偶然发现Spark RDD 中的 sortBy 是个特殊的 transform 算子,它居然可以像 action 算子一样触发 job。 这是为什么呢?来了解了解。
背景
在深入了解 特殊的 sortBy 之前,先来理一理 Spark RDD 的基础概念。
RDD是 Spark 的基础对象 (一个类),它有很多种算子(操作函数),比如 map, mapPartitions, reduceByKey, max, collect等。算子可以分为两类:transform 和 action。
transform
map, mapPartitions, reduceByKey等就是 transform 算子。
这类算子的特征是,当你调用了它们之后,Spark 并不会立刻去进行计算,它只是记录了你需要做的操作并返回一个新的RDD。这其实就是我们为什么常说 Spark 的计算是 lazy 的根本原因。同时只记录不立刻计算也带来了另外一个好处,就是后续可以在了解所有操作后,对计算过程进行优化,比如避免重复计算、合并计算逻辑、并行计算无依赖的任务等。
action
常用的action 算子有 max, collect.
这类算子就像它的名字action一样,代表了一个动作,也就是说这时Spark 才会触发一个 Job,真正地去计算数据。当计算完成后,action 类的算子通常会返回一个非 RDD 类型的对象,比如 collect 返回一个 array, count 返回一个 long。
特殊的 sortBy
那么 sortBy 是哪类算子呢?
先从源代码看起(code 来自 spark branch-3.0 分支,文后如无特殊说明,code默认均来自此分支):
def sortBy[K](
f: (T) => K,
ascending: Boolean = true,
numPartitions: Int = this.partitions.length)
(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T] = withScope {
this.keyBy[K](f)
.sortByKey(ascending, numPartitions)
.values
}
可以看到 sortBy 的返回类型是 RDD[T] ,所以它应该是个 transform 算子。嗯,没有问题,那接下来打开 spark-shell 来跑一个例子。
$ ./bin/spark-shell
> val a = sc.parallelize(1.to(100)).map(x => (x, x))
> val b = a.sortBy(_._1)
> val c = b.collect()
这个例子很简单,就是造了一个 rdd ,对它进行 sortBy 操作,然后collect 操作。按道理,只有一个action 算子 collect,那么 Spark 只会创建一个 job 才是。
那么打开 Spark UI, 来看一看:
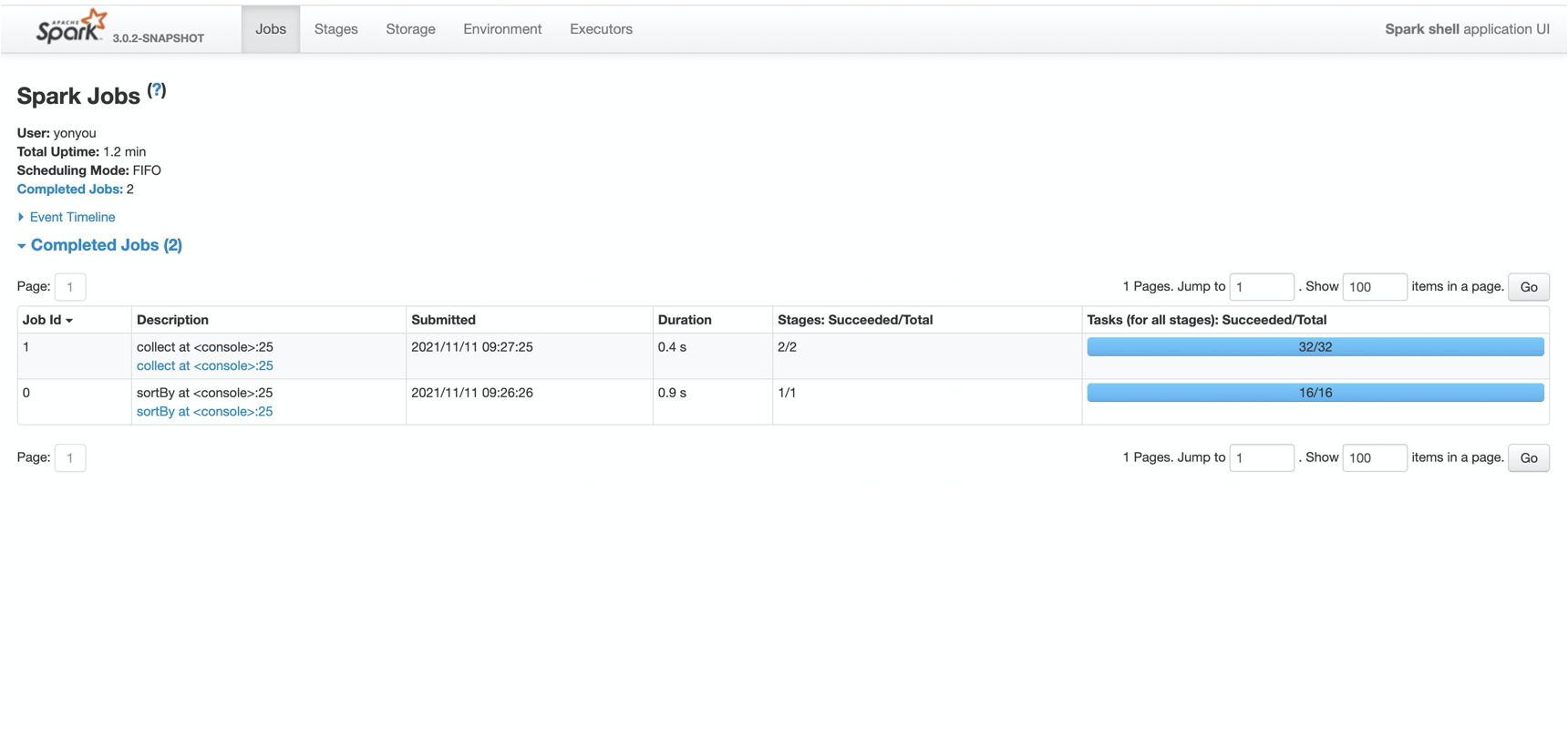
咦? 为什么有两个job 呢? 莫非 sortBy 不是 transform?
再看排序算法
在回答上面问题之前,先来重温一下排序算法,比如:
