Databricks 出了本《Learning Spark》的电子书,来学习一下。
总览
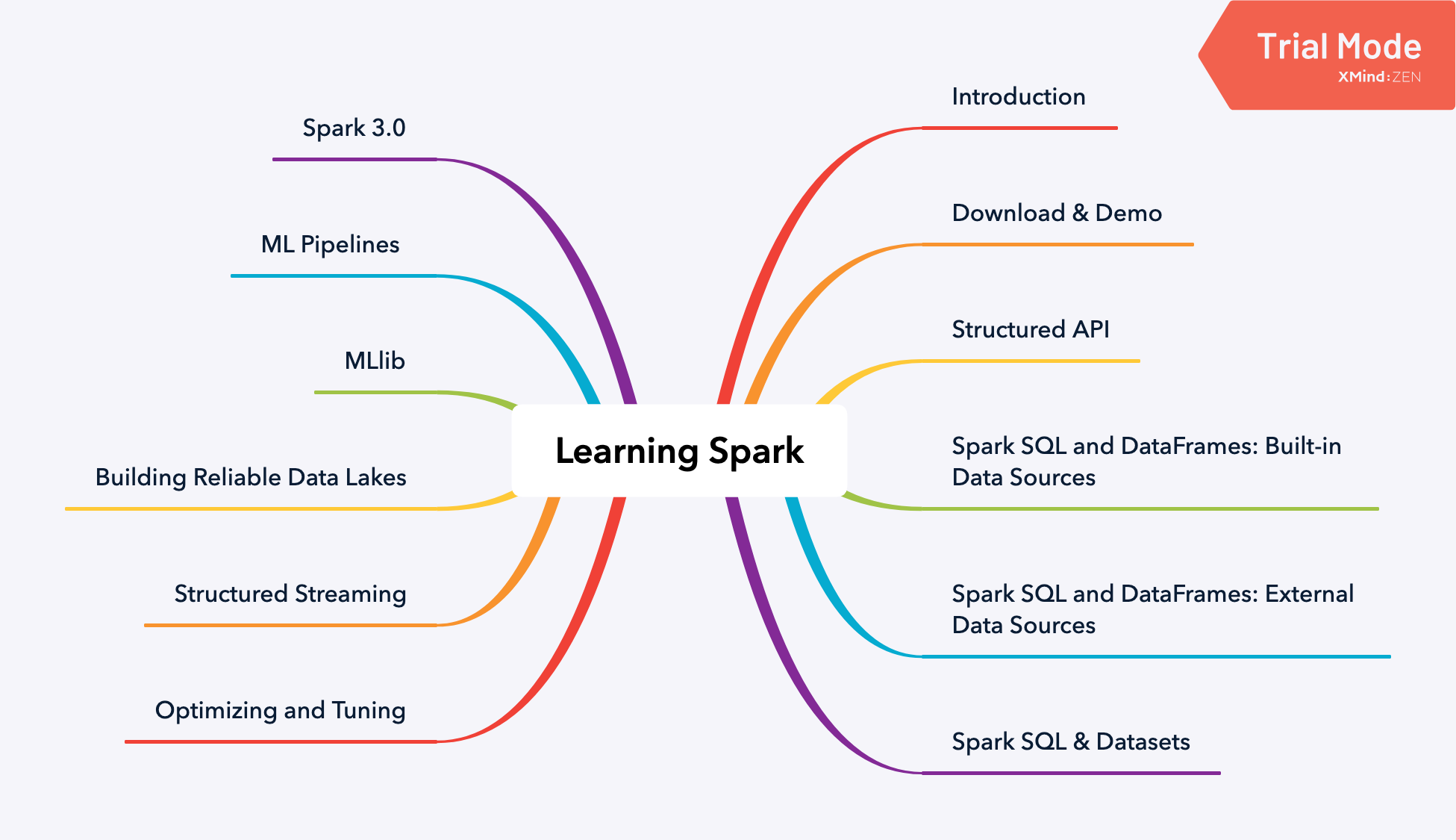
可以看出这本书总共分为五大部分,分别为:
- 基本介绍
- Spark SQL 使用与调优
- Streaming
- MLlib
- Spark 3.0 的新特性
电子书下载地址: https://databricks.com/p/ebook/learning-spark-from-oreilly
前两章非常基础,直接从第三章《Structured APIs》开始。
RDD 到底是什么?
RDD 是 Spark 最基础的抽象。它分为三部分:
- Dependencies 依赖
- Partitions 分区
- Compute funtion: Partitions => Iterator[T] 计算函数
第一部分:依赖。定义了这个RDD是从何处来的,也保证了必要时重新计算这个RDD。第二部分:partitions 分区。将数据分区存储,天然支持并行计算。第三部分计算函数可以将消费分区数据,然后得到我们想要的 Iterator[T].
整体架构简洁明了。但是也存在几个问题。其中一个就是compute function对Spark是不透明的。对于Spark来讲,compute function 只是一个 lambda expression,不管它实际上是join、filter、select。 另外一个问题是 Iterator[T] 的数据类型,对Python RDD来讲,也是透明的,Spark只知道它是一个python的 generic object。
而且,因为无法检查计算函数,那就无从谈起优化这个函数。另外因为不知道数据类型,也无法直接获取某种类型的某列,Spark 只能将它序列化为字节,而且不能使用任何压缩技术。
毫无疑问,这些不透明性,影响了Spark优化我们的计算,那么解决方案是什么呢?
结构化Spark
Spark 2.x 为结构化Spark提供了几个关键方案。
一个是在数据分析中找到的一些通用模式来表达计算。这些模式表示为high-level 处理,比如有filtering、selecting、counting、aggregating、averaging 和 grouping。这样子更清晰和简单。
通过在DSL中使用一组通用运算符,可以进一步缩小这种特异性。 通过DSL中的一组操作(可以在Spark受支持的语言(Java,Python,Spark,R和SQL)中以API的形式使用),这些运算符可以让您告诉Spark您希望对数据进行什么计算,结果, 它可以构建一个有效的执行查询计划。
最终的结构方案是允许我们以表格格式(如SQL表格或电子表格)排列数据,并使用受支持的结构化数据类型。 但是,这种结构有什么用呢?
