Mapreduce 作为hadoop的计算框架层, 是hadoop的核心之一。
总览
从两个方面介绍mapreduce:job的提交运行过程,以及mapreduce中data执行flow。
Job的提交运行过程
1. MR1
MR1中,任务处理的核心部件有两个JobTracker和TaskTracker。
1)流程图
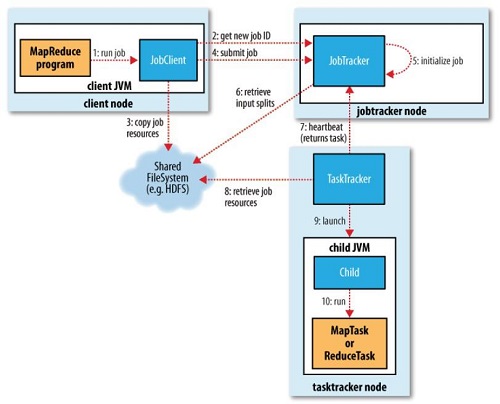
2)过程步骤
- client启动jvm,创建一个job和JobClient
- JobClient向JobTracker申请一个job ID,来标识这个job
- JobClient在HDFS上创建一个以Job ID命名的目录,同时将job运行时所有需要的资源上传,如jar包、配置文件、InputSplit等
- 在上传资源结束后,JobClient向JobTracker submit job
- JobTracker收到job,并且初始化job
- JobTracker向HDFS上获取这个job的split信息,生成一系列待处理的Map和Reduce任务
- JobTracker向TaskTracker分配任务。
- TaskTracker读取HDFS获取任务相关资源
- TaskTracker启动一个child JVM
- child jvm中运行MapTask或者ReduceTask
3)注意
- 数据划分是在JobClient上完成的,它适用InputFormat将输入数据做一次划分,形成若干split。
- 在第7步,JobTracker会根据TaskTracker的地址,再结合上一步读到的split中location信息,来选择一个location离TaskTracker最近的map或reduce任务分配给它
- 在第10步,MapTask会使用InputSplit.getRecordReader()返回的RecordReader对象,来读取Split中的每一条记录。
2. MR2
MR2的MapReduce Job是在YARN框架中执行的。
0) 基本概念
- RM(Resource Manager)
- AM(Application Master)
- NM(Node Manager)
- CLC(Container Launch Context):CLC发给ResourceManager,提供了资源需求(内存/CPU)、作业文件、安全令牌以及在节点上启动ApplicationMaster需要的其他信息。
1)流程图
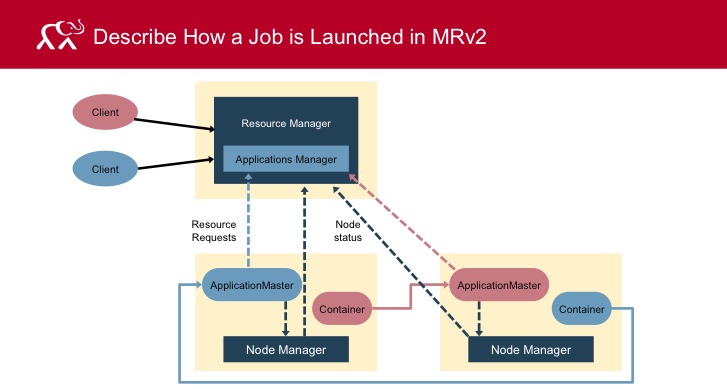
2)过程步骤
- client向RM提交申请,包括CLC所需的信息。
- 位于RM中的Application Manager会协商一个容器并为应用程序初始化AM。
- AM注册到RM,并请求容器。
- AM与NM通信以启动已授予的容器,并为每个容器指定CLC
-
然后AM管理应用程序执行
在执行期间,应用程序向AM提供进度和状态信息。Client可以通过查询RM或直接与AM通信来监视应用程序的状态。
- AM向RM报告应用程序的完成情况
- AM从RM上注销,RM清理AM所在容器。
Data Flow
1. 流程图
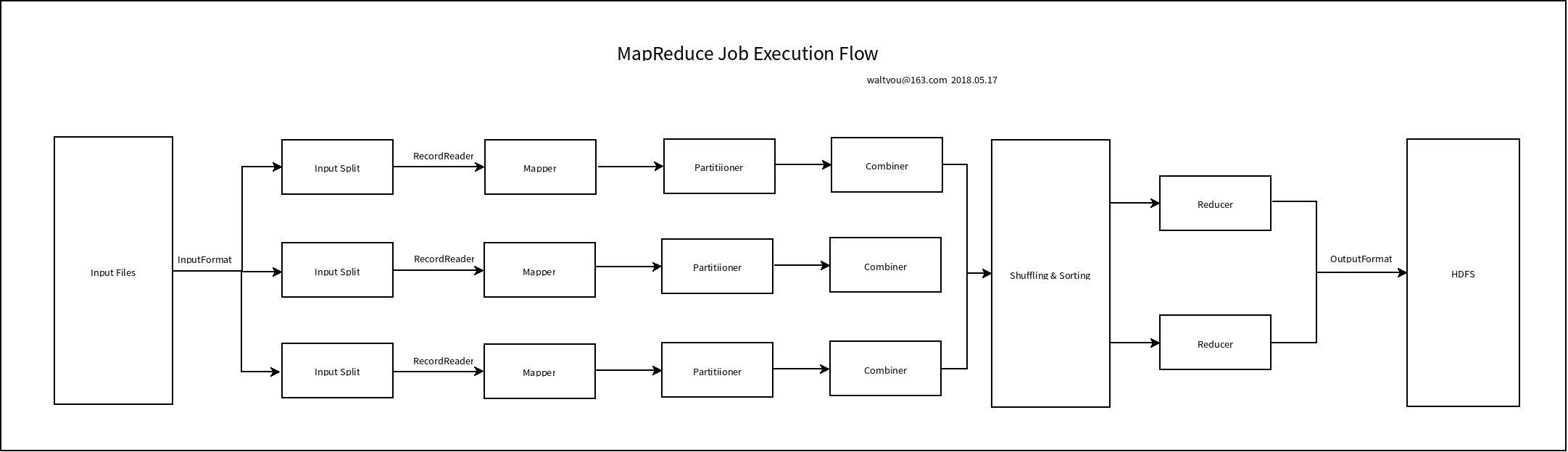
2. 分步介绍
1)Input Files
各种形式的、存储在HDFS上的文件。
2)InputFormat
InputFormat 定义了这些input files是如何被split和read的。
先来看下InputFormat抽象类的定义
public abstract class InputFormat<K, V>
{
public abstract
List<InputSplit> getSplits(JobContext context
) throws IOException, InterruptedException;
public abstract
RecordReader<K,V> createRecordReader(InputSplit split,
TaskAttemptContext context
) throws IOException,
InterruptedException;
}
可以看到,它定义了两个方法:
- getSplits: 定义如何分割input files而得到inputSplits
- createRecordReader: 定义如何读取inputSplits
常见的InputFormat有:
-
FileInputFormat
