先在ubuntu下安装一下Spark。
安装
1. 下载压缩包
第一步是选择适当版本的压缩包,可以到官网进行下载。
截至到2018年2月,Spark最新版本是2.3.0版本。
然后下载压缩包到自己的目录下就好。
2. 配置环境
下载压缩包的时候,来配置一下环境。
先看看官方文档,里面有句关于环境依赖的说明:
Spark runs on Java 8+, Python 2.7+/3.4+ and R 3.1+. For the Scala API, Spark 2.3.0 uses Scala 2.11. You will need to use a compatible Scala version (2.11.x).
Note that support for Java 7, Python 2.6 and old Hadoop versions before 2.6.5 were removed as of Spark 2.2.0. Support for Scala 2.10 was removed as of 2.3.0.
也就是说,Spark 2.3.0 的其他语言版本要求是: 2.11.x的Scala,Java 8+,Python 2.7+或者3.1+, R 要3.1+。
根据自己常用开发语言安装即可。
参考如下:
2. 解压
tar xzf spark-2.3.0-bin-hadoop2.7.tgz
3. 设置环境变量
Spark需要两个环境变量: JAVA_HOME 和 SPARK_HOME
在ubuntu下,直接编辑用户目录下的 .bashrc即可:
export JAVA_HOME=<path-to-the-root-of-your-Java-installation> (eg: /usr/lib/jvm/java-7-oracle/)
export SPARK_HOME=<path-to-the-root-of-your-spark-installation> (eg: /path/spark/in/spark-1.6.1-bin-hadoop2.6/)
4. 检验是否成功
进入到解压目录下,执行
./bin/spark-shell
即可进入spark命令行界面。
然后也可以打开 http://localhost:4040 ,通过web UI查看任务情况。
配置开发环境
我自己使用的是IDEA, 所以介绍一下IDEA中如何创建Spark项目。
1. 安装IDEA
这一步网上很多教程,可以自己搜一下。
2. 创建项目

在初始页面,点击 Create New Project ,或者在已经打开的项目的左上角点击File -> New -> Project ,可以看到以下画面:
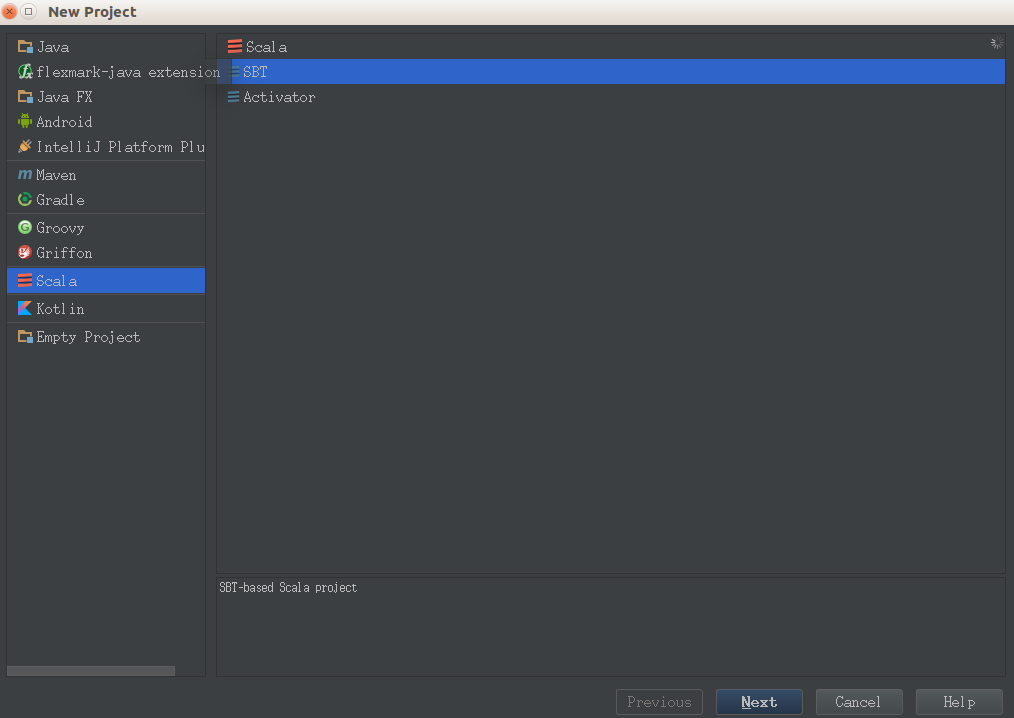
选择 Scala -> SBT , 然点击 Next。 (SBT 是一个互动式的编译工具,详细了解看到 官网 查看。)
然后给自己的项目取个名字,接着再根据自己Spark版本,选择合适的Java、Scala版本,最后点击 Finish 即可。

3. 配置项目
这一步介绍怎么引入Spark的依赖。
进入项目后,点击左上角 File -> Project Structure.