主要优点和好处
- expressivity 表现力
- simplicity 简单性
- composability 可组合性
- uniformity 统一性
使用low-level RDD API:
# In Python
# Create an RDD of tuples (name, age)
dataRDD = sc.parallelize([("Brooke", 20), ("Denny", 31), ("Jules", 30), ("TD", 35), ("Brooke", 25)])
# Use map and reduceByKey transformations with their lambda # expressions to aggregate and then compute average
agesRDD = (dataRDD
.map(lambda x: (x[0], (x[1], 1)))
.reduceByKey(lambda x, y: (x[0] + y[0], x[1] + y[1]))
.map(lambda x: (x[0], x[1][0]/x[1][1])))
这堆lambda 函数,神秘且难读懂。同时Spark也不了解这些代码的意图。而且相同意图下,用Scala写的代码看起来也和用Python写的有很大不同。
high-level API:
# In Python
from pyspark.sql import SparkSession
from pyspark.sql.functions import avg
# Create a DataFrame using SparkSession
spark = (SparkSession
.builder
.appName("AuthorsAges")
.getOrCreate())
# Create a DataFrame
data_df = spark.createDataFrame([("Brooke", 20), ("Denny", 31), ("Jules", 30), ("TD", 35), ("Brooke", 25)], ["name", "age"])
# Group the same names together, aggregate their ages, and compute an average
avg_df = data_df.groupBy("name").agg(avg("age"))
# Show the results of the final execution
avg_df.show()
+------+--------+
| name|avg(age)|
+------+--------+
|Brooke| 22.5|
| Jules| 30.0|
| TD| 35.0|
| Denny| 31.0|
+------+--------+
不过使用high-level、表达力强的DSL 操作符,还是会有一些争议(虽然这些操作符在数据分析中很常见或是重复率很高),那就是我们限制了开发人员的控制他们请求的能力。但是请放心,Spark支持你随时切换到low-level的API中,虽然几乎没有必要。
除了易于阅读之外,Spark的高级API的结构还引入了其组件和语言之间的统一性。 例如,此处显示的Scala代码与以前的Python代码具有相同的作用-并且API看起来几乎相同:
// In Scala
import org.apache.spark.sql.functions.avg
import org.apache.spark.sql.SparkSession
// Create a DataFrame using SparkSession
val spark = SparkSession
.builder
.appName("AuthorsAges")
.getOrCreate()
// Create a DataFrame of names and ages
val dataDF = spark.createDataFrame(Seq(("Brooke", 20), ("Brooke", 25), ("Denny", 31), ("Jules", 30), ("TD", 35))).toDF("name", "age")
// Group the same names together, aggregate their ages, and compute an average
val avgDF = dataDF.groupBy("name").agg(avg("age"))
// Show the results of the final execution
avgDF.show()
正是因为Spark 构建了high-level结构化API的Spark SQL引擎,这种简单性和表达性才成为可能。由于有了此引擎,它是所有Spark组件的基础,所以我们获得了统一的API。 无论您是在结构化流式处理还是MLlib中对DataFrame表达查询,您始终都在将DataFrame转换为结构化数据并对其进行操作。
DataFrame API
受 pandas dataframe 的启发,Spark Dataframe 就像是一张分布在内存中的表格,它带有column name 和type。
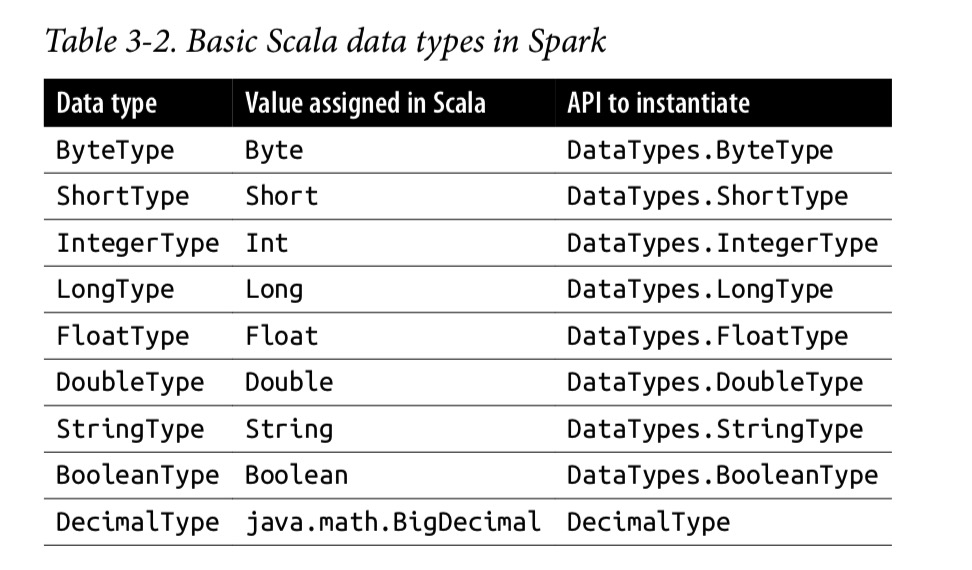
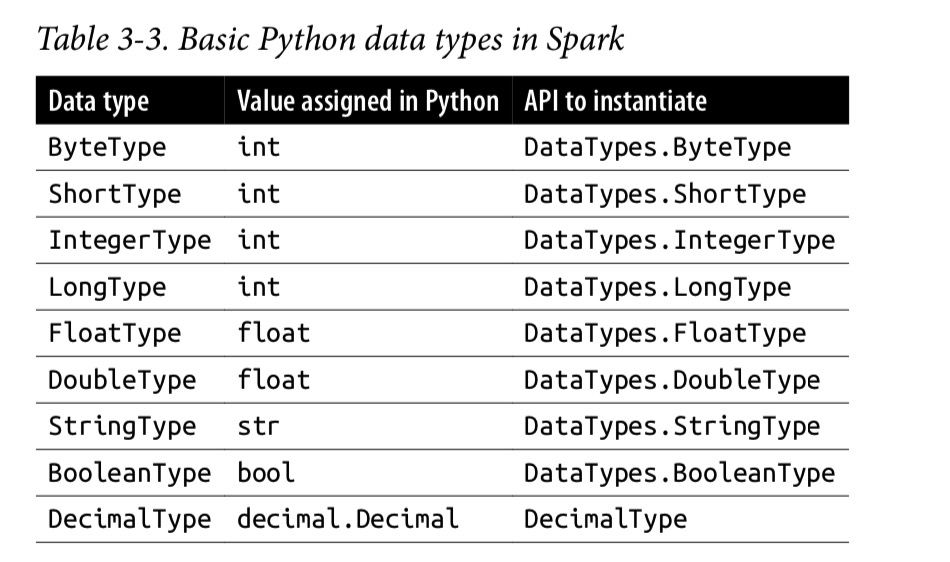
基本数据类型
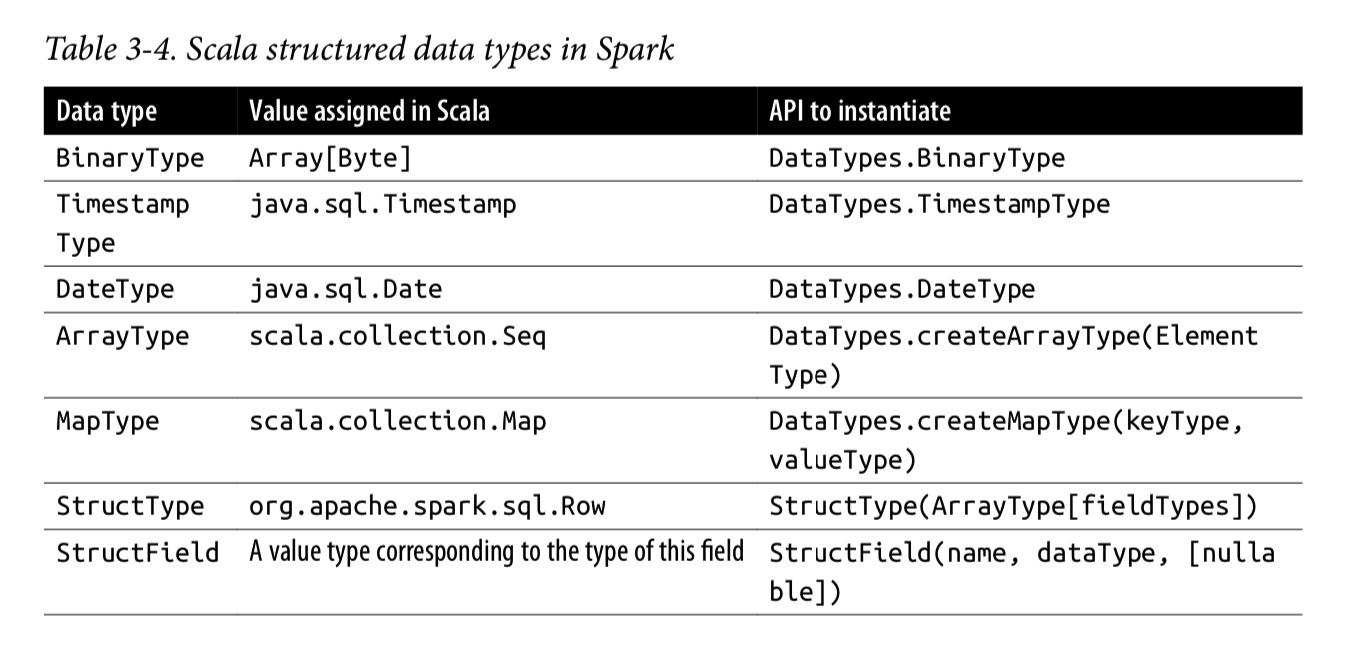
结构化的和复杂的数据类型