是所有基于文件的inputFormat的基类。 它指定了输入文件的路径,当提交job时,它提供了所读文件的路径。 它将会读取所有文件,并将它们分为一个或多个InputSplit。
-
TextInputFormat
是MapReduce默认的InputFormat。 它把文件中的每一行当作一条分离的记录。 key为每一行的偏移量,value为每一行的内容。
-
KeyValueTextInputFormat
和TextInputFormat很像,都是把每一行当作分离的记录。 只不过它输出的key和value是根据tab(/t)分割开的两段。
-
SequenceFileInputFormat
SequenceFileInputFormat是一个读取序列文件的InputFormat。 序列文件是存储二进制键值对序列的二进制文件。 序列文件是块压缩的,并提供几种任意数据类型(不仅仅是文本)的直接序列化和反序列化。 这里的键和值都是用户自定义的。
-
SequenceFileAsTextInputFormat
SequenceFileAsTextInputFormat是SequenceFileInputFormat的另一种形式,它将序列文件键值转换为Text对象。 通过调用’tostring()’,对key和value执行转换。 这个InputFormat使序列文件适合输入流。
-
SequenceFileAsBinaryInputFormat
SequenceFileAsBinaryInputFormat是一个SequenceFileInputFormat, 我们可以使用它来提取序列文件的键和值作为不透明的二进制对象。
-
NLineInputFormat
NLineInputFormat是TextInputFormat的另一种形式。只是,它接收一个变量N,代表每个InputSplit处理多少行数据。
-
DBInputFormat
DBInputFormat是一个可以通过JDBC来读取关系型数据库的InputFormat。 由于它没有分割功能,所以我们需要小心不要让太多的Mapper读取数据库。 所以最好用它加载较小的数据集,比如是用来和一个HDFS上的大数据集进行join,这是可使用MultipleInputs。 key是LongWritables,Value是DBWritables。
3)InputSplits
它被InputFormat创建,从逻辑上来讲,它会被单个Mapper所处理。 对每个InputSplit,会创建一个map task处理它,所以这里有多少个inputSplit就有多少个map task。
4)RecordReader
它和InputSplit交流,并把数据变为key-value形式,来发送给mappe做后续处理。
5)Mapper
它接收从RecordReader传来的键值对record,处理后,生成新的键值对。
Mapper的输出作为中间结果写入硬盘。中间结果不写入HDFS的原因有两点:
- 中间结果是临时文件,上传hdfs会产生不必要的备份文件;
- HDFS是一个高延迟的系统。
Mapper的数量:No. of Mapper= {(total data size)/ (input split size)}
6)Partitioner
首先如果只有一个Reducer,是不使用Partitioner的。
步骤
Partitioner对Mapper的输出执行分区操作。具体步骤如下:
- partitioner拿到combiner的输出键值对中的key
- 对key的值进行hash函数转换,获取分区id
- 根据分区id,再将键值对分入对应分区
- 每个分区又会被发送给一个Reducer。
需要注意,分区数量和reduce task数量一致的,所以若要控制Partitioner的数量,可以通过JobConf.setNumReduceTasks()来设置。
例子
来看看Partitioner的定义:
public abstract class Partitioner<KEY, VALUE> {
public abstract int getPartition(KEY key, VALUE value, int numPartitions);
}
MapReduce中默认的Partitioner是HashPartitioner,它直接使用key的hashcode,然后对numReduceTasks去模,这样子可以产生非常均匀的分区。
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
必要性
Partitioner主要保证了相同key值的键值对,可以进入同一个Reducer中,从而实现平均向Reducer们分配Mapper的输出。 它控制了拥有某个key值的键值对,该被哪个Reducer处理。
局限性与改良
当某个key出现的次数,远远大于其他key时,如果还是只按照key的hash值来分区,必然会导致数据倾斜。一个reducer累的要命,其他reuducer闲着没事。
一旦出现数据倾斜严重的情况,MapReduce job的任务进度通常会卡在99%处,无法结束,然后等待一段时间后,任务直接失败,或者直接导致reduce task OOM。 (关于数据倾斜,以后应该会专门再来一篇介绍。)
这时候,一种解决途径,就是自己定制化Partitioner,让mapper的输出可以均匀地分给reducer们。
7)Combiner
Combiner也被成为“Mini-reducer”,即缩小版的reducer。 从它的使用方式上,也可以看出它这个名字的由来。因为当我们使用它时,也是直接继承Reducer类,来实现reduce方法,最后在Job中指定combiner类即可。
另外,它是个可选的步骤。
Combiner对partition后的output进行local的聚合,来减少mapper和reducer之间的网络传输。 尤其是在处理一个巨大的数据集时,会产生很多巨大的中间数据,这些巨大的中间数据,不仅会加大网络传输的压力,同时也会加大Reducer的处理压力。
优点:
- 减少了网络传输时间
- 降低了Reducer处理的数据量
- 改善了Reducer的性能
同时,它也有一些缺点:
- Combiner的执行是不被保证的,所以MapReduce job不能依赖于combiner
- 在Combiner处理中间数据时,中间数据是存储在本地文件系统中的,所以会造成昂贵的磁盘I/O。
8)Shuffling and Sorting
经过Partitioner后,数据被shuffle到reducer节点(其实就是一般的节点,因为它运行了reduce阶段,我们就这样子叫它)。
shuffling是经由网络传输的物理移动。
一旦mapper完成(注:也可以不等所有的Mapper结束),所有的输出会被shuffle到reducer节点(Shuffling阶段),在reducer节点,中间结果会被merge和sort(Sorting阶段),然后提供给reduce阶段。
shuffling阶段和sorting阶段是由MapReduce框架同时进行的。
在Reducer开始处理数据之前,所有中间结果键值对会被MapReduce框架按key值来排序,而不是按value值。 被reducer处理的value们是不被排序的,它们可以是任何顺序。 (注:不过MapReduce也提供了对value排序的机制,叫做Secondary Sorting。)
Sorting 更好的帮助了reducer来判断是否要启动一个新的reduce task。 对于按key排序好键值对数据,reducer一旦发现一个不同于之前key的键值对时,它就可以启动一个新的reduce task了。 这样子节省了很多时间。
当reducer数目被set为0时,shuffling和sorting完全不会执行。
Shuffle又细分为两个阶段:map-shuffle 和 reduce-shuffler。
Map-Shuffle
写入之前先进行分区Partition,用户可以自定义分区(就是继承Partitioner类),然后定制到job上,如果没有进行分区,框架会使用 默认的分区(HashPartitioner)对key去hash值之后,然后在对reduceTaskNum进行取模(目的是为了平衡reduce的处理能力),然后决定由那个reduceTask来处理。
将分完区的结果<key,value,partition>开始序列化成字节数组,开始写入缓冲区。
随着map端的结果不端的输入缓冲区,缓冲区里的数据越来越多,缓冲区的默认大小是100M,当缓冲区大小达到阀值时 默认是0.8【spill.percent】(也就是80M),开始启动溢写线程,锁定这80M的内存执行溢写过程,内存 —>磁盘,此时map输出的结果继续由另一个线程往剩余的20M里写,两个线程相互独立,彼此互不干扰。
溢写spill线程启动后,开始对序列化的字节数组进行排序(先对分区号排序,然后在对key进行排序),默认顺序是自然排序。
如果客户端自定义了 Combiner 之后,将相同的key的value相加。
每次溢写都会在磁盘上生成一个一个的小文件,因为最终的结果文件只有一个,所以需要将这些溢写文件归并到一起,这个过程叫做 Merge。
集合里面的值是从不同的溢写文件中读取来的。这时候Map-Shuffle就算是完成了。
一个MapTask端只生成一个结果文件。
Reduce-Shuffle
当MapTask完成任务数超过总数的 5% 后,开始调度执行ReduceTask任务,然后 ReduceTask 默认启动5个copy线程到完成的MapTask任务节点上分别copy一份属于自己的数据(使用Http的方式)。
这些拷贝的数据会首先保存到内存缓冲区中,当达到一定的阀值的时候,开始启动内存到磁盘的 Merge (溢写过程),一直运行到map端没有数据生成,最后启动磁盘到磁盘的 Merge 方式生成最终的那个文件。在溢写过程中,然后锁定80M的数据,然后在延续Sort过程,然后在 group(分组)里,将相同的key放到一个集合中,然后在进行Merge。
最后就开始 reduceTask,这个文件交给 reduced() 方法进行处理,执行相应的业务逻辑。
9)Reducer
Reducer会拿到一个由mapper输出的键值对集合,然后对它们分别运行reduce函数。
有时候Shuffling和Sorting,会被看作Reducer的第一阶段和第二阶段,那么执行reduce函数就是第三阶段。
Reducer数量:(0.95 or 1.75) * (no. of nodes * no. of the maximum container per node).
- 在0.95的情况下,所有的reducer会在mapper完成后,立即启动和传输mapper的输出。
- 在1.75的情况下,第一轮的reducer会被较快的节点完成,然后再加载第二轮的reducer再开始加载,这样子更好地实现了负载均衡。
提高reducer数量可以:
- 提高框架开销
- 提高负载均衡
- 降低失败的代价
10)RecordWriter
它将这些从Reducer阶段输出的键值对,写入输出文件。
public abstract class RecordWriter<K, V> {
public abstract void write(K key, V value
) throws IOException, InterruptedException;
public abstract void close(TaskAttemptContext context
) throws IOException, InterruptedException;
}
11)OutputFormat
RecordWriter对键值对的输出方式取决于OutputFormat。
Hadoop提供的OutputFormat实例可以用来将文件写入HDFS或者本地文件系统。
FileOutputFormat.setOutputPath()用来指定输出目录。
常见的OutputFormat有:
-
TextOutputFormat
是Hadoop默认的Output Format,它默认对每个键值对中的key和value分别使用toString方法,并且用tab作为分隔符,写入单行中。 分隔符可以通过MapReduce.output.textoutputformat.separator来设置。
-
SequenceFileOutputFormat
它是一种Output Format,它为输出写入序列文件。它是MapReduce作业之间中间数据的输出格式。 它可将任意数据类型快速序列化到文件; 并且相应的SequenceFileInputFormat会将该文件反序列化为相同的类型, 并以与之前的Mapper发出的方式一样,将数据呈现给下一个Reducer,因为它们是紧凑且易于压缩的。 压缩由SequenceFileOutputFormat上的静态方法控制。
-
SequenceFileAsBinaryOutputFormat
它是SequenceFileOutputFormat的另一种形式,它以二进制格式将键和值写入序列文件。
-
MapFileOutputFormat
它是FileOutputFormat的另一种形式,用于将输出写为MapFile。 MapFile中的键必须按顺序添加,因此我们需要确保Reducer按排序顺序输出key。
-
MultipleOutputs
它允许将数据写入文件,文件的名称来自输出键和值,或者可以来自任意字符串。
-
LazyOutputFormat
有时FileOutputFormat会创建输出文件,即使它们是空的。 LazyOutputFormat是一个包装的OutputFormat,它确保只有在为给定分区发出记录时才会创建输出文件。
-
DBOutputFormat
Hadoop中的DBOutputFormat是用于写入关系数据库或HBase的output format。 它将reduce输出发送到SQL表。 它接受键值对,其中键的类型为扩展DBwritable。 它返回的RecordWriter只使用批量SQL查询将key写入数据库。