点击 Libraries ,然后点 绿色的加号。这时出现了三个选项: Java, Maven, Scala SDk。
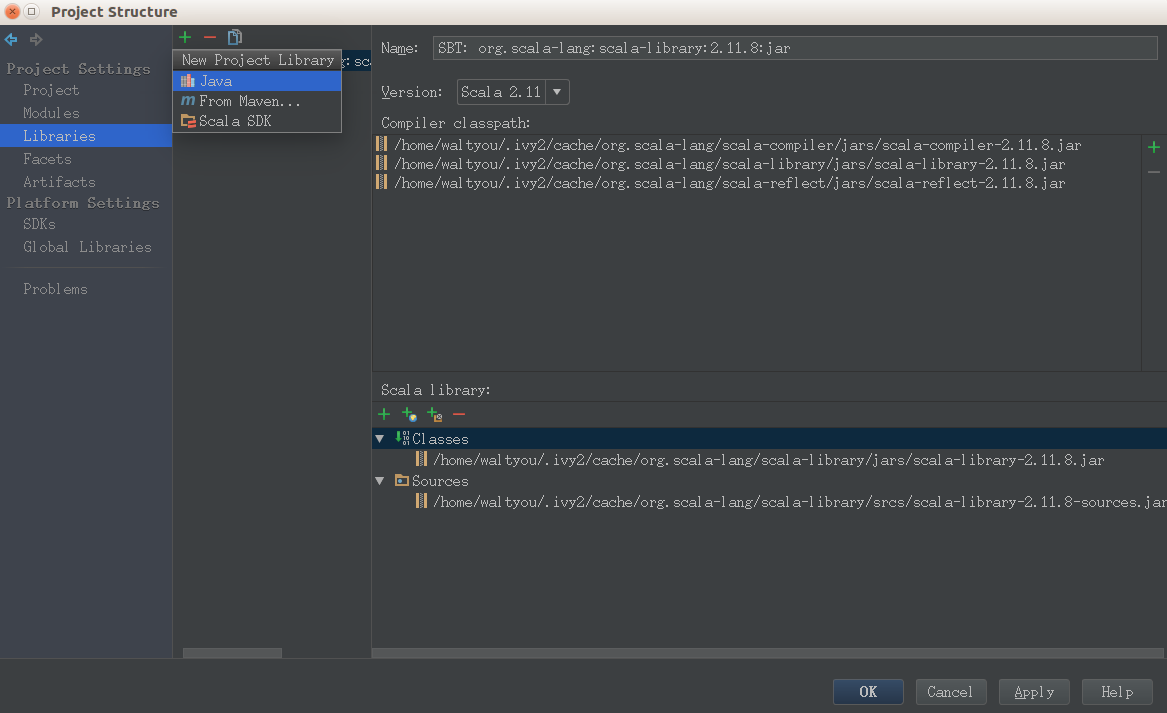
如果你选择maven方式添加spark,可以参考这里,来获取 对于的maven链接。形如:org.apache.spark:spark-core_2.11:2.3.1
当然,如果你已经下载好了Spark的压缩包,并且已经解压了,那就可以用引入Jar包的方式引入Spark,只要选择spark解压目录下名为jars的目录就OK了。
注意添加library时,要添加给两个默认的module。
4. Hello World
1)创建包
在对应 src/main/scala 目录下,创建自己的包:org.apache.spark.examples。
2 )创建Scala文件
然后选中这个包下,右键点击 New ,选择 Scala Class。
然后取名为:PiTest, kind记得选为 Object。
代码附上如下:
package org.apache.spark.examples
import org.apache.spark.sql.SparkSession
import scala.math.random
/**
* Created by waltyou on 18-6-13.