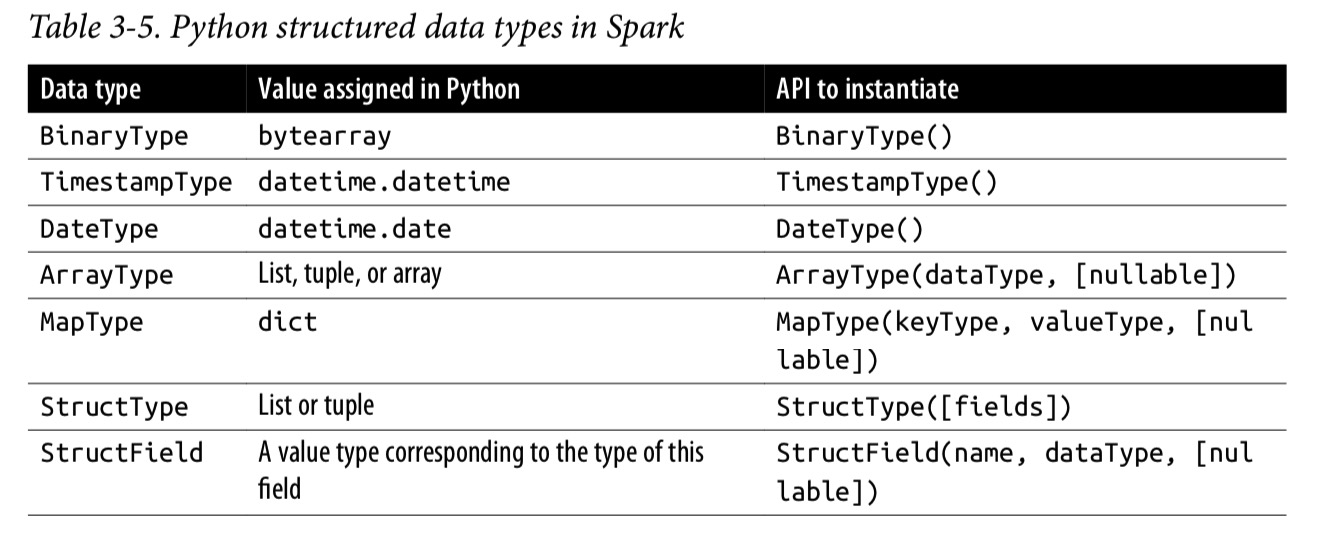
Schemas 和create DataFrame
Spark中的schema定义了DataFrame的列名和关联的数据类型。
相对于采用“读取schema”方法,预先定义schema具有三个好处:
- 您可以把 Spark 从推断数据类型的负担中释放出来。
- 您可以阻止Spark创建单独的作业,而只是为了读取文件的大部分内容以确定schema,这对于大型数据文件而言可能既昂贵又费时。
- 您可以及早发现错误,如果数据与架构不匹配。
定义 schema
Using Spark DataFrame API:
// In Scala
import org.apache.spark.sql.types._
val schema = StructType(Array(StructField("author", StringType, false),StructField("title", StringType, false), StructField("pages", IntegerType, false)))
# In Python
from pyspark.sql.types import *
schema = StructType([StructField("author", StringType(), False),
StructField("title", StringType(), False),
StructField("pages", IntegerType(), False)])
Using DDL:
// In Scala
val schema = "author STRING, title STRING, pages INT"
# In Python
schema = "author STRING, title STRING, pages INT"
df = spark.createDataFrame(data, schema)
列和表达式
Spark 也支持在column上进行逻辑转换:expr(“columnName * 5”) or (expr(“colum nName - 5”) > col(anothercolumnName)) 。
scala> import org.apache.spark.sql.functions._
scala> blogsDF.columns
res2: Array[String] = Array(Campaigns, First, Hits, Id, Last, Published, Url)
// Access a particular column with col and it returns a Column type
scala> blogsDF.col("Id")
res3: org.apache.spark.sql.Column = id
// Use an expression to compute a value
scala> blogsDF.select(expr("Hits * 2")).show(2)
// or use col to compute value
scala> blogsDF.select(col("Hits") * 2).show(2)
// Use an expression to compute big hitters for blogs
// This adds a new column, Big Hitters, based on the conditional expression
blogsDF.withColumn("Big Hitters", (expr("Hits > 10000"))).show()
// Concatenate three columns, create a new column, and show the
// newly created concatenated column
blogsDF
.withColumn("AuthorsId", (concat(expr("First"), expr("Last"), expr("Id")))) .select(col("AuthorsId"))
.show(4)
// These statements return the same value, showing that
// expr is the same as a col method call
blogsDF.select(expr("Hits")).show(2)
blogsDF.select(col("Hits")).show(2)
blogsDF.select("Hits").show(2)
// Sort by column "Id" in descending order
blogsDF.sort(col("Id").desc).show()
blogsDF.sort($"Id".desc).show()
Rows 行
创建行
// In Scala
import org.apache.spark.sql.Row
// Create a Row
val blogRow = Row(6, "Reynold", "Xin", "https://tinyurl.6", 255568, "3/2/2015",
Array("twitter", "LinkedIn"))
// Access using index for individual items blogRow(1)
res62: Any = Reynold
