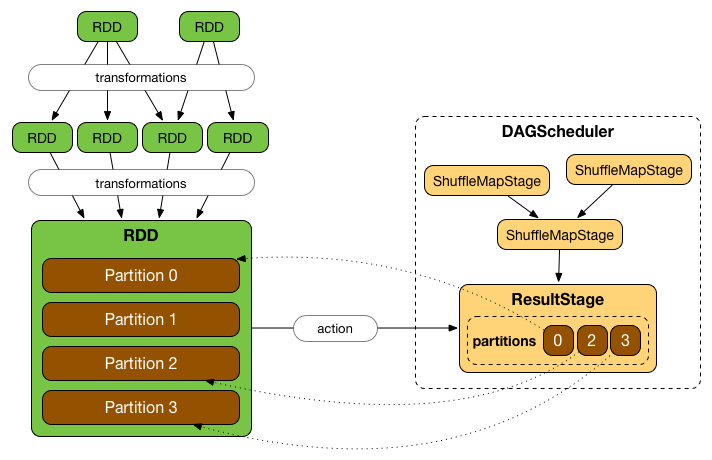
简介
DAGScheduler 是Apache Spark的调度层,它实现了面向阶段的调度(stage-oriented scheduling)。它将逻辑执行计划(logical execution plan)(使用RDD转换构建的依赖关系的RDD谱系)转换为物理执行计划(physical execution plan)(使用 stages)。
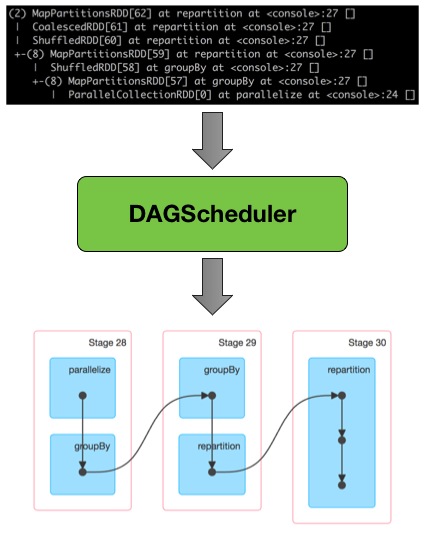
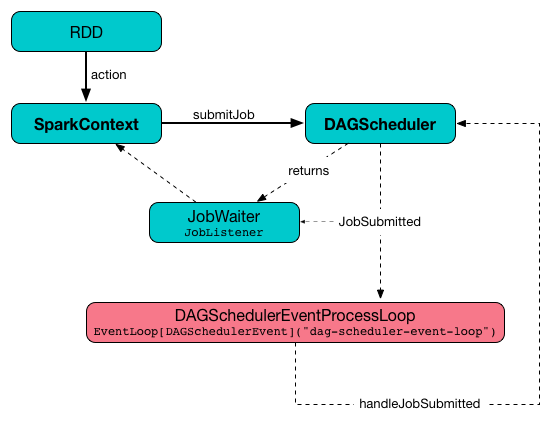
调用一个 action 后,SparkContext 将逻辑计划移交给 DAGScheduler,然后转换为一组作为 TaskSet 进行执行的 stages 。
DAGScheduler 的基本概念是 jobs 和 stages,他们分别通过内部注册表和计数器跟踪。
DAGScheduler 仅在 dirver 中使用,是作为SparkContext初始化的一部分创建的(在TaskScheduler和SchedulerBackend准备好之后)。

DAGScheduler 在Spark中做了三件事(详细解释如下):
- 计算出一个执行的 DAG
- 确定运行每个任务的首选位置
- 处理由于shuffle输出文件丢失而导致的故障
DAGScheduler 为每个作业计算阶段的有向非循环图(DAG),跟踪实现哪些RDD和阶段输出,并找到运行作业的最小计划(即最优计划)。然后它将阶段提交给TaskScheduler。
除了提出执行 DAG 之外,DAGScheduler还根据当前缓存状态确定运行每个任务的首选位置,并将信息传递给TaskScheduler。
DAGScheduler 跟踪哪些RDD被缓存(或持久化)以避免“重新计算”它们,即重做shuffle的map侧。DAGScheduler 记得哪些 ShuffleMapStages 已经生成了输出文件(存储在BlockManagers中)。
DAGScheduler 只对RDD的每个分区的缓存位置坐标(即主机和执行程序ID)感兴趣。
此外,它处理由于shuffle输出文件丢失而导致的故障,在这种情况下可能需要重新提交旧阶段。不是由 shuffle 文件丢失而引起的 stage 内的故障,由TaskScheduler本身处理,它将在取消整个 stage 之前少次地重试每个任务。
DAGScheduler 使用事件队列体系结构(event queue architecture),一个线程可以发布 DAGSchedulerEvent 事件,例如提交的新作业或阶段,DAGScheduler 按顺序读取事件和执行它。
DAGScheduler按拓扑顺序运行。
DAGScheduler 使用 SparkContext,TaskScheduler,LiveListenerBus,MapOutputTracker 和 BlockManager作为其服务。但是,DAGScheduler 只接受 SparkContext(并为其他服务请求SparkContext)。
DAGScheduler 报告有关其执行的指标。
当 DAGScheduler 通过在RDD上执行 action 或直接调用 SparkContext.runJob()方法来调度作业时,它会生成并行任务以计算每个分区的(部分)结果。
主要方法
submitJob
提交作业。
submitJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): JobWaiter[U]
submitJob创建一个JobWaiter并发布一个JobSubmitted事件。
在内部,submitJob执行以下操作:
- 检查
