Spark Core 中有一些重要的服务,比如 SparkEnv 、DAGScheduler 、TaskScheduler 等。
SerializerManager
创建 SparkEnv(驱动程序或执行程序)时,它会实例化 SerializerManager,然后用它创建 BlockManager。
SerializerManager 自动为 shuffle block 选择“最佳”序列化器(serializer)。当已知RDD的类型与 Kryo 兼容时,它是KryoSerializer,否则为默认的Serializer。
Spark代码中常见的习惯用法是使用 SparkEnv 来访问 SerializerManager:
SparkEnv.get.serializerManager
SerializerManager 将自动为密钥、值和/或组合器类型是基元、基元数组或字符串的 ShuffledRDD 选择Kryo序列化程序。
设置
| Name | Default value | Description |
|---|---|---|
spark.shuffle.compress |
true | 控制是否在存储时压缩shuffle输出的标志 |
spark.rdd.compress |
false | 存储序列化时控制是否压缩RDD分区的标志。 |
spark.shuffle.spill.compress |
true | 控制是否压缩shuffle输出的标志暂时溢出到磁盘。 |
spark.block.failures.beforeLocationRefresh |
5 | |
spark.io.encryption.enabled |
false | 启用IO加密的标志 |
MemoryManager
MemoryManager 是给执行任务、block 存储进行内存管理的基本内存管理者。
package org.apache.spark.memory
abstract class MemoryManager(...) {
// only required methods that have no implementation the others follow
def acquireExecutionMemory(
numBytes: Long,
taskAttemptId: Long,
memoryMode: MemoryMode): Long
def acquireStorageMemory(blockId: BlockId, numBytes: Long, memoryMode: MemoryMode): Boolean
def acquireUnrollMemory(blockId: BlockId, numBytes: Long, memoryMode: MemoryMode): Boolean
def maxOffHeapStorageMemory: Long
def maxOnHeapStorageMemory: Long
}
方法
acquireExecutionMemory
在TaskMemoryManager 被请求获取 ExecutionMemory时专门使用
acquireStorageMemory
在以下场景使用:
- UnifiedMemoryManager 被 acquireUnrollMemory 调用
- MemoryStore 被 putBytes, putIteratorAsValues 和 putIteratorAsBytes 调用
acquireUnrollMemory
仅在 MemoryStore 被 UnrollMemoryForThisTask 请求时使用
maxOffHeapStorageMemory
在以下场景使用:
- UnifiedMemoryManager 被 acquireStorageMemory调用
- BlockManager 被创建时
- MemoryStore 被请求获取可用于存储的总内存量(以字节为单位)时
maxOnHeapStorageMemory
在以下场景使用:
- BlockManager 被创建时
- UnifiedMemoryManager 被 acquireStorageMemory 调用
- MemoryStore 被请求获取可用于存储的总内存量(以字节为单位)时
- (遗留)创建 StaticMemoryManager 时,被 acquireStorageMemory 调用
其他
MemoryManager与SparkEnv一起创建。
Execution memory 用于在shuffles, joins, sorts 和 aggregations 中的计算。
Storage memory 用于在群集中的节点之间缓存和传播内部数据。
创建 MemoryManager 实例
MemoryManager 在创建时执行以下:
- SparkConf
- CPU 核心数量
onHeapStorageMemoryonHeapExecutionMemory
MemoryManager 初始化内部注册表和计数器。
SparkEnv
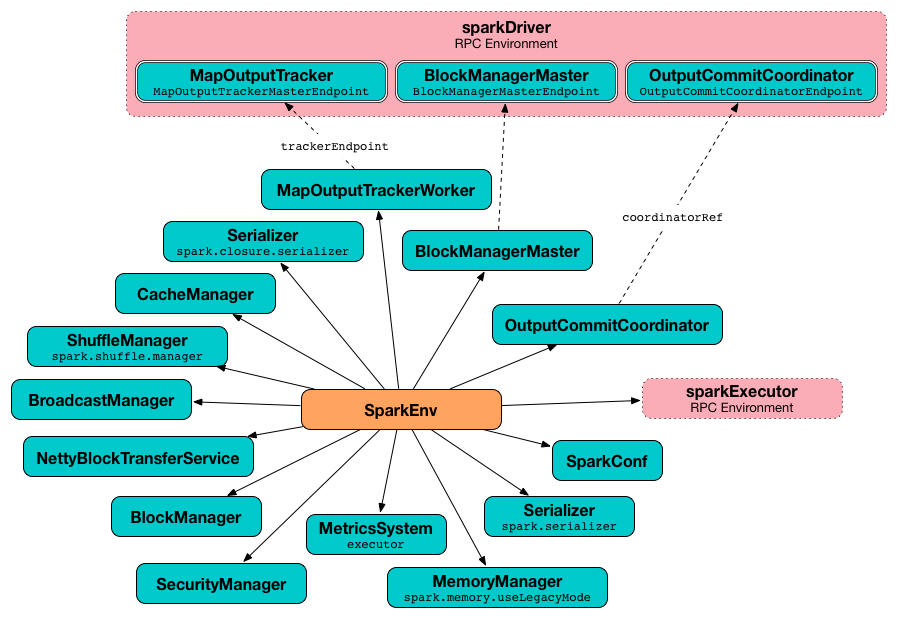