# In Python
from pyspark.sql import Row
blog_row = Row(6, "Reynold", "Xin", "https://tinyurl.6", 255568, "3/2/2015",
["twitter", "LinkedIn"])
# access using index for individual items
blog_row[1]
'Reynold'
Create DataFrame by rows:
// In Scala
val rows = Seq(("Matei Zaharia", "CA"), ("Reynold Xin", "CA"))
val authorsDF = rows.toDF("Author", "State")
authorsDF.show()
# In Python
rows = [Row("Matei Zaharia", "CA"), Row("Reynold Xin", "CA")]
authors_df = spark.createDataFrame(rows, ["Authors", "State"])
authors_df.show()
通用的DataFrame操作
Spark 提供 DataFrameReader 来读取各式各样的数据源来生成DataFrame,比如 JSON, CSV, Parquet, Text, Avro, ORC, etc。 同时,也提供 DataFrameWriter 来把 DataFame 写回各类数据源。
使用 DataFrameReader & DataFrameWriter
在Spark中读取和写入非常简单,因为社区提供了这些高级抽象和贡献,可以连接到各种数据源,包括常见的NoSQL存储,RDBMS,Apache Kafka和Kinesis等流引擎。
Without schema:
// In Scala
val sampleDF = spark
.read
.option("samplingRatio", 0.001)
.option("header", true)
.csv("""/databricks-datasets/learning-spark-v2/sf-fire/sf-fire-calls.csv""")
Define schema firstly:
# In Python, define a schema
from pyspark.sql.types import *
# Programmatic way to define a schema
fire_schema = StructType([StructField('CallNumber', IntegerType(), True),
StructField('UnitID', StringType(), True),
StructField('IncidentNumber', IntegerType(), True),
StructField('CallType', StringType(), True),
StructField('CallDate', StringType(), True),
StructField('WatchDate', StringType(), True),
...
...
StructField('Delay', FloatType(), True)])
# Use the DataFrameReader interface to read a CSV file
sf_fire_file = "/databricks-datasets/learning-spark-v2/sf-fire/sf-fire-calls.csv"
fire_df = spark.read.csv(sf_fire_file, header=True, schema=fire_schema)
// In Scala it would be similar
val fireSchema = StructType(Array(StructField("CallNumber", IntegerType, true),
StructField("Location", StringType, true),
...
...
StructField("Delay", FloatType, true)))
// Read the file using the CSV DataFrameReader
val sfFireFile="/databricks-datasets/learning-spark-v2/sf-fire/sf-fire-calls.csv"
val fireDF = spark.read.schema(fireSchema)
.option("header", "true")
.csv(sfFireFile)
Saving a DataFrame as a Parquet file or SQL table
你可以使用 DataFrameWriter 保持 DataFrame 到各类数据源中。 Parquet,是默认的格式。这种格式使用snappy来压缩数据,并且会将schema信息保存到metadata中,这样子下次读取这个文件的时候,就不需要手动提供schema。
保存为Parquet 文件:
// In Scala to save as a Parquet file
val parquetPath = ...
fireDF.write.format("parquet").save(parquetPath)
# In Python to save as a Parquet file
parquet_path = ...
