MapReduce很强大,但是对于不会JAVA的一些数据库开发者,还是不太友好。所以Hive出现了,它可以将SQL解析成为MapReduce程序,既降低了SQL开发者的入门成本,又可享受MapReduce强大的计算能力。
简介
Apache Hive是一个基于Hadoop Haused构建的开源数据仓库系统,用于查询和分析存储在Hadoop文件中的大型数据集。
编译器会在内部将HiveQL语句转换为MapReduce作业,进一步提交给Hadoop框架执行。
优点:
- 不用学java写Mapreduce,只需会SQL即可使用
- Schema灵活性和演变
- 表可以portioned和bucketed
- Apache Hive表格直接在HDFS中定义
- JDBC / ODBC驱动程序可用
缺点:
- Apache不提供实时查询和行级更新。
- 交互式数据浏览,存在延迟。
- 这对于在线交易处理并不好。
- Apache Hive查询的延迟通常非常高。
架构
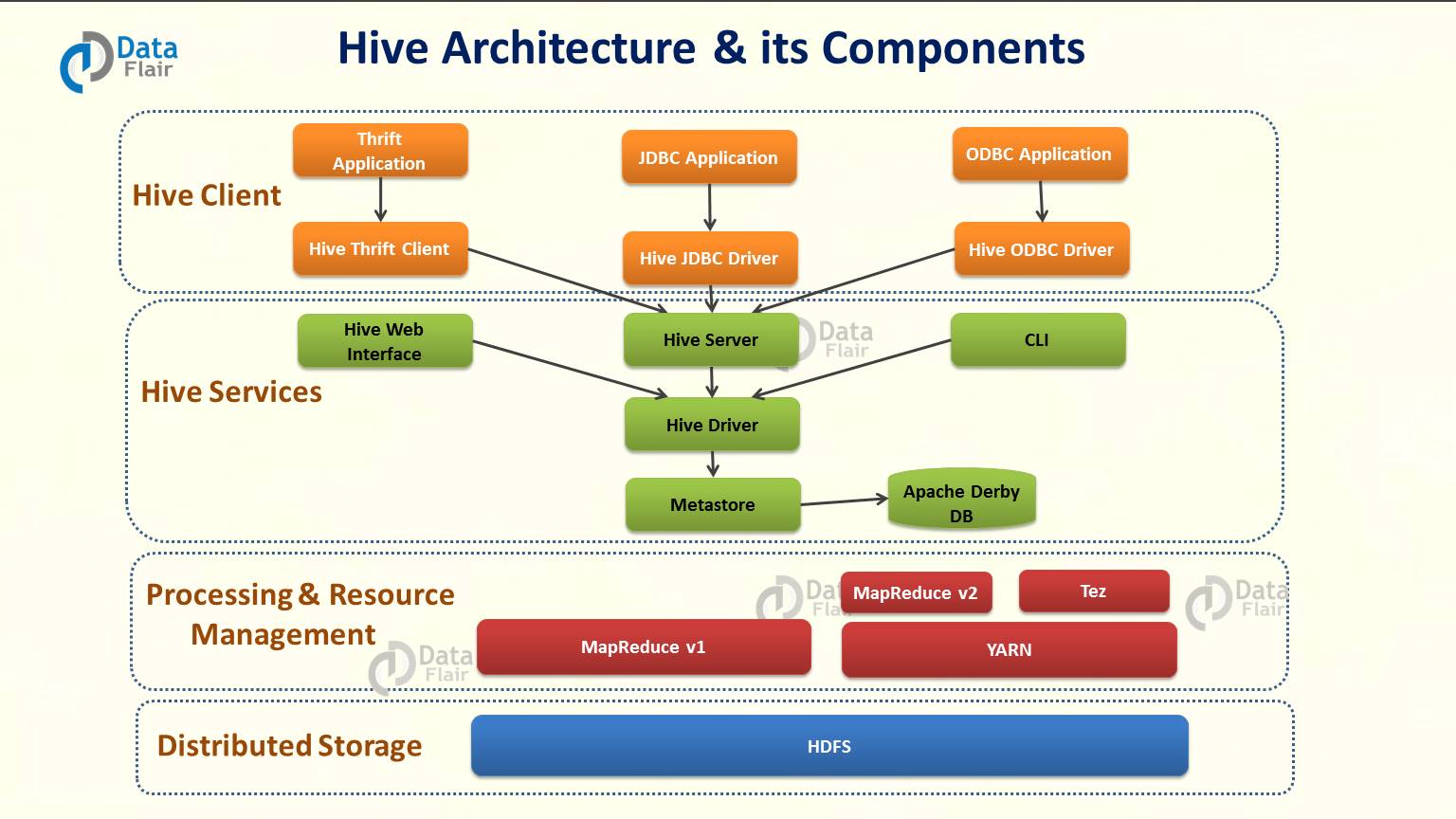
从上图可以看到hive的主要部件分为四层:
- Hive Clients
- Hive Services
- Processing framework and Resource Management:Hive内部使用Hadoop MapReduce框架执行查询。
- Distributed Storage:如上所述,Hive构建在Hadoop的顶层,因此它使用底层HDFS作为分布式存储。
详细介绍一下Hive clients、Hive Service。
1. Hive Clients
Apache Hive使用JDBC, Thrift 和 ODBC驱动时,支持用C ++,Java,Python等语言编写的所有应用程序。 因此,人们可以很容易地编写用他们选择的语言编写的Hive客户端应用程序。
-
Thrift Clients
由于Apache Hive服务器基于Thrift,所以它可以处理来自支持Thrift的所有语言的请求。
-
JDBC Clients
Apache Hive允许Java应用程序使用JDBC驱动程序连接到它。它在类apache.hadoop.hive.jdbc.HiveDriver中定义。
-
ODBC Clients
ODBC驱动程序允许支持ODBC协议的应用程序连接到Hive。例如JDBC驱动程序,ODBC使用Thrift与Hive服务器进行通信。
2. Hive Services
-
CLI(Command Line Interface)
这是Hive提供的默认shell,您可以在其中直接执行Hive查询和命令。
-
Web Interface
Hive还提供基于Web的GUI来执行Hive查询和命令。
-
Hive Server
它建立在Apache Thrift上,因此也被称为Thrift服务器。它允许不同的客户端向Hive提交请求并检索最终结果。
-
Hive Driver
驱动程序负责接收由Hive客户端通过Thrift,JDBC,ODBC,CLI,Web UL接口提交的的查询。
- Complier: Driver会将查询传入编译器中。它会在metastore中schema信息的帮助下,对查询进行解析、类型检查,以及语义分析。
- Optimizer: 它以一个MapReduce和HDFS任务的DAG(有向无环图)的形式,生成优化的逻辑计划。
- Executor: 一旦编译和优化完成,执行引擎就会使用Hadoop按照它们的依赖性顺序执行这些任务。
-
Metastore
Metastore是Hive体系结构中Apache Hive元数据的中央存储库。 它为关系数据库中的Hive表(如其架构和位置)和partitions存储元数据。它通过使用Metastore服务API为客户端提供对这些信息的访问。
Metastore包含两个基本单位: 提供对其他Apache Hive服务的代理访问权限的服务; Hive元数据的独立于HDFS存储的磁盘存储。
Metastore有三种模式:
-
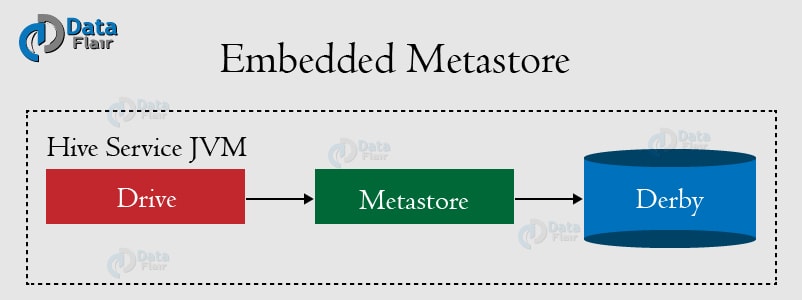
Embedded Metastore 嵌入式Metastore
metastore 服务和Hive服务运行在统一JVM中。 适用于将数据存储在本地的嵌入式Derby数据库。缺点是一次只能存在一个Hive会话。
-
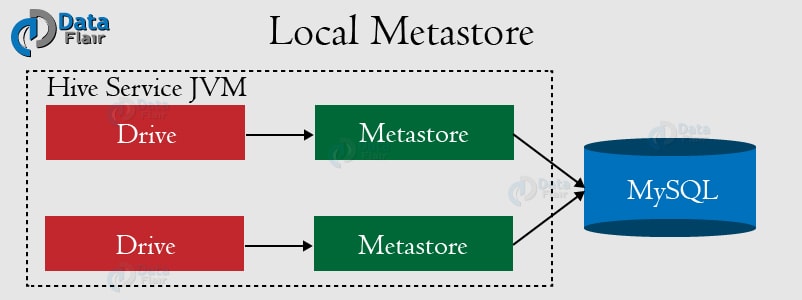
Local Metastore 本地Metastore
这个模式可以一次开启多个Hive会话。 比如适用于任何JDBC兼容的数据库,如MySql。这种数据库可以在分离的JVM或者不同机器上运行。 然而这个模式下,metastore 服务和Hive服务仍运行在一个JVM中。
-
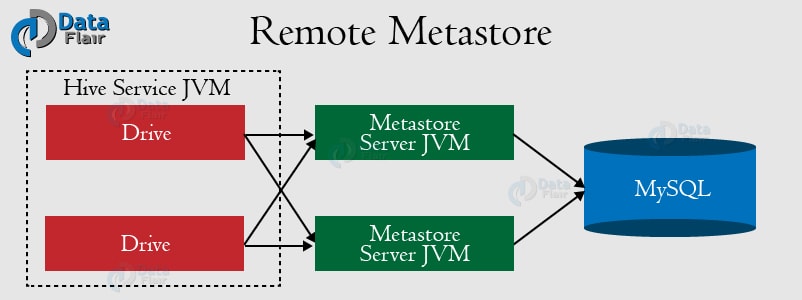
Remote Metastore 远程Metastore
这个模式下,metastore运行在独立的JVM中。如果其他进程想要与Metastore服务器进行通信,他们可以使用Thrift Network API进行通信。 优点有:更多的Metastore服务器可以提供更多的可用性; 也带来了更好的可管理性/安全性; 客户端不再需要与每个Hiver用户共享数据库凭证。
-