partitions是否引用输入rdd的可用分区 - 增加 nextJobId 内部工作计数器
- 当
partitions数量为零时,返回 0-task JobWaiter - 提交
JobSubmitted事件并返回JobWaiter
当输入 partitions 引用不在输入rdd中的分区时,您可能会看到抛出 IllegalArgumentException:
Attempting to access a non-existent partition: [p]. Total number of partitions: [maxPartitions]
submitMapStage
提交 ShuffleDependency 给 Execution。
submitMapStage[K, V, C](
dependency: ShuffleDependency[K, V, C],
callback: MapOutputStatistics => Unit,
callSite: CallSite,
properties: Properties): JobWaiter[MapOutputStatistics]
submitMapStage 创建一个JobWaiter(最终返回)并将 MapStageSubmitted 事件发布到 DAGScheduler Event Bus。
在内部,submitMapStage递增nextJobId内部计数器以获取作业ID。
然后,submitMapStage创建一个JobWaiter(具有作业ID和一个人造任务,但只有在整个阶段结束时才会完成)。
submitMapStage 宣布 application-wide 内的map stage提交(通过将 MapStageSubmitted 发布到 LiveListenerBus)。
如果要计算的分区数为0,则submitMapStage会抛出SparkException:
Can't run submitMapStage on RDD with 0 partitions
runJob
运行作业。
runJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): Unit
runJob 向 DAGScheduler 提交一个动作作业并等待结果。
在内部,runJob 执行 submitJob,然后等待直到使用 JobWaiter 得到结果。
DAGScheduler Event Bus
eventProcessLoop 是 DAGScheduler的事件总线,Spark(通过submitJob)向其发布作业以安排执行。稍后,TaskSetManager会回到 DAGScheduler,以使用相同的“通信通道”通知任务的状态。
它允许Spark在发布时释放当前线程,并让事件循环在一个单独的线程上处理事件 - 异步。
submitStage
submitStage(stage: Stage)
submitStage 是 DAGScheduler 用于提交输入阶段或其缺失父项的内部方法(如果在输入阶段之前还没有计算任何 stage)。
submitStage 以递归方式提交任何缺少的 stage 父依赖。
在内部,submitStage 首先找到需要该阶段的最早创建的作业ID。
submitStage 检查 stage 的状态,并且如果状态在内部注册表中不是等待、运行或失败的记录时,它会继续检查,否则它直接退出。
但是,如果 stage 缺少父阶段,则submitStage将提交所有父阶段,并且这个 stage 将记录在内部 waitingStages注册表中。
故障恢复- 重试 stage