fire_df.write.format("parquet").save(parquet_path)
保存为sql table,这个表会注册到Hive的metastore 中:
// In Scala to save as a table
val parquetTable = ... // name of the table fireDF.write.format("parquet").saveAsTable(parquetTable)
# In Python
parquet_table = ... # name of the table fire_df.write.format("parquet").saveAsTable(parquet_table)
Projections and filters
关系表达式中的projection是一种通过使用过滤器 filters 仅返回与特定关系条件匹配的行的方法。 在Spark中,投影是使用 select() 方法完成的,而过滤器可以使用 filter() 或 where() 方法来表示。
# In Python
few_fire_df = (fire_df
.select("IncidentNumber", "AvailableDtTm", "CallType")
.where(col("CallType") != "Medical Incident"))
few_fire_df.show(5, truncate=False)
// In Scala
val fewFireDF = fireDF
.select("IncidentNumber", "AvailableDtTm", "CallType")
.where($"CallType" =!= "Medical Incident")
fewFireDF.show(5, false)
重命名、添加、删除列
# In Python
fire_ts_df = (new_fire_df
.withColumn("IncidentDate", to_timestamp(col("CallDate"), "MM/dd/yyyy"))
.drop("CallDate")
.withColumn("OnWatchDate", to_timestamp(col("WatchDate"), "MM/dd/yyyy"))
.drop("WatchDate")
.withColumn("AvailableDtTS", to_timestamp(col("AvailableDtTm"),
"MM/dd/yyyy hh:mm:ss a"))
.drop("AvailableDtTm"))
# Select the converted columns
(fire_ts_df
.select("IncidentDate", "OnWatchDate", "AvailableDtTS")
.show(5, False))
// In Scala
val fireTsDF = newFireDF
.withColumn("IncidentDate", to_timestamp(col("CallDate"), "MM/dd/yyyy"))
.drop("CallDate")
.withColumn("OnWatchDate", to_timestamp(col("WatchDate"), "MM/dd/yyyy"))
.drop("WatchDate")
.withColumn("AvailableDtTS", to_timestamp(col("AvailableDtTm"), "MM/dd/yyyy hh:mm:ss a"))
.drop("AvailableDtTm")
// Select the converted columns
fireTsDF
.select("IncidentDate", "OnWatchDate", "AvailableDtTS") .show(5, false)
聚合 Aggregations
DataFrame 有很多有用的 transforma 和 action,比如 groupBy(), orderBy(), and count(),他们提供了通过列名进行聚合然后得出数量的能力。
# In Python
(fire_ts_df
.select("CallType")
.where(col("CallType").isNotNull())
.groupBy("CallType")
.count()
.orderBy("count", ascending=False)
.show(n=10, truncate=False))
// In Scala
fireTsDF
.select("CallType")
.where(col("CallType").isNotNull)
.groupBy("CallType")
.count()
.orderBy(desc("count"))
.show(10, false)
其他操作
除了上面看到的,DataFrame API 还提供了状态统计函数:min(), max(), sum(), and avg()。
# In Python
import pyspark.sql.functions as F
(fire_ts_df
.select(F.sum("NumAlarms"), F.avg("ResponseDelayedinMins"),
F.min("ResponseDelayedinMins"), F.max("ResponseDelayedinMins"))
.show())
// In Scala
import org.apache.spark.sql.{functions => F}
fireTsDF
.select(F.sum("NumAlarms"), F.avg("ResponseDelayedinMins"),
F.min("ResponseDelayedinMins"), F.max("ResponseDelayedinMins"))
.show()
Datasets API
Spark 2.0 统一了 DataFrame 和 Dataset 的API,称为 Structured API,以便开发者只需要学习一套API。Dataset 有两个部分:Untyped API和Typed API:
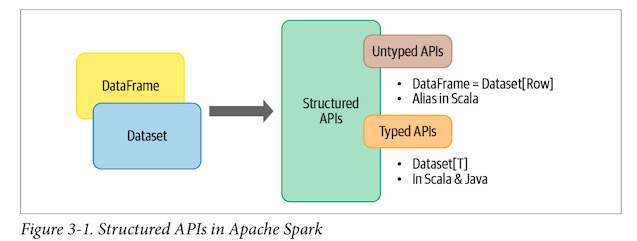
从概念上来讲,Scala 中的 DataFrame 可以被当作是一个普通对象的合集:Dataset[Row]。Row 是一个通用的、没有类型的 JVM 对象,它可以包含多个不同类型的字段。
不同的是,一个 Dataset 是一个包含强类型对象的合集,这些对象可以是 Java 中的类或者 Scala 中的JVM object。
类型对象、无类型对象和通用的Row
在 Spark 支持的语言当中, Dataset 只在 Java 、Scala 中有意义,而在 Python、R 中只有 DataFrame 有意义。这是因为 Python、R 不是编译时间类型安全的(compile-time type-safe),它的类型是在执行期间而不是在编译期间,动态推断或分配的。
在Scala和Java中则相反:在编译时将类型绑定到变量和对象。 但是,在Scala中,DataFrame只是无类型Dataset [Row]的别名。

创建 Dataset
与从数据源创建 DataFrame 一样,在创建数据集时,您必须了解shema。换句话说,您需要了解数据类型。尽管使用 JSON 和 CSV 数据可以推断架构,但对于大型数据集,这需要大量资源(非常昂贵)。在 Scala 中创建数据集时,为生成的数据集指定架构的最简单方法是使用case class。在 Java 中,使用 JavaBean 类。
Scala: Case classes
JSON file 中每一行大概是这样子:
{"device_id": 198164, "device_name": "sensor-pad-198164owomcJZ", "ip":
"80.55.20.25", "cca2": "PL", "cca3": "POL", "cn": "Poland", "latitude":
53.080000, "longitude": 18.620000, "scale": "Celsius", "temp": 21,
"humidity": 65, "battery_level": 8, "c02_level": 1408,"lcd": "red",
"timestamp" :1458081226051}
怎么把它变成 typed object:DeviceIoTData 呢?我们可以定义一个case class:
case class DeviceIoTData (battery_level: Long, c02_level: Long, cca2: String, cca3: String, cn: String, device_id: Long, device_name: String, humidity: Long, ip: String, latitude: Double, lcd: String, longitude: Double, scale:String, temp: Long, timestamp: Long)
定义之后,我们就可以直接读取文件并将返回类型 Dataset[Row] 转换为 Dataset[DeviceIoTData]:
// In Scala
val ds = spark.read
.json("/databricks-datasets/learning-spark-v2/iot-devices/iot_devices.json")
.as[DeviceIoTData]
ds: org.apache.spark.sql.Dataset[DeviceIoTData] = [battery_level...]
