
run(
taskAttemptId: Long,
attemptNumber: Int,
metricsSystem: MetricsSystem): T
run 使用本地 BlockManager 注册任务(标识为 taskAttemptId )。
运行创建一个TaskContextImpl,然后让它成为本任务的TaskContext。
运行检查_killed标志,如果启用,则终止任务(禁用interruptThread标志)。
run创建一个Hadoop CallerContext并设置它。
run运行任务。(这是执行自定义任务的runTask的时刻。)
最后,运行通知TaskContextImpl任务已完成(无论最终结果如何 - 成功或失败)。
如果出现任何异常,run 会通知TaskContextImpl任务失败。run 请求MemoryStore释放此任务的展开内存(适用于ON_HEAP和OFF_HEAP内存模式)。
run 请求MemoryManager通知任何等待执行内存的任务被释放唤醒并尝试再次获取内存。
run 取消设置任务的TaskContext。
Task 状态
- LAUNCHING
- RUNNING
- FINISHED
- FAILED
- KILLED
- LOST
Task分类
ShuffleMapTask
ShuffleMapTask 是一个计算 MapStatus 的 Task,即将RDD分区中计算记录的结果写入shuffle系统,并返回有关BlockManager 的信息和结果shuffle块的估计大小。
当 DAGScheduler 为 ShuffleMapStage 提交缺少的任务时,专门创建 ShuffleMapTask 。
ResultTask
ResultTask 是一个对RDD分区中的记录执行函数的 Task。
当 DAGScheduler 为 ResultStage 提交缺少的任务时,将专门创建 ResultTask。
ResultTask 是使用 broadcast variable 创建的,其中包含RDD和执行它的函数以及分区。
运行时异常
Task 运行时可能抛出FetchFailedException异常(并且ShuffleBlockFetcherIterator无法设法获取shuffle块)。
FetchFailedException 包含以下内容:
- BlockManager的唯一标识符(作为BlockManagerId)
shuffleIdmapIdreduceId- 一条简短的异常
message cause- root Throwable对象
报告 FetchFailedException时,TaskRunner 会捕获它并通知 ExecutorBackend(具有TaskState.FAILED任务状态)。
FetchFailedException 的根本原因通常是因为 executor(使用用于shuffle块的BlockManager)丢失(即不再可用),原因是:
- 可能抛出
OutOfMemoryError(也称为OOMed)或其他一些未处理的异常。 - 使用 Spark应用程序的执行程序管理工作程序的集群管理器,例如YARN,强制执行容器内存限制,并最终因内存使用过多而决定终止执行程序。
您应该使用 Web UI,Spark History Server或特定于群集的工具(如针对Hadoop YARN的yarn logs -applicationId)查看Spark应用程序的日志。
解决方案通常是调整Spark应用程序的内存。
Task的提交与调度
TaskSet
TaskSet 是一个 stage 中既独立又还未计算的任务的集合,也就是说这些任务的计算结果现在都还不可用。
当 DAGScheduler 被请求提交miss 的 task 时,taskset 就会被创建。
TaskSetManager
TaskSetManager是一个Schedulable,用于管理TaskSet任务的调度。
当请求 TaskSchedulerImpl 创建一个 TaskSet(当为给定的TaskSet提交任务时)时,将单独创建TaskSetManager。
先了解两个概念:
-
Schedulable 是管理 schedulableQueue 的可调度实体的抽象,并且可以 getSortedTaskSetQueue。
-
Pool是一个Schedulable实体,表示TaskSetManagers树,即它包含TaskSetManagers或其Pools的集合。
Scheduling Mode
spark.scheduler.mode 这个属性定义一个策略来对任务进行排序以便执行。
Spark中的TaskScheduler合约的唯一实现 - TaskSchedulerImpl - 使用 spark.scheduler.mode 设置来配置仅用于设置rootPool属性的scheduMode(FIFO是默认值)。 它在TaskSchedulerImpl初始化时发生。
有三种可接受的调度模式:
FIFO,它没有 pools 的概念,只有一个高 level 的未命名 pool,其元素是TaskSetManager对象FAIR,具有可调度(子)池的层次结构,其中 rootPool 位于顶部。- None 未使用