简述
使用RDD Spark隐藏数据分区和分布,从而允许他们使用更高级别的编程接口(API)为四种主流编程语言设计并行计算框架。
创建RDD的动机是当前计算框架处理效率低下的两种类型的应用程序:
- 机器学习和图形计算中的迭代算法(iterative algorithms)。
- 交互式数据挖掘工具作为同一数据集的即席查询(interactive data mining tools)。
目标是在多个数据密集型工作负载中重用中间内存结果,而无需通过网络复制大量数据。
RDD的类型
- ParallelCollectionRDD - 是
SparkContext.parallelize和SparkContext.makeRDD的结果 - CoGroupedRDD - 将一对父RDD合并为一个RDD。
RDD.cogroup(…). - HadoopRDD 是一个提供了使用旧版MapReduce API读取存储在HDFS中数据的核心功能的RDD. 最值得注意的用例是作为
SparkContext.textFile的返回RDD. - MapPartitionsRDD - 进行操作后的结果,比如操作:
map,flatMap,filter,mapPartitions, etc. - CoalescedRDD - 重新分配或合并转换的结果
- ShuffledRDD - shuffled的结果
- PipedRDD - 由管道元素创建到分叉外部进程的RDD
- PairRDD (隐式地通过
PairRDDFunctions转换获得) - 是一个 key-value 对RDD。操作groupByKey和join会产生. - DoubleRDD (隐式地通过
org.apache.spark.rdd.DoubleRDDFunctions) 是个Double类型的RDD - SequenceFileRDD (隐式地通过
org.apache.spark.rdd.SequenceFileRDDFunctions) 是个可以被保存为SequenceFile的RDD.
RDD Lineage
RDD Lineage(又名RDD运算符图或RDD依赖图)是RDD的所有父RDD的图。 它是将转换应用于RDD并创建逻辑执行计划的结果。
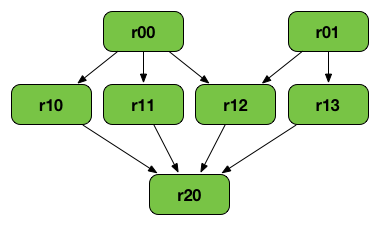
上面的RDD图可能是以下一系列转换的结果:
val r00 = sc.parallelize(0 to 9)
val r01 = sc.parallelize(0 to 90 by 10)
val r10 = r00 cartesian r01
val r11 = r00.map(n => (n, n))
val r12 = r00 zip r01
val r13 = r01.keyBy(_ / 20)
val r20 = Seq(r11, r12, r13).foldLeft(r10)(_ union _)
逻辑执行计划从最早的RDD(不依赖于其他RDD或引用缓存数据的RDD)开始,以产生结果的action动作的RDD结束。
Partitions
partition (又名 split)是大型分布式数据集的逻辑块。Spark使用 Partitions 来管理数据,这些 Partitions 有助于并行化分布式数据处理,只需最少的网络流量即可在执行程序。 默认情况下,Spark会尝试从靠近它的节点将数据读入RDD。由于Spark通常访问分布式分区数据,为了优化转换操作,它创建了用于保存数据块的分区。
默认情况下,为每个HDFS分区创建一个分区。
当一个阶段执行时,您可以在Spark UI中看到给定阶段的分区数。
可以使用 rdd.partitions.size 方法来查看 rdd 的分区数目。
每当发生 shuffle 时,分区就会在节点之间重新分配。
初始化 rdd 的时候,也可以指定分区数目:sc.textFile(path, partition),但是它只能用于未压缩的数据。面对压缩数据,我们需要在读取完成之后,进行重分区。
repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
以上方法会触发 shuffle 操作。
Shuffling
Spark中的某些操作会触发称为shuffle的事件。 Shuffle 是Spark的重新分发数据的机制,因此它可以跨分区进行不同的分组。 这通常涉及跨 executors 和机器来复制数据,使得 Shuffle 成为复杂且昂贵的操作。
背景