- Insertion sort
- Merge sort
- Heap sort
- Quick sort
- ……
它们是数据结构与算法中的必经之路,但本篇文章不会谈各种算法的具体细节。只是想由此引起大家一个思考,就是这些算法都有一个没有声明的默认前提,即在单个节点上可以存放所有的排序数据,不管是基于内存,还是基于硬盘的。
但是在大数据的情况下,数据多到不能放在一个节点下,这时候该使用什么算法进行排序呢?
分布式系统下的排序算法
来思考一下上面这个问题。
以 Spark RDD 为例,现在我们有一个 RDD , 它的值包含1到9,但是是打乱顺序在3个partition下的:
[2,7,5]
[3,4,8]
[9,1,6]
然后我们想让它的值从小到大排序,该怎么办呢?
先把这个RDD的所有数据想象成一个线段,如果我们想把它均匀分成 2 段,我们找到中点就好,然后比中点大的放右边,比中点小的放左边,然后再分别进行排序,这个时候我们就得到了一个全局看起来是有序的2 个partition的 RDD。
那我们想得到3个partition的有序 RDD怎么办呢?那就找到2个点,将数据平分成3块。同理,想得到 n 个 partition,就可以找到 n-1 点,它们可以将数据均匀的分为n块。
适用到上面的例子中,就是要找到一个array [3, 6],然后以它为标准,进行数据的分配。假设我们已经找到了这个array,那么第一个partition [2,7,5] 中进行循环时, 2 <= 3,那就把2分配到下游的 0 号partition 里,7 > 6, 分配到 2 号partition,3 < 5 <= 6, 所以 5 分配到第 1 号partition 上。以此类推到剩下的所有数据,我们就可以将这个数据按照相对大小分到不同的partition中,接着在单个partition里进行sort就可以得到下面结果:
[1,2,3]
[4,5,6]
[7,8,9]
仔细想一想,这其实就是分而治之的思想。”治“ 很好想,就是单节点排序,可如何找到”分“的基准 array 才是重点。
那么分布式系统下的排序问题,就可以换成另外一个问题:如何找到分区基准array ?来看看 Spark 是怎么做的吧。
sortBy 的源代码阅读
0. 总览
sortBy 的主要复杂的地方,都是在 RangePartitioner 这个类中实现的,主要分为3步:
- 抽样所有partition的数据
- 根据抽样数据得到分区基准array
- 根据分区基准array 对数据分区
前两步都是 RangePartitioner 的 rangeBounds变量初始化时实现的,最后一步则是在 getPartition 函数里实现的。
1. 抽样所有partition的数据
为什么要抽样呢? 因为数据量太大,所以先对数据进行抽样,获取一个尽可能可以代表整体数据分布的小数据集。对应在代码中就是:
// RangePartitioner.rangeBounds
private var rangeBounds: Array[K] = {
......
val (numItems, sketched) = RangePartitioner.sketch(rdd.map(_._1), sampleSizePerPartition)
......