*/
object PiTest {
def main(args: Array[String]) {
val spark = SparkSession
.builder
.appName("Spark Pi")
.getOrCreate()
val slices = if (args.length > 0) args(0).toInt else 2
val n = math.min(100000L * slices, Int.MaxValue).toInt // avoid overflow
val count = spark.sparkContext.parallelize(1 until n, slices).map { i =>
val x = random * 2 - 1
val y = random * 2 - 1
if (x * x + y * y <= 1) 1 else 0
}.reduce(_ + _)
println(s"Pi is roughly ${4.0 * count / (n - 1)}")
spark.stop()
}
}
3)配置VM参数
别急着运行,spark在运行的时候,会去读取一个环境变量,叫做“spark.master”。
传递给spark的master url可以有如下几种:
- local 本地单线程
- local[K] 本地多线程(指定K个内核)
- local[*] 本地多线程(指定所有可用内核)
- spark://HOST:PORT 连接到指定的 Spark standalone cluster master,需要指定端口。
- mesos://HOST:PORT 连接到指定的 Mesos 集群,需要指定端口。
- yarn-client客户端模式 连接到 YARN 集群。需要配置 HADOOP_CONF_DIR。
- yarn-cluster集群模式 连接到 YARN 集群。需要配置 HADOOP_CONF_DIR。
我们在本地运行,就可以选为local模式。
点击Run -> Edit Configuration,在 VM Options 中添加变量。
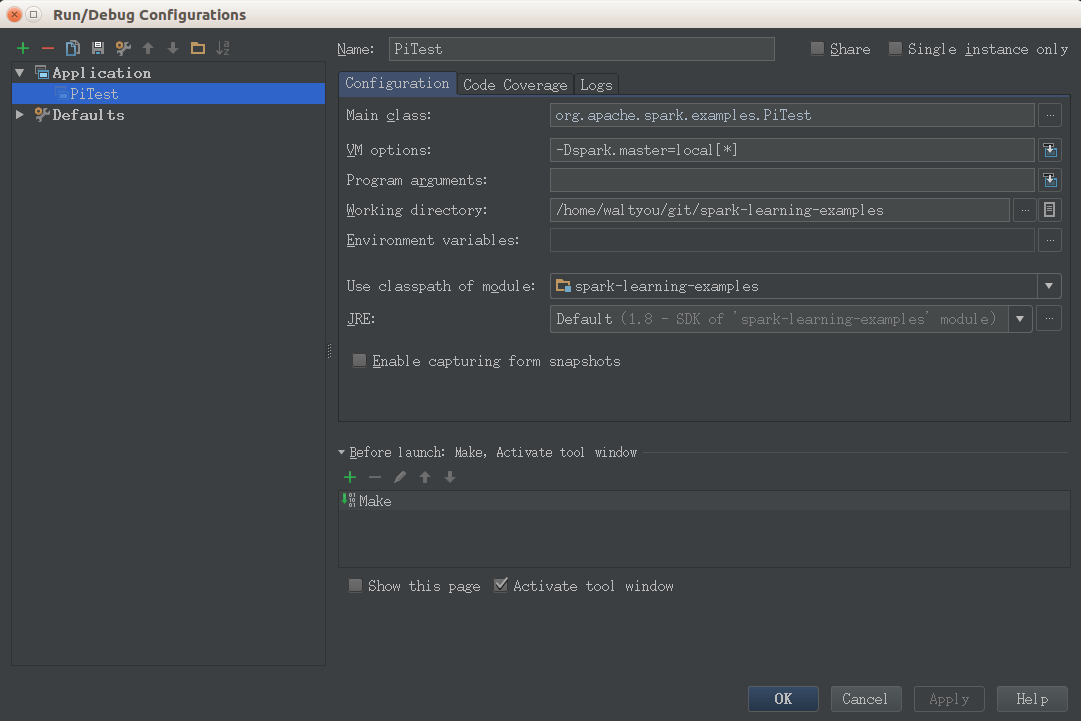
或者直接在代码中指定:
val spark = SparkSession
.builder
.config("spark.master", "local")
.appName("Spark Pi")
.getOrCreate()
4)运行
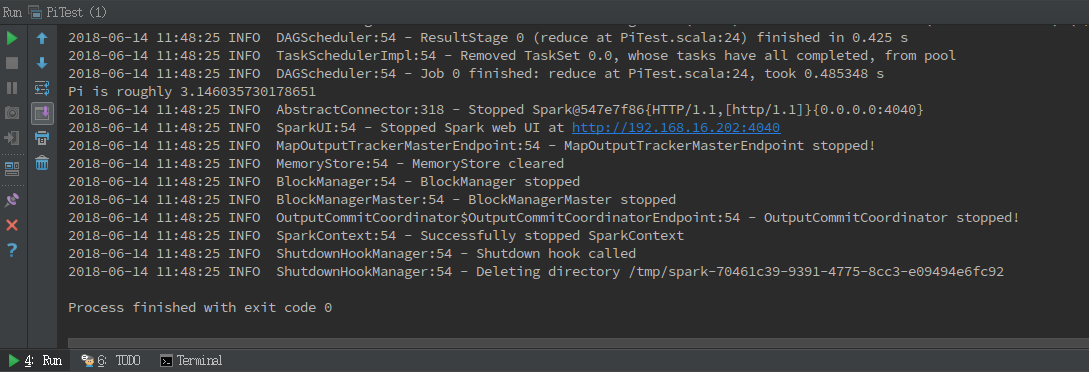
最后,右键选择 Run PiTest ,然后就可以看到输出了。
部分日志如下: