这里介绍两点 Spark 的优化:广播变量(Broadcast Variables),累加器(Accumulators)。
Broadcast Variables
官方文档说明:
Broadcast variables allow the programmer to keep a read-only variable cached on each machine rather than shipping a copy of it with tasks.
广播变量允许程序员在每台机器上保留一个只读变量,而不是随任务一起发送它的副本。
Explicitly creating broadcast variables is only useful when tasks across multiple stages need the same data or when caching the data in deserialized form is important.
显式创建广播变量,仅在跨多个阶段的任务需要相同数据或以反序列化形式缓存数据很重要时才有用。
基本原理:
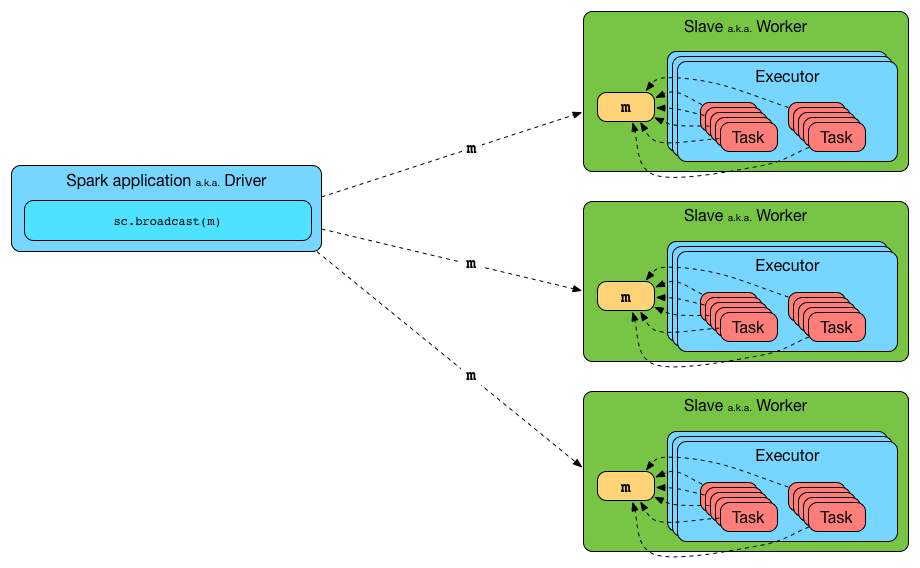
要再 Spark Transformation 里面使用广播变量,就要先调用 SparkContext.broadcast方法来创建,然后使用 value 方法来获取变量。
Spark 的这个广播特性,使用 SparkContext 来创建的广播值,然后 BroadcastManager 和 ContextCleaner来管理它们的生命周期。
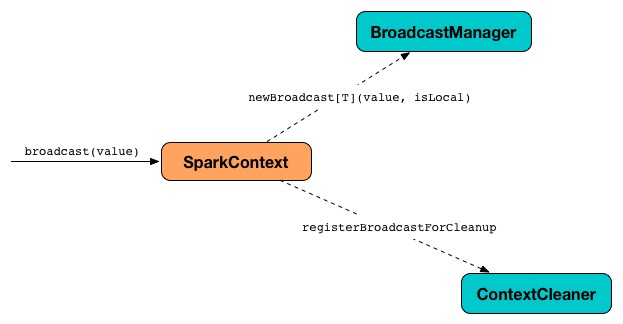
广播变量的生命周期
创建:
val b = sc.broadcast(1)
使用:
b.value
使用之后可以销毁它来释放内存:
b.destroy
在销毁广播变量之前,你可能想要取消(unpersist)它:
b.unpersist
简述
广播某个值时,它只会复制到 executors 一次(否则就要在执行任务时多次复制它)。这意味着如果在任务中需要使用较大的值或者 task 数量多于 executor 数量,广播可以帮助您更快地运行 Spark。
Spark 可以使用带有 collectAsMap 的广播来创建用于广播的Map。使用collectAsMap和 broadcast, 将数据集较小(逐列而非逐行)的 RDD map 进行广播后,再使用较大的 RDD 与之 map,速度会明显提升。
代码:
val acMap = sc.broadcast(myRDD.map { case (a,b,c,b) => (a, c) }.collectAsMap)
val otherMap = sc.broadcast(myOtherRDD.collectAsMap)
myBigRDD.map { case (a, b, c, d) =>
(acMap.value.get(a).get, otherMap.value.get(c).get)
}.collect
尽可能使用大型广播的HashMaps而不是RDD,并使用 key 保留 RDD 以查找必要的数据,如上所示。
Accumulators
Accumulators 是通过关联和交换的“add”操作来 add 的变量。
它们充当容器,用于累加在多个任务(在 executor 上运行)的部分值。 它们设计的目的是为了在并行和分布式Spark计算中,可以安全有效地使用这些变量, 比如可以用于记录计数器和总和(例如,任务度量)。
你可以使用内置的累加器,比如 longs, doubles, 或 collections 等类型 。也可以定制自己的累加器,但是需要使用 SparkContext.register 来注册。你可以给累加器指定名字,或者不指定,但是 Web UI 只展示有名字的累加器。
累加器在 executor 中是只写变量。它们可以由 executors 添加并仅由 driver 读取。
累加器不是线程安全的。
保证累加器线程安全是没必要的,因为在一个 task 完成(成功或者失败)后,diver 用来更新累加器的值的方法 DAGScheduler.updateAccumulators 是一个运行在 scheduling loop 的单线程。除此之外,每个 worker 都保存有一个本地的、只写的累加器,只有 dirver 才允许访问累加器的值。
累加器是可序列化的,因此可以在执行程序中执行的代码中安全地引用它们,然后通过线路安全地发送以执行。
val counter = sc.longAccumulator("counter")
sc.parallelize(1 to 9).foreach(x => counter.add(x))
在内部,longAccumulator,doubleAccumulator和collectionAccumulator方法创建内置类型累加器并调用SparkContext.register。