ds.show(5, false)
Dataset 的操作
和 DataFrame 类似,dataset也可以进行 transformations and actions。
// In Scala
val filterTempDS = ds.filter({d => {d.temp > 30 && d.humidity > 70}) filterTempDS: org.apache.spark.sql.Dataset[DeviceIoTData] = [battery_level...] filterTempDS.show(5, false)
需要注意的另一件事是,使用 DataFrames 时,fitler 像是 SQL-like 的 DSL 语言一样,但是在 Dataset 中,我们只能使用scala 或 java的原生语言表达。
// In Scala
case class DeviceTempByCountry(temp: Long, device_name: String, device_id: Long, cca3: String)
val dsTemp = ds
.filter(d => {d.temp > 25})
.map(d => (d.temp, d.device_name, d.device_id, d.cca3))
.toDF("temp", "device_name", "device_id", "cca3")
.as[DeviceTempByCountry]
dsTemp.show(5, false)
val dsTemp2 = ds
.select($"temp", $"device_name", $"device_id", $"device_id", $"cca3")
.where("temp > 25")
.as[DeviceTempByCountry]
总结一下,我们在 Dataset上进行的操作,比如 filter(), map(), groupBy(), select(), take(), etc, 和DataFrame上的很类似。 某种程度上来讲,Dataset 和 RDD 很像,它们都提供相似的接口给上述的方法以及编译时期的安全,但是Dataset的接口更安全和面向对象。
当我们使用 dataset时, Spark SQL 引擎处理 JVM object 的创建、转换、序列化和反序列化。它会在 Dataset encoder的帮助下,处理 Java 堆内存管理。
DataFrame VS Dataset
现在,您可能想知道为什么以及何时应该使用DataFrames或Dataset。 在许多情况下,哪种方法都可以,取决于您使用的语言,但是在某些情况下,一种语言比另一种语言更可取。 这里有一些例子:
- 如果您想告诉Spark该做什么而不是该怎么做,请使用DataFrames或Datasets。
- 如果您想要丰富的语义,高级抽象和DSL运算符,请使用DataFrames 或 Datasets。
- 如果您希望严格的编译时类型安全性,并且不介意为特定的数据集[T]创建多个case class,请使用dataset。
- 如果您的处理需要高级表达式,过滤器,映射,聚合,计算平均值或总和,SQL查询,列访问或对半结构化数据使用关系运算符,请使用DataFrames或Datasets。
- 如果您的处理要求与类似SQL的查询类似的关系转换,请使用DataFrames。
- 如果您想利用Tungsten的高效编码器序列化并从中受益,请使用Dataset。
- 如果要跨Spark组件进行统一,代码优化和API简化,请使用DataFrames。
- 如果您是R用户,请使用DataFrames。
- 如果您是Python用户,则在需要更多控制权时,请使用DataFrames并下拉至RDD。
- 如果需要空间和速度效率,请使用DataFrames。
- 如果要在编译期间而不是在运行时捕获错误,请选择适当的API,如下图所示:
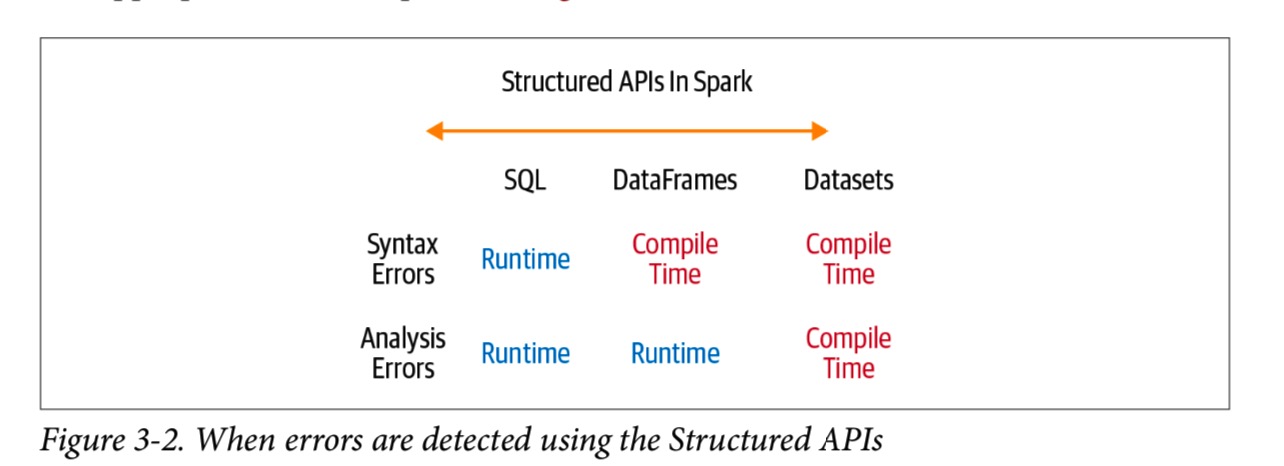
什么时候使用RDD
您可能会问:RDD是否被降级为二等公民? 他们被弃用了吗? 答案是否定的! 尽管将来在Spark 2.x和Spark 3.0中进行的所有开发工作都将继续具有DataFrame接口和语义,而不是使用RDD,但仍将继续支持RDD API。
在某些情况下,您可能需要考虑使用RDD,例如:
- 使用RDD编写的第三方程序包
- 可以放弃代码优化、高效的空间利用以及DataFrame和Dataset所提供的性能优势
- 想精确地指导Spark如何进行查询