RangePartitioner.determineBounds(candidates, math.min(partitions, candidates.size))
......
}
numItems 就是这个 RDD 的数据量,等同于运行 rdd.count(), sketched 就是抽样出来的数据,类型为 Array[(partition_id, partition_size, sample_data )]。
// RangePartitioner.sketch
def sketch[K : ClassTag](
rdd: RDD[K],
sampleSizePerPartition: Int): (Long, Array[(Int, Long, Array[K])]) = {
val shift = rdd.id
// val classTagK = classTag[K] // to avoid serializing the entire partitioner object
val sketched = rdd.mapPartitionsWithIndex { (idx, iter) =>
val seed = byteswap32(idx ^ (shift << 16))
val (sample, n) = SamplingUtils.reservoirSampleAndCount(
iter, sampleSizePerPartition, seed)
Iterator((idx, n, sample))
}.collect()
val numItems = sketched.map(_._2).sum
(numItems, sketched)
}
请大家注意到这里有一个 rdd.mapPartitionsWithIndex(....).collect(),collect 就是一个典型 action 啊。这里就回答了本篇的第一个问题,为什么当你调用 sortBy 的时候,会产生一个job,因为 sortBy 在初始化 RangePartitioner 的时候,会触发一个 collect 动作,正是由这个算子才产生了job。
解决了这个问题之后,回过头来再看每个partition里跑的抽样算法:
val (sample, n) = SamplingUtils.reservoirSampleAndCount(iter, sampleSizePerPartition, seed)
这个抽样算法叫做 Reservoir sampling ,中文翻译为”水塘抽样“。其目的在于从包含n个项目的集合S中选取k个样本,并保证每个样本被选取的概率都为 1/n。 这个算法用伪代码写出来就是下面这个样子:
for (i in S) {
if(rand(i) < k) {
result.add($i)
}
}
Spark的实现如下:
/**
* Reservoir sampling implementation that also returns the input size.
*
* @param input input size
* @param k reservoir size
* @param seed random seed
* @return (samples, input size)
*/
def reservoirSampleAndCount[T: ClassTag](
input: Iterator[T],
k: Int,
seed: Long = Random.nextLong())
: (Array[T], Long) = {
val reservoir = new Array[T](k)
// Put the first k elements in the reservoir.
var i = 0
while (i < k && input.hasNext) {
val item = input.next()
reservoir(i) = item
i += 1
}
// If we have consumed all the elements, return them. Otherwise do the replacement.
if (i < k) {
// If input size < k, trim the array to return only an array of input size.
val trimReservoir = new Array[T](i)
System.arraycopy(reservoir, 0, trimReservoir, 0, i)
(trimReservoir, i)
} else {
// If input size > k, continue the sampling process.
var l = i.toLong
val rand = new XORShiftRandom(seed)
while (input.hasNext) {
val item = input.next()
l += 1
// There are k elements in the reservoir, and the l-th element has been
// consumed. It should be chosen with probability k/l. The expression
// below is a random long chosen uniformly from [0,l)
val replacementIndex = (rand.nextDouble() * l).toLong
if (replacementIndex < k) {
reservoir(replacementIndex.toInt) = item
}
}
(reservoir, l)
}
}
2. 根据抽样数据得到分区基准array
上一步结束之后,我们获得了一个 (numItems, sketched),然后只要将 sketched 中所有的数据拿出来排个序,然后根据 target partition number 进行分段就可以了。这些工作由 RangePartitioner.determineBounds完成。
// RangePartitioner.rangeBounds
private var rangeBounds: Array[K] = {
......
val (numItems, sketched) = RangePartitioner.sketch(rdd.map(_._1), sampleSizePerPartition)
......
RangePartitioner.determineBounds(candidates, math.min(partitions, candidates.size))
......