Spark Runtime Environment (SparkEnv) 是Spark 公共服务们相互交互,用来给 Spark 应用程序建立分布式计算平台的运行时环境。
Spark Runtime Environment 由SparkEnv对象表示,该对象为运行的Spark应用程序保存所有必需的运行时服务,并为驱动程序和执行程序提供单独的环境。
Spark 在驱动程序或执行程序上访问当前 SparkEnv 的惯用方法是使用 get 方法。
SparkEnv.get
包含的属性:rpcEnv、serializer、closureSerializer、serializerManager、mapOutputTracker、shuffleManager、broadcastManager、blockManager、securityManager、metricsSystem、memoryManager、outputCommitCoordinator。
SparkEnv 工厂对象
create 方法:
create(
conf: SparkConf,
executorId: String,
hostname: String,
port: Int,
isDriver: Boolean,
isLocal: Boolean,
numUsableCores: Int,
listenerBus: LiveListenerBus = null,
mockOutputCommitCoordinator: Option[OutputCommitCoordinator] = None): SparkEnv
create 是一个内部帮助器方法,用于创建“基础” SparkEnv(用于 driver 或 executor)。
当被执行时,create 方法创建一个 Serializer(基于 spark.serializer 配置)。
它创建一个闭包Serializer(基于spark.closure.serializer)。
它基于 spark.shuffle.manager 属性创建一个 ShuffleManager。
它基于 spark.memory.useLegacyMode 设置,创建 MemoryManager(其中UnifiedMemoryManager是默认值,numCores是输入numUsableCores)。
它使用以下端口创建 NettyBlockTransferService:
- spark.driver.blockManager.port 为 driver (默认值:0)
- spark.blockManager.port 为 executor(默认值:0)
它使用 NettyBlockTransferService 创建 BlockManager。
它使用 BlockManagerMaster RPC端点引用(通过按名称和BlockManagerMasterEndpoint注册或查找)、输入 SparkConf 和输入 isDriver 标志,来创建BlockManagerMaster对象。
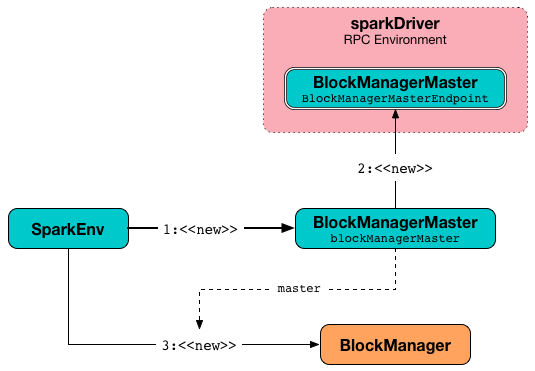
它为 driver 注册 BlockManagerMaster RPC端点并查找 executors。
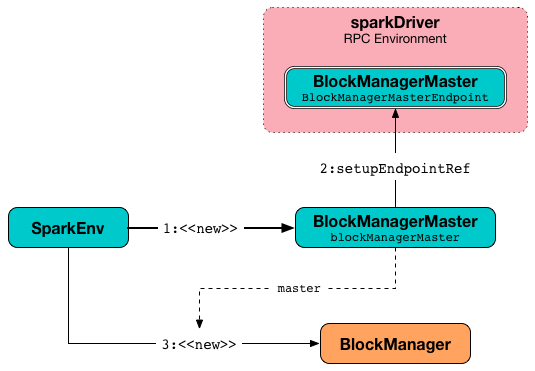
它创建一个 BlockManager(使用上面的BlockManagerMaster,NettyBlockTransferService和其他服务)。
它创建一个 BroadcastManager。
它分别为驱动程序和执行程序创建 MapOutputTrackerMaster 或 MapOutputTrackerWorker。
它注册或查找 RpcEndpoint 作为 MapOutputTracker。它在驱动程序上注册MapOutputTrackerMasterEndpoint,并在执行程序上创建RPC端点引用。RPC端点引用被指定为MapOutputTracker RPC端点。
它创建一个 CacheManager。
它分别为驱动程序和工作程序创建MetricsSystem。
它初始化用于下载驱动程序依赖项的userFiles临时目录,这也是executor执行程序的工作目录。
为驱动程序创建SparkEnv
createDriverEnv(
conf: SparkConf,
isLocal: Boolean,
listenerBus: LiveListenerBus,
numCores: Int,
mockOutputCommitCoordinator: Option[OutputCommitCoordinator] = None): SparkEnv

为Executor创建SparkEnv
createExecutorEnv(
conf: SparkConf,
executorId: String,
hostname: String,
port: Int,
numCores: Int,
ioEncryptionKey: Option[Array[Byte]],
isLocal: Boolean): SparkEnv