为了理解在shuffle期间发生的事情,我们可以考虑reduceByKey操作的示例。reduceByKey操作生成一个新的RDD,其中单个键的所有值都组合成一个元组 - 键和与该键关联的所有值执行reduce函数的结果。挑战在于,并非所有key对应的值都必须位于同一个分区,甚至是同一个机器上,但它们必须位于同一位置才能计算结果。
在Spark中,数据通常不跨分区分布,以便在特定操作的必要位置。在计算过程中,单个任务将在单个分区上运行 - 因此,要使用单个 reduceByKey 任务执行的所有数据,Spark需要执行一个 all-to-all 操作。它必须从所有分区读取以查找所有键的所有值,然后将分区中的值汇总在一起以计算每个键的最终结果 - 这称为 shuffle。
尽管 shuffle 之后新数据的每个分区中的元素集将是确定性的,并且分区本身的排序也是如此,但分区里元素的排序却不是确定的。如果在 shuffle 之后需要可预测的有序数据,则可以使用:
- mapPartitions 来排序每个分区,例如: .sort
- repartitionAndSortWithinPartitions 在重新分区的同时有效地对分区进行排序
- sortBy 创建一个全局排好序的 RDD
可能导致 shuffle 的操作包括 repartition 操作,如 repartition 和 coalesce, ByKey 操作(除了 count),如:groupByKey 和 reduceByKey, 以及 join 操作,如:cogroup 和 join。
性能影响
Shuffle是一项昂贵的操作,因为它涉及磁盘 I/O,数据序列化和网络I/O.。为了组织shuffle的数据,Spark生成了一系列任务 - map 任务以组织数据,以及一组reduce任务来聚合它。 这个术语来自MapReduce,但并不直接与Spark的 map 和 reduce 操作相关。
在内部,各个 map 任务的结果会保留在内存中,直到它们无法存放。然后,会基于目标分区来进行排序,接着写入单个文件。在 reduce 那边,任务读取相关的排序块。
某些 shuffle 操作会消耗大量的堆内存,因为在传输记录之前或之后,它们使用内存中的数据结构来组织这些记录。具体来说,reduceByKey 和 aggregateByKey 在 map 侧创建这些结构,并且ByKey操作在reduce侧生成这些结构。当数据超出内存时,Spark会将这些表溢出到磁盘,从而导致磁盘 I/O 的额外开销和垃圾收集增加。
Shuffle 还会在磁盘上生成大量中间文件。从 Spark 1.3 开始,这些文件将被保留,直到不再使用相应的RDD并进行垃圾回收。这样做是为了在重新计算依赖时不需要重新创建 shuffle 文件。如果应用程序保留对这些RDD的引用或GC不经常启动,则垃圾收集可能仅在很长一段时间后才会发生。这意味着长时间运行的Spark作业可能会占用大量磁盘空间。配置Spark上下文时,spark.local.dir 配置参数指定临时存储目录。
可以通过调整各种配置参数来调整 Shuffle 行为。
Checkpointing
Checkpointing 是截断RDD Lineage Graph ,并将其保存到可靠的文件系统(如 HDFS 或本地文件系统)的过程。
有两类 checkpointing:
- reliable:在Spark Core 中,RDD checkpointing将实际的中间RDD数据保存到可靠的分布式文件系统,例如, HDFS。
- local:在Spark Streaming或GraphX中 - RDD checkpointing 存放在本地文件系统。
开发者在决定使用 checkpointing 时,可以使用 RDD.checkpoint() 方法。在使用 checkpointing 之前,Spark开发人员必须使用SparkContext.setCheckpointDir(directory:String)方法设置检查点目录。
Reliable Checkpointing
在集群模式下,传入 setCheckpointDir方法的参数,必须是 HDFS 的路径。因为 driver 或许会从它的本地文件系统恢复checkpointing的数据,但是这是不对的,因为数据都存储在各个executor的机器上。
在调用 RDD.checkpoint()后,RDD 会被保存在之前设置的目录下,然后这个RDD所有的父类RDD就会被移除掉。必须在对此RDD执行任何作业之前,调用这个函数。
强烈建议在内存中保留 checkpointed RDD,否则将其保存在文件中将需要重新计算。