}
但是在 determineBounds 之前,spark 还做了两件事:
- 处理不平衡的分区
- 准备 weight
处理不平衡的分区
如果上游的数据不是均匀分布在分区当中的,那么抽样出来的不能代表最广泛的数据。比如一个分区一共100条数据,我们抽样出 10条,抽样率为 10/100 = 1/10 , 但另外一个分区一共 10 w条数据,但是我们依然抽样出 10条数据,那么这个大分区的抽样率就只有 10 / 10w = 1/1w ,比起其他分区来讲太小了,那就不能公平的代表这个大分区。
Spark的做法是找到这些不均匀的partition,对它们再调用一次 rdd.sample:
if (imbalancedPartitions.nonEmpty) {
// Re-sample imbalanced partitions with the desired sampling probability.
val imbalanced = new PartitionPruningRDD(rdd.map(_._1), imbalancedPartitions.contains)
val seed = byteswap32(-rdd.id - 1)
val reSampled = imbalanced.sample(withReplacement = false, fraction, seed).collect()
val weight = (1.0 / fraction).toFloat
candidates ++= reSampled.map(x => (x, weight))
}
有意思的来了,这里又出现了一次 collect,换句话说就是,如果你对一个不均匀的rdd调用 sortBy,它会触发 2 个 job !一个是抽样阶段,一个是构建分区基准array前的准备阶段。
准备 weight
这个是另外一个有意思地方,spark 为了使sortBy 之后rdd的分区数量尽量平均,它并不是简单的抽样出一堆数据直接排序,然后均分这个数组即可。它引入了另一层维度,就是每个抽样出的数字,它能代表多少未抽出来的数据量,code里叫做 weight。那该如何得到这个数字呢?就是用 partition 的count n 除以 sample的长度:
val weight = (n.toDouble / sample.length).toFloat
这个weight 将在下一步起到重要作用。
determineBounds
思路也非常清晰简单,就是先把candidates 按数据本身的值进行排序:
val ordered = candidates.sortBy(_._1)
然后算出每一分区的权重步长:
val sumWeights = ordered.map(_._2.toDouble).sum
val step = sumWeights / partitions
最后根据这个标准 step,找到各个基准点:
while ((i < numCandidates) && (j < partitions - 1)) {
val (key, weight) = ordered(i)
cumWeight += weight
if (cumWeight >= target) {
// Skip duplicate values.
if (previousBound.isEmpty || ordering.gt(key, previousBound.get)) {
bounds += key
target += step
j += 1
previousBound = Some(key)
}
}
i += 1
}
整个code如下:
/**
* Determines the bounds for range partitioning from candidates with weights indicating how many
* items each represents. Usually this is 1 over the probability used to sample this candidate.
*
* @param candidates unordered candidates with weights
* @param partitions number of partitions
* @return selected bounds
*/
def determineBounds[K : Ordering : ClassTag](
candidates: ArrayBuffer[(K, Float)],
partitions: Int): Array[K] = {
val ordering = implicitly[Ordering[K]]
val ordered = candidates.sortBy(_._1)
val numCandidates = ordered.size
val sumWeights = ordered.map(_._2.toDouble).sum
val step = sumWeights / partitions
var cumWeight = 0.0
var target = step
val bounds = ArrayBuffer.empty[K]
var i = 0
var j = 0
var previousBound = Option.empty[K]
while ((i < numCandidates) && (j < partitions - 1)) {
val (key, weight) = ordered(i)
cumWeight += weight
if (cumWeight >= target) {
// Skip duplicate values.
if (previousBound.isEmpty || ordering.gt(key, previousBound.get)) {
bounds += key
target += step
j += 1
previousBound = Some(key)
}
}
i += 1
}
bounds.toArray
}
3. 根据分区基准array 对数据分区
这个主要参考函数 getPartiton 。需要提及的只有一点,spark 在搜索的时候做了一个优化,那就是当 rangeBounds.length <= 128 时,使用 暴力搜索,就是一个个看,但是如果 rangeBounds.length > 128, 就用二分法来搜索从而加快搜索速度。
总结
本来是为了找出为什么 sortBy 也会触发 job的原因,但是最终却引出了另外一个问题,那就是一个普普通通的排序算法,在单节点和分布式两种情况下,解决问题的思路也要发生巨大的变化,这是一个值得关注和思考的地方。
参考
- Spark source code from Github
- https://en.wikipedia.org/wiki/Sorting_algorithm
- https://www.jianshu.com/p/d9fd44781a32