如果 TaskScheduler 报告任务因前一阶段的 map 输出文件丢失而失败,则DAGScheduler会重新提交丢失的阶段。 这是通过带有FetchFailed的CompletionEvent或ExecutorLost事件检测到的。 DAGScheduler将等待一小段时间以查看其他节点或任务是否失败,然后为所有丢失的 stage 重新提交 TaskSets ,以计算丢失的任务。
请注意,stage 的旧尝试中的任务仍然正在运行。
stage对象跟踪多个StageInfo对象以传递给Spark侦听器或Web UI。
可以通过latestInfo访问最近阶段尝试的最新StageInfo。
ActiveJob
Job(也称为 action job 或 active job)是提交给DAGScheduler以计算操作结果(或自适应查询计划/自适应调度)的顶级工作项(指计算)。
计算一个Job等同于计算执行 action 的RDD的分区。Job 中的分区数取决于阶段的类型 - ResultStage或ShuffleMapStage。

请注意,对于诸如first() 和lookup() 之类的操作,并不总是为ResultStages计算所有分区。
在内部,作业由private [spark]类org.apache.spark.scheduler.ActiveJob的实例表示。
作业可以是两种逻辑类型之一(仅由ActiveJob的内部finalStage字段区分):
- Map-stage job,在提交任何下游阶段之前,计算ShuffleMapStage(对于submitMapStage)的map输出文件。它还用于自适应查询计划/自适应调度,以便在提交后续阶段之前查看map输出统计信息。
- Result job, 计算ResultStage以执行 action。
作业跟踪已经计算了多少分区(通过一个元素为 Boolean 的 finished 数组)。
Stage
stage 是一个物理执行单位。这是物理执行计划中的一个步骤。
stage 是一组并行任务 - 每个分区一个任务(分区来自一个作为 Spark Job 中部分函数输出的部分结果的RDD)。
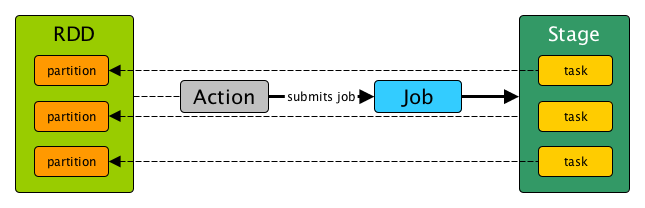
换句话说,Spark作业是一种分为几个 stage 的计算过程。

Stage 由 id 作为唯一标识。创建阶段时,DAGScheduler会递增内部计数器nextStageId以跟踪阶段提交的数量。
一个 stage 只能在单个RDD的分区上工作(通过 rdd 标识),但可以与许多其他依赖的父阶段(通过内部字段父项)相关联,stage 的边界由 shuffle dependencies 标记。
因此,提交 stage 可以触发执行一系列依赖的父 stage。

最后,每个阶段都有一个firstJobId,它是提交阶段的作业的id。
有两种类型的 stage:
- ShuffleMapStage 是一个中间阶段(在执行DAG中),它为其他 stage 生成数据。它为一个shuffle写入 map的输出文件。它也可以是自适应查询规划/自适应调度工作的最后阶段。
- ResultStage 是在用户程序中执行Spark action的最后阶段。
提交作业时,会创建一个新的 stage,并将父 ShuffleMapStage 链接起来 - 如果其他作业已经使用,则可以从头创建或链接到共享,即共享。
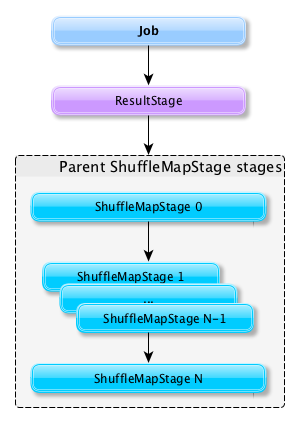
Stage 跟踪它所属的作业(通过它们的ID)(使用内部jobIds注册表)。
DAGScheduler将一份 job 分成一系列 stage。每个 stage 包含一系列窄变换(narrow transformations),这些变换可以在不 shuffle 整个数据集的情况下完成。 Stage 们在 shuffle 边界处分离,即发生 shuffle。 因此 stage 们是在 shuffle 边界处破坏RDD图的结果。