此外,您可以使用简单的API方法调用df.rdd随意在DataFrame或Dataset和RDD之间无缝切换。 (但是,请注意,这个操作是有代价的,除非有必要,否则应避免。)毕竟,DataFrame和Dataset是建立在RDD之上的,它们在整个代码生成过程中都分解为紧凑的RDD代码。
构建高效查询并生成紧凑代码的过程是Spark SQL引擎的工作。 这是我们一直在研究的结构化API的基础。 现在让我们来窥探一下该引擎。
有个视频也讲述了 RDD/dataFrame/dataset之间的区别,可以去看一看:A Tale of Three Apache Spark APIs: RDDs, DataFrames, and Datasets - Jules Damji 。
Spark SQL 和底层引擎
Spark 1.3中引入以来,Spark SQL已经发展成为一个强大的引擎,并在其上构建了许多高级结构化功能。 除了允许您对数据发出类似SQL的查询之外,Spark SQL引擎还支持:
- 统一Spark组件,并允许抽象为Java,Scala,Python和R中的DataFrame /dataset,从而简化了结构化数据集的工作。
- 连接到Apache Hive metastore和table。
- 从结构化文件格式(JSON,CSV,文本,Avro,Parquet,ORC等)中以特定模式读取和写入结构化数据,并将数据转换为临时表。
- 提供交互式Spark SQL Shell,以快速浏览数据。
- 通过标准数据库JDBC / ODBC连接器提供与外部工具之间的桥梁。
- 生成用于JVM的优化查询计划和紧凑代码,以最终执行。
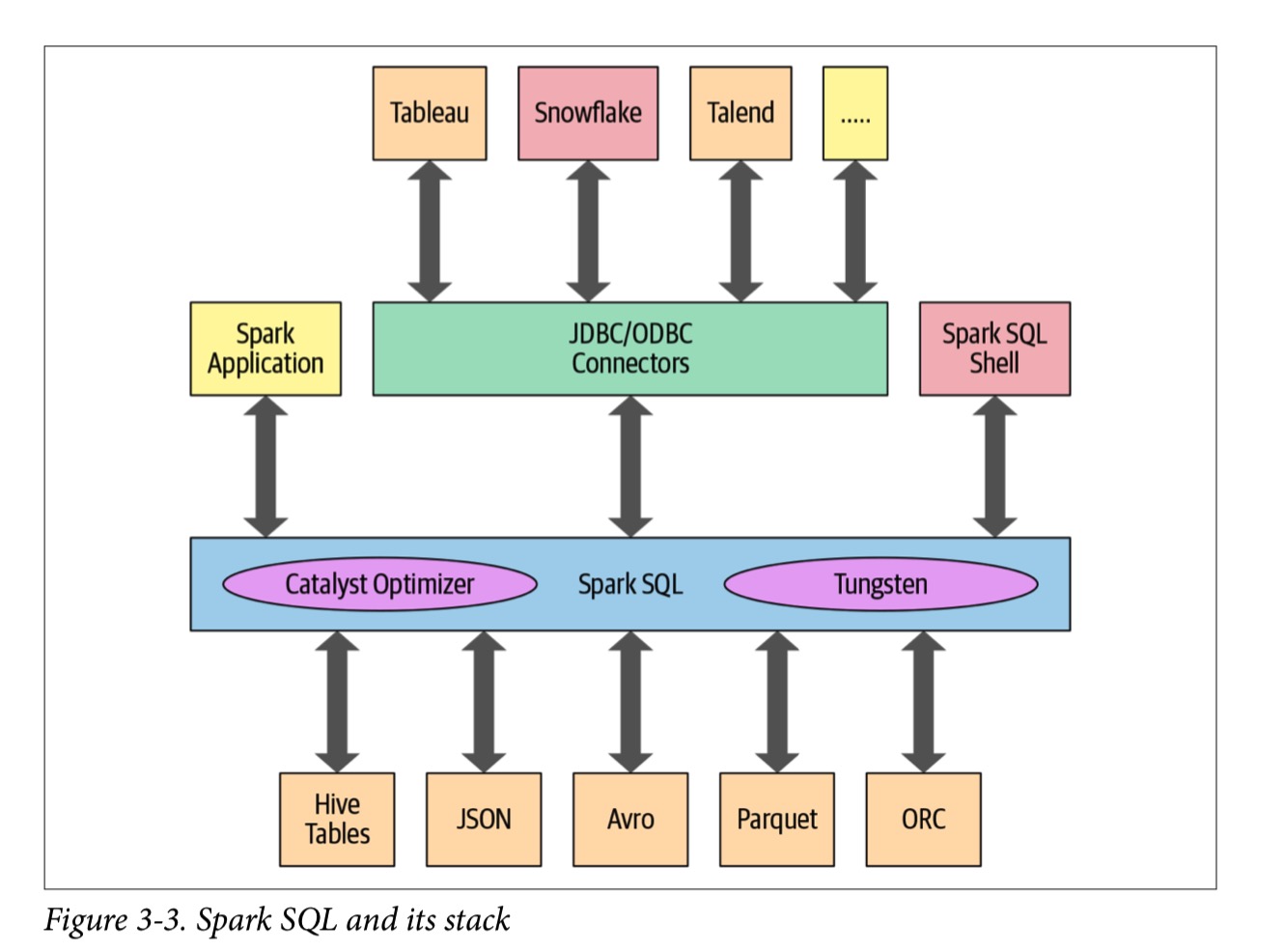
Spark SQL引擎的核心是Catalyst优化器和Project Tungsten。 它们一起支持高级DataFrame和Dataset API和SQL查询。 现在,让我们仔细看看优化器。
The Catalyst Optimizer
Catalyst Optimizer 将可执行的查询转换为一个可执行计划。它通过以下四个阶段:
- 分析 Analysis
- 逻辑优化 Logical optimization
- 物理计划 Physical planning
- 产生代码 Code generation
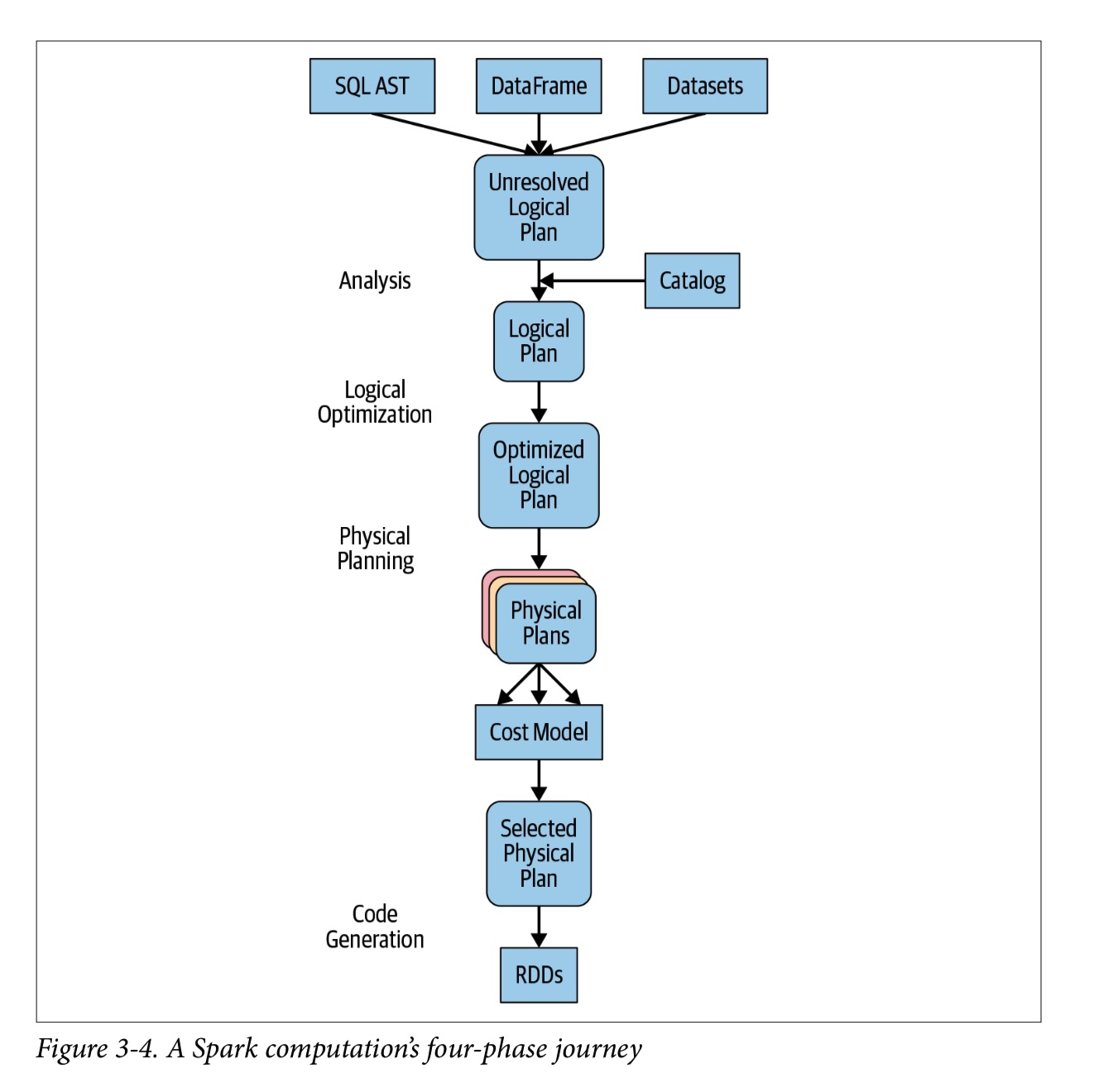
举个例子,不管你是用什么语言,都是类似的处理过程:从query plan 到 execute bytecode。
# In Python
count_mnm_df = (mnm_df
.select("State", "Color", "Count")
.groupBy("State", "Color")
.agg(count("Count").alias("Total"))
.orderBy("Total", ascending=False))
-- In SQL
SELECT State, Color, Count, sum(Count) AS Total FROM MNM_TABLE_NAME
GROUP BY State, Color, Count
ORDER BY Total DESC
在Python中,执行 count_mnm_df.explain(True) 可以查看各个阶段的计划。或者想要看逻辑计划和物理计划之间的不同,可以在scala中使用df.queryExecution.logical or df.queryExecution.optimizedPlan 。
count_mnm_df.explain(True)
== Parsed Logical Plan ==
'Sort ['Total DESC NULLS LAST], true
+- Aggregate [State#10, Color#11], [State#10, Color#11, count(Count#12) AS...]
+- Project [State#10, Color#11, Count#12]
+- Relation[State#10,Color#11,Count#12] csv
== Analyzed Logical Plan ==
State: string, Color: string, Total: bigint
Sort [Total#24L DESC NULLS LAST], true
+- Aggregate [State#10, Color#11], [State#10, Color#11, count(Count#12) AS...]
