HIPI,全名 Hadoop Image Processing Interface, 是 Hadoop 生态圈中一个图像处理库,旨在与Apache Hadoop MapReduce并行编程框架一起使用。 来了解一下。
是什么、能干啥
HIPI 通常利用在集群上执行的MapReduce样式并行程序,来促进高效和高吞吐量的图像处理。
它提供了一种解决方案,用于在Hadoop分布式文件系统(HDFS)上存储大量图像,并使其可用于高效的分布式处理。
HIPI还提供与 OpenCV 的集成。
出现的背景
通常图片都是很小的,但是 Hadoop 不适合处理小文件,所以 HIPI 就提供了一系列接口, 来把一堆小的图片,变为一个大的 HIB 文件,这样子就可以高效分布式处理图片了。
系统设计
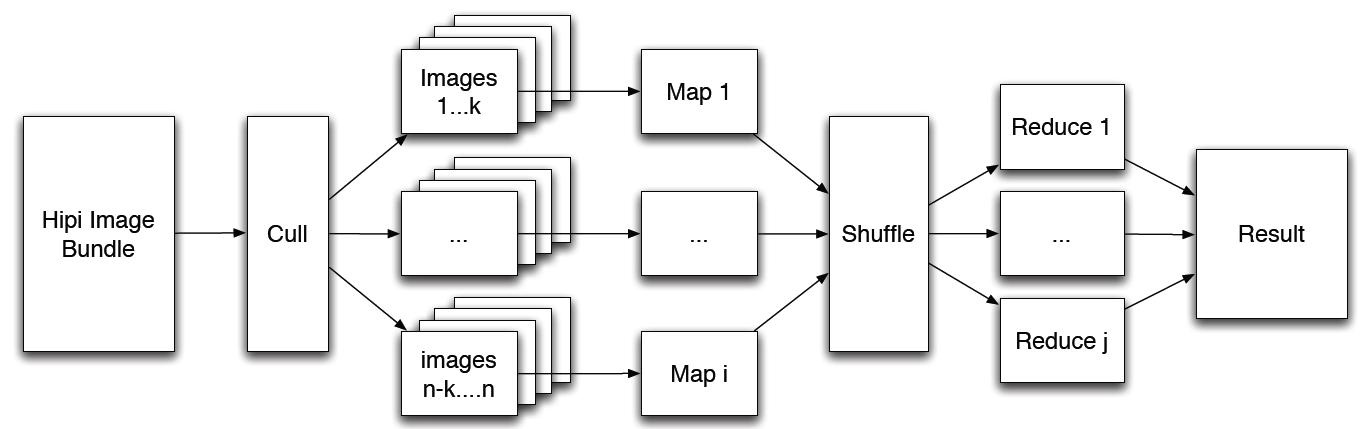
HIPI 程序主要的输入对象是 HipiImageBundle(HIB)。 HIB 是在HDFS上表示为单个文件的图像集合。 HIPI 发行版包括几个用于创建 HIB 的有用工具,包括 MapReduce 程序,该程序根据从Internet下载的图像列表构建 HIB。
HIPI 程序的第一处理阶段是剔除步骤,其允许基于诸如空间分辨率或与图像元数据相关标准等各种用户定义条件来过滤HIB中的图像。 此功能通过 Culler 类实现。 剔除的图像永远不会被完全解码,从而节省了处理时间。
在剔除阶段中存活的图像以一种尝试最大化数据局部性的方式分配给各个地图任务,这是Hadoop MapReduce编程模型的基石。 此功能是通过HibInputFormat类实现的。 最后,将单个图像作为从 HipiImage 抽象基类派生的对象以及关联的 HipiImageHeader 对象呈现给Mapper。 例如,ByteImage 和 FloatImage 类扩展了 HipiImage 基类,并分别提供对图像像素值的基础栅格网格的访问,作为Java字节和浮点数组。 这些类提供了许多有用的功能,如裁剪,颜色空间转换和缩放。
HIPI还包括对OpenCV的支持。 具体来说,可以使用 OpenCVUtils 类中的例程将从 RasterImage 扩展的图像类(如上面讨论的ByteImage和FloatImage)转换为OpenCV Java Mat对象。 OpenCVMatWritable 类提供了OpenCV Java Mat类的包装器,可以在MapReduce程序中用作键或值对象。 有关如何将HIPI与OpenCV一起使用的更多详细信息,请参阅covar示例程序。
根据内置的MapReduce shuffle算法收集Mapper发出的记录并将其传输到Reducer,该算法试图最小化网络流量。 最后,用户定义的reduce任务并行执行,其输出被聚合并写入HDFS。
hello world
环境准备
话不多说,直接上docker。详情参考这里。
docker pull ykulah/hadoop-hipi-opencv
这镜像中,已经装好了 Hadoop 和 HIPI ,以及 OpenCV 。
或者到另外一个地方,获取hadoop 版本 2.7.1, 然后参考官方文档,自己安装 HIPI。
例子
官方例子是一个非常简单的HIPI程序的过程,该程序计算一组图像上的平均像素颜色。
创建 HIB
首先,我们需要一组图像来使用。
根据上面的系统设计,可以知道,HIPI 接收 HIB 作为输入。 这里使用自带工具:hibImport,它能在本地文件系统中,从一个图片的文件夹里,创建出一个 HipiImageBundle (HIB) 。 还有其他工具,详情参考这里.
进入到 HIPI 根目录,
$> tools/hibImport.sh ~/SampleImages sampleimages.hib
Input image directory: /Users/jason/SampleImages
Output HIB: sampleimages.hib
Overwrite HIB if it exists: false
HIPI: Using default blockSize of [134217728].
HIPI: Using default replication factor of [1].
** added: 1.jpg
** added: 2.jpg
** added: 3.jpg
Created: sampleimages.hib and sampleimages.hib.dat
hibImport 命令,在当前的 HDFS 目录下建立了两个文件:sampleimages.hib 和 sampleimages.hib.dat。 可以通过 “hadoop fs -ls” 检验一下。
可以使用HIPI附带的方便的hibInfo工具来检查这个新创建的HIB文件的内容:
$> tools/hibInfo.sh sampleimages.hib --show-meta
Input HIB: sampleimages.hib
Display meta data: true
Display EXIF data: false
IMAGE INDEX: 0
640 x 480
format: 1
meta: {source=/Users/hipiuser/SampleImages/1.jpg}
IMAGE INDEX: 1
3210 x 2500
format: 1
meta: {source=/Users/hipiuser/SampleImages/2.jpg}
IMAGE INDEX: 2
3810 x 2540
format: 1
meta: {source=/Users/hipiuser/SampleImages/3.jpg}
Found [3] images.
写代码
可以参考一下官方tool包下面的例子。
总结
通过源代码,可以看出,HIPI 自己定义了一种文件格式,即 HIB 格式: HipiImageBundle.java。
然后基于 hadoop 平台要求,定义了与 HIB 格式对应的 InputFormat:HibInputFormat, 以及 RecordReader: HibRecordReader。
然后剩下的都交由 hadoop 平台完成。