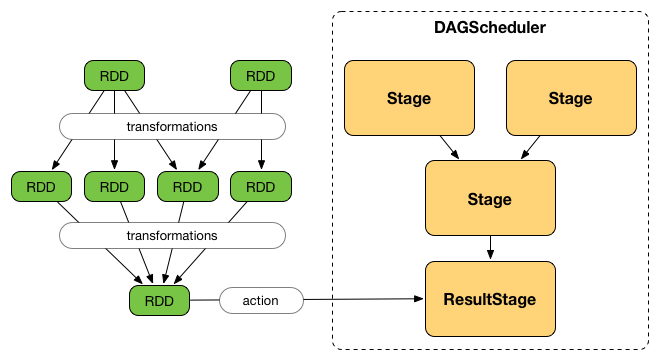
shuffle 边界引入了一个障碍,在这里 stage/tasks 必须等待上一stage完成才能获取map输出。
具有窄依赖性(narrow dependencies)的RDD操作(如map() 和 filter() ),在每个 stage 中一起流水线化为一组任务,但具有shuffle依赖性(宽依赖)的操作需要多个 stage,即一个用于输出一堆map的输出文件,另一个用于在屏障后读取这些文件。
最后,每个 stage 对其他 stage 只具有shuffle依赖关系,并且在其内部可能进行多个计算操作。 这些操作的实际流水线操作发生在各种RDD的 RDD.compute() 函数中,例如, MappedRDD,FilteredRDD等。
在 stage 生命周期中的某个时间点,stage 的每个分区都会转换为一个任务 - 分别为 ShuffleMapStage 中的 ShuffleMapTask 或 ResultStage 中的 ResultTask。
Tasks 稍后提交给Task Scheduler(通过taskScheduler.submitTasks)。
findMissingPartitions
stage 的抽象类定义如下:
abstract class Stage {
def findMissingPartitions(): Seq[Int]
}
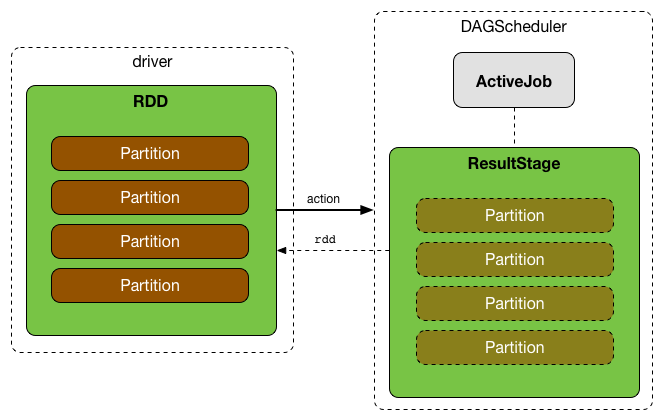
Stage.findMissingPartitions() 可以获取那些 missing partitions 的 id,这些 missing partitions 是指那些 ActiveJob 知道它们还没有完成的 partitions 。
ResultStage 通过查询 ActiveJob 来了解未完成的分区ID(numPartitions)(使用ActiveJob.finished布尔数组)。

在上图中,partition 1 和 2 没有完成,因为在 finished 的布尔数组里,它们对应的是 F (false)。
ShuffleMapStage
ShuffleMapStage(也称为 shuffle map阶段或简称map阶段)是 physical execution DAG 中与 ShuffleDependency 对应的中间阶段。
当 ShuffleMapStage 被执行时,它保存 map output files ,这些文件后面会被reduce tasks 获取。当所有的 map output files 都可用时,ShuffleMapStage 就会被认为是 available (or ready)。
输出位置可能会丢失,即 partitions 尚未计算或丢失。
ShuffleMapStage 使用 outputLocs 和 _numAvailableOutputs 内部注册表来跟踪可用的 shuffle map 输出的数量。
ShuffleMapStage是阶段DAG中其他后续阶段的输入,因此它也被称为 shuffle dependency’s map side 。
一个 ShuffleMapStage 可能在 shuffle 操作之前,包含多个 pipelined operations, 比如 map 和 filter。
单个 ShuffleMapStage 可以在不同的作业中共享。
ResultStage
ResultStage 是作业的最后一个阶段,它在目标RDD的一个或多个分区上应用函数来计算操作的结果。
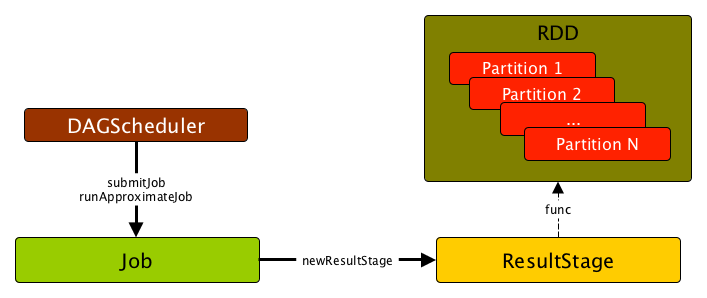
会给每个 partition 一组 partition 的 ids 以及 一个函数 func: (TaskContext, Iterator[_]) ⇒ _。