+- Project [State#10, Color#11, Count#12]
+- Relation[State#10,Color#11,Count#12] csv
== Optimized Logical Plan ==
Sort [Total#24L DESC NULLS LAST], true
+- Aggregate [State#10, Color#11], [State#10, Color#11, count(Count#12) AS...]
+- Relation[State#10,Color#11,Count#12] csv
== Physical Plan ==
*(3) Sort [Total#24L DESC NULLS LAST], true, 0
+- Exchange rangepartitioning(Total#24L DESC NULLS LAST, 200)
+- *(2) HashAggregate(keys=[State#10, Color#11], functions=[count(Count#12)], output=[State#10, Color#11, Total#24L])
+- Exchange hashpartitioning(State#10, Color#11, 200) +- *(1) HashAggregate(keys=[State#10, Color#11],
functions=[partial_count(Count#12)], output=[State#10, Color#11, count#29L]) +- *(1) FileScan csv [State#10,Color#11,Count#12] Batched: false,
Format: CSV, Location: InMemoryFileIndex[file:/Users/jules/gits/LearningSpark2.0/chapter2/py/src/... dataset.csv], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<State:string,Color:string,Count:int>
让我们考虑另一个DataFrame计算示例。 随着底层引擎优化其逻辑和物理计划,以下Scala代码也经历了类似的旅程:
// In Scala
// Users DataFrame read from a Parquet table val usersDF = ...
// Events DataFrame read from a Parquet table val eventsDF = ...
// Join two DataFrames
val joinedDF = users
.join(events, users("id") === events("uid"))
.filter(events("date") > "2015-01-01")
![]()
阶段1: 分析
Spark SQL引擎首先为SQL或DataFrame查询生成抽象语法树(AST)。 在此初始阶段,将通过查询内部catalog(Spark SQL的编程接口,其中包含列,数据类型,函数,表,数据库等的名称的列表)来解析任何列或表的名称。 成功解决后,查询将进入下一个阶段。
阶段2: 逻辑优化
这个阶段包括两个内部阶段。 应用基于标准规则(RBO)的优化方法,Catalyst优化器将首先构建一组多个计划,然后使用其基于成本的优化器(CBO)将成本分配给每个计划。 这些计划以operator trees的形式布置; 例如,它们可能包括恒定折叠,谓词下推,投影修剪,布尔表达式简化等过程。此逻辑计划是物理计划的输入。
阶段3: 物理计划
在此阶段,Spark SQL使用与Spark执行引擎中可用的物理运算符匹配的物理运算符,为选定的逻辑计划生成最佳的物理规划。
阶段4: 生成代码
查询优化的最后阶段涉及生成可在每台计算机上运行的有效Java字节码。 因为Spark SQL可以对内存中加载的数据集进行操作,所以Spark可以使用最新的编译器技术来生成代码以加快执行速度。 换句话说,它充当编译器。 Tungsten项目在此起到了重要作用,该项目可促进整个阶段的代码生成。 整个阶段的代码生成是什么? 这是一个物理查询优化阶段,它将整个查询分解为一个函数,摆脱虚拟函数调用,并使用CPU寄存器存储中间数据。 Spark 2.0中引入的第二代Tungsten引擎使用此方法生成紧凑的RDD代码以最终执行。 这种简化的策略大大提高了CPU效率和性能。