Web UI(也称为Application UI或webUI或Spark UI)是Spark应用程序的Web界面,用于在Web浏览器中监视和检查Spark作业执行。
总览
每次在Spark应用程序中创建SparkContext时,您还会启动Web UI实例。
默认情况下,Web UI位于 http://[driverHostname]:4040。
可以使用spark.ui.port配置属性更改默认端口。如果已经使用SparkContext,则会增加端口,直到找到打开的端口。
Web UI附带以下选项卡(可能不会立即全部显示,但仅在使用相应模块后,例如SQL或Streaming选项卡):
- Jobs
- Stages
- Storage
- Environment
- Executors
JobsTab
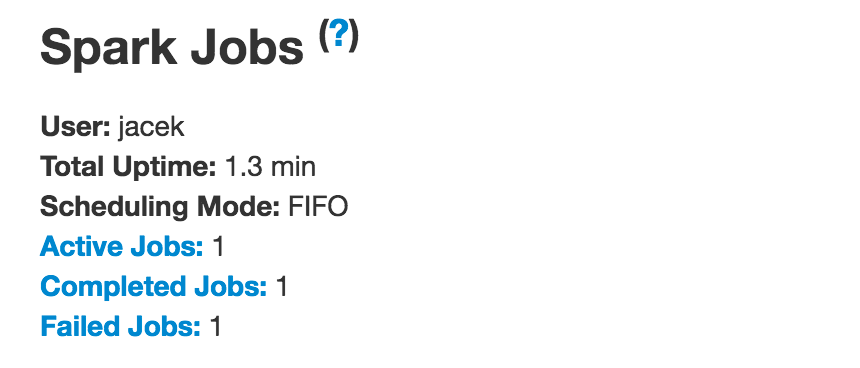
1. AllJobsPage - 在Web UI中显示所有作业
AllJobsPage显示Summary部分,其中包含当前Spark用户,总运行时间,计划模式以及每个状态的作业数。
StagesTab
Web UI中的 StagesTab 显示Spark应用程序(即SparkContext)中所有作业的所有阶段的当前状态,其中包含两个可选页面,用于阶段的任务和统计信息(选择阶段时)和pool详细信息(当应用程序时) 在FAIR调度模式下工作)。
1. AllStagesPage
AllStagesPage是一个在Stages选项卡中注册的网页(部分),该选项卡显示Spark应用程序中的所有阶段 - 活动,待处理,已完成和失败的阶段及其计数。

2. StagePage
显示 stage 的细节信息。
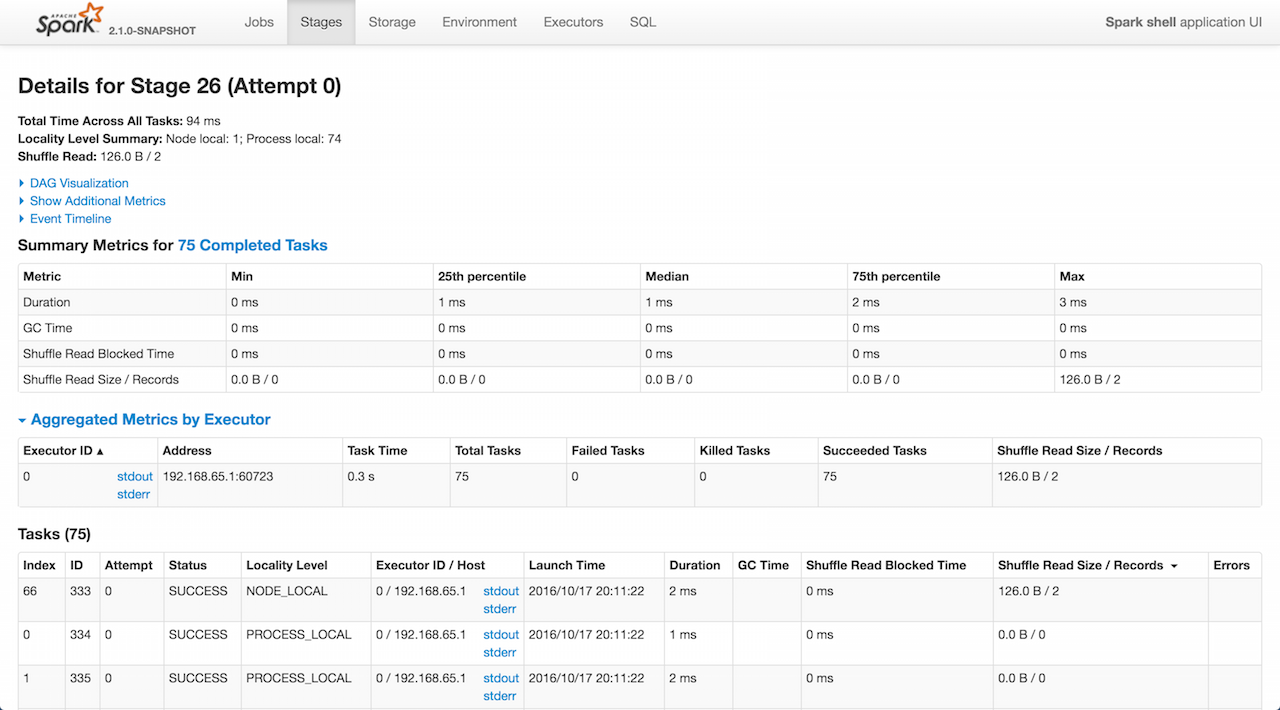
StagePage使用父级的 JobProgressListener 和 RDDOperationGraphListener 来计算度量。
更具体地说,StagePage 使用 JobProgressListener 的 stageIdToData 注册表来访问给定阶段id和attempt的stage。
StagePage使用ExecutorsListener在Tasks部分中显示执行程序的stdout和stderr日志。
已完成的stage汇总信息
有以下列:Metric, Min, 25th percentile, Median, 75th percentile, Max.
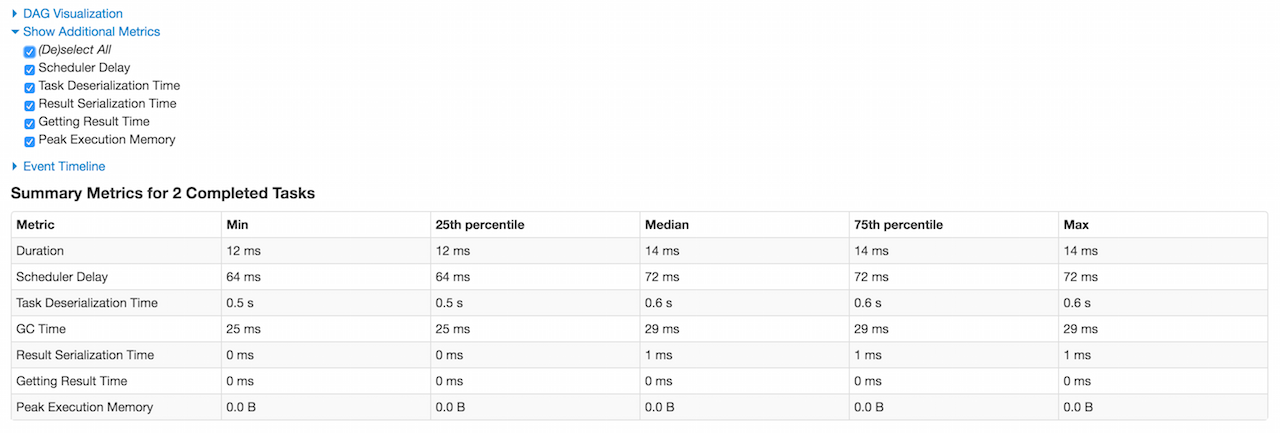
第一行持续时间 (Duration )包括基于executorRunTime的分位数
第二行调度延迟(Scheduler Delay )是可选的,它包括将任务从调度程序发送到执行程序的时间,以及将任务结果从执行程序发送到调度程序的时间。它默认不启用,可以在汇总表Show Additional Metrics里面勾选 Scheduler Delay。
如果Scheduler Delay很大,请考虑减小任务的大小或减小任务结果的大小。
第3行是可选的任务反序列化时间(Task Deserialization Time),其包括基于executorDeserializeTime任务度量的分位数。它默认也不启用。
第4行是GC Time,它是执行程序在任务运行时暂停用于Java垃圾收集的时间(使用jvmGCTime任务指标)。
第5行是可选的结果序列化时间(Result Serialization Time),它是在将任务结果发送回驱动程序之前在执行程序上序列化任务结果所花费的时间(使用resultSerializationTime任务指标)。
第6行是可选的获取结果时间(Getting Result Time),它是驱动程序从工作程序获取任务结果的时间。
如果“获取结果时间”很长,请考虑减少从每个任务返回的数据量。
如果启用了Tungsten(默认情况下),则第7行是可选的峰值执行内存(Peak Execution Memory),它是在shuffles, aggregations 和 joins 期间创建的内部数据结构的峰值大小的总和(使用peakExecutionMemory任务指标)。对于SQL作业,这仅跟踪所有不安全的操作符,broadcast joins 和 external sort。
如果阶段有输入,则第8行是输入大小/记录(Input Size / Records),它是从Hadoop或Spark存储读取的字节和记录(使用inputMetrics.bytesRead和inputMetrics.recordsRead任务指标)。
如果阶段有输出,则第9行是输出大小/记录(Output Size / Records ),它是写入Hadoop或Spark存储的字节和记录(使用outputMetrics.bytesWritten和outputMetrics.recordsWritten任务度量标准)。
如果stage 有随机读取,则表格中还会有三行。第一行是随机读取阻塞时间(Shuffle Read Blocked Time),它是阻止等待从远程计算机读取随机数据的任务所花费的时间(使用shuffleReadMetrics.fetchWaitTime任务指标)。另一行是Shuffle Read Size / Records, 它是总的shuffle字节和读取的记录(包括本地读取的数据和使用shuffleReadMetrics.totalBytesRead和shuffleReadMetrics.recordsRead任务指标从远程执行程序读取的数据)。最后一行是Shuffle Remote Reads,它是从远程执行器读取的总shuffle字节(它是shuffle读取字节的子集;剩余的shuffle数据在本地读取)。它使用shuffleReadMetrics.remoteBytesRead任务指标。
如果stage有随机写入,则以下行是随机写入大小/记录(Shuffle Write Size / Records)(使用shuffleWriteMetrics.bytesWritten和shuffleWriteMetrics.recordsWritten任务指标)。
如果阶段有溢出的字节,则以下两行是Shuffle spill (memory) (使用memoryBytesSpilled任务指标)和Shuffle spill (disk)(使用diskBytesSpilled任务指标)。
3. PoolPage
Fair Scheduler Pool Details 页面显示有关可调度池的信息,仅在Spark应用程序使用FAIR调度模式(由spark.scheduler.mode设置控制)时可用。
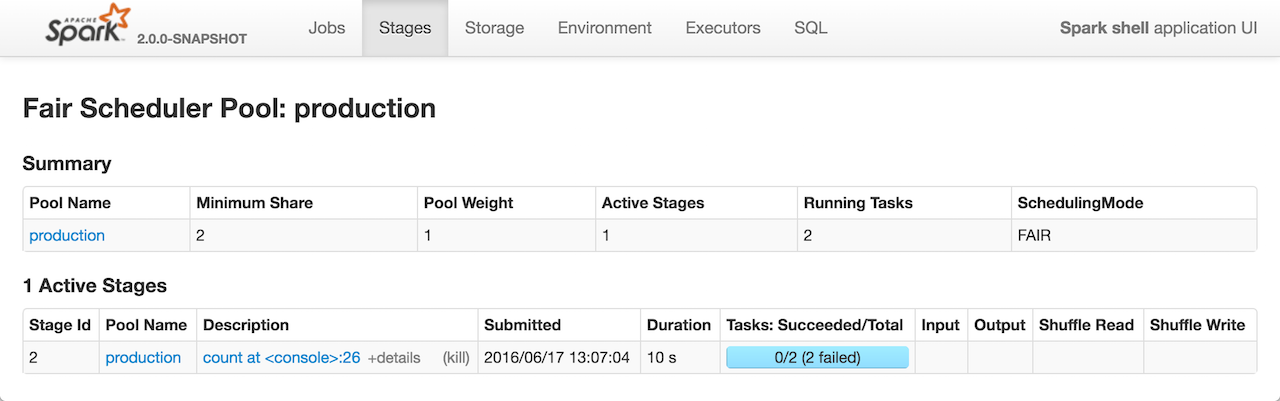
PoolPage在 /pool URL下呈现页面,并且需要一个请求参数poolname,该名称是要显示的池的名称,比如:http://localhost:4040/stages/pool/?poolname=production。
它由两个表组成:Summary(包含池的详细信息)和Active Stages(池中的活动阶段)。
PoolPage是在创建StagesTab时专门创建的。
PoolPage使用父级的SparkContext访问池中的活动阶段的池和JobProgressListener的信息(默认情况下按submissionTime按降序排序)。