在今年九月接触了Faiss,从刚开始的一头雾水,到最后顺利在项目中使用,经历了许多曲折。
这次来总结一下。
重新审视
1. 再问Faiss是什么?
撇开具体定义不管,理解新事物的最好方式就是类比自己熟悉的事物。
比如,Faiss 就可以类比为一个可以设置索引的数据库。
索引是干什么的? 更快的读取,数据库是干什么的?增删改查。数据库里存的什么?通常来讲是许多记录,但对于Faiss来讲就是巨多的向量。
只是在 Faiss 中没有数据库存储介质这一层的概念,全部都是 Index。
2. Index 在 Faiss 中是什么角色?
还是类比数据库的索引,为了更快的查数据,我们可以学字典一样,以首字母建立索引,也可以像早期的谷歌一样,使用倒排索引(inverted index)。
不同的索引方式,有不同的优缺点,Faiss 已经全部实现好了。 如果只是为了使用,可以暂时忽略它们的实现原理,只需要了解各自特点以及自己的使用场景即可。 详情参考这里。
实现代码
0. 环境
直接用 docker。
Faiss docker 选择:https://hub.docker.com/r/waltyou/faiss-api-service/
里面 Faiss 、Flask、OpenCv 都已经装好了。
1. 提取图片向量
这个步骤选择性很多,因为有太多图片特征提取算法供我们选择了。
另外,提取图片特征向量这一步其实 Faiss 是不关心的,它只关心构建索引。
附上自己做的一些调查。
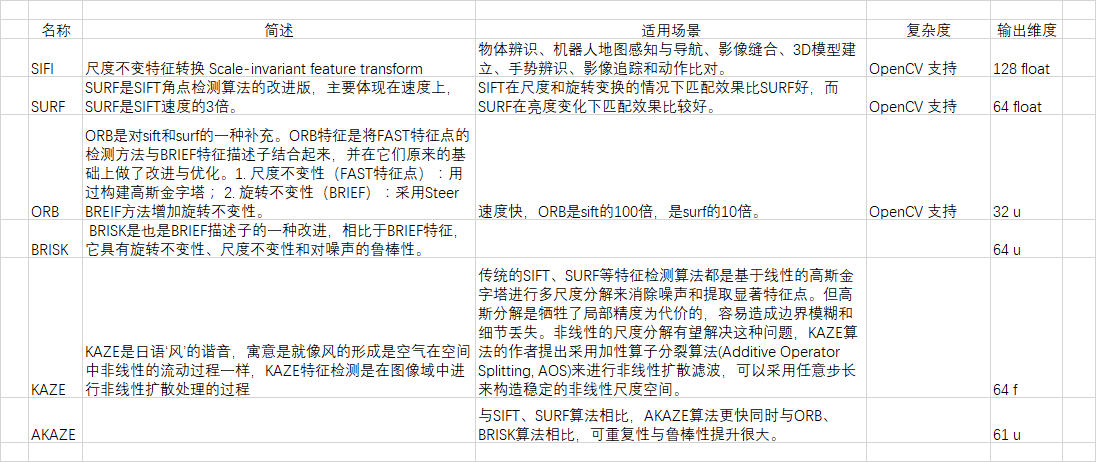
我在项目中使用SIFT算法进行特征提取,这个算法会在图片上找到许多的特征点,每个特征点有一个对应的 128 维的向量,这些向量就是我们要的特征向量。
// create a opencv sift extractor
def get_sift():
return cv2.xfeatures2d.SIFT_create(nfeatures=NUM_FEATURES, nOctaveLayers=3, contrastThreshold=0.04,
edgeThreshold=10, sigma=1.6)
// calculate sift
def calc_sift(sift, image_file):
if not os.path.isfile(image_file):
logging.error('Image:{} does not exist'.format(image_file))
return -1, None
try:
image_o = cv2.imread(image_file)
except:
logging.error('Open Image:{} failed'.format(image_file))
return -1, None
if image_o is None:
logging.error('Open Image:{} failed'.format(image_file))
return -1, None
image = cv2.resize(image_o, (NOR_X, NOR_Y))
if image.ndim == 2:
gray_image = image
else:
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
kp, des = sift.detectAndCompute(gray_image, None)
sift_feature = np.matrix(des)
return 0, sift_feature
注意
使用SIFT的时候也遇到了一个问题,就是一张图片可以提取出很多特征向量,图片对应向量是一对多的关系,但是Faiss搜索的基本单位是单个向量(当然它可以一次输入多个向量)。
意思就是说 Faiss 默认输入一个向量 x,返回和 x 最相似的 k 个向量。关于这个概念可以看官方例子加强理解。
为了解决这个问题,可以在建造 Faiss 索引的时候,给一张图片的多个向量赋予相同的id。 这样子,我们用一张图片的多个向量进行搜索后,在返回结果里,只需要统计关联id出现的次数,就能得到相似度高低。这个可以看后面的代码。
当然如果你觉得麻烦,或者对 CNN 等神经网络比较熟悉,你也可以使用它们对单一图片生成单一的高维向量。
2. 构建Index
简单起见,我使用最基础的 Index 类型: “IDMap,Flat”, 它是暴力搜索。你可以选择自己需要的类型。
# prepare index
dimensions = 128
INDEX_KEY = "IDMap,Flat"
index = faiss.index_factory(dimensions, INDEX_KEY)
if USE_GPU:
res = faiss.StandardGpuResources()
index = faiss.index_cpu_to_gpu(res, 0, index)
id = 0
index_dict = {}
for file_name in image_list:
ret, sift_feature = calc_sift(sift, file_name)
if ret == 0 and sift_feature.any():
# record id and path
index_dict.update({id: (file_name, sift_feature)})
ids_list = np.linspace(ids_count, ids_count, num=sift_feature.shape[0], dtype="int64")
id += 1
index.add_with_ids(sift_feature, ids_list)
在最后,可以将构建好的 Index 以及 index_dict 保存为文件。
# save index
faiss.write_index(index, index_path)
# save ids
with open(ids_vectors_path, 'wb+') as f:
pickle.dump(index_dict, f, True)
f.close()
如果你选择需要训练的Index类型,请先训练它再添加向量。
3. 查询 Index
scores, neighbors = index.search(siftfeature, k=topN)
4. 构建 API 服务
主要是参考 plippe/faiss-web-service ,在它基础上,添加了提取图片特征及训练Faiss索引等模块。
总结
项目的完整代码可以在github上看到: waltyou/faiss-web-service。
推荐
自己在学习实践的过程中,也在网上查了很多资料,以下列出一些我认为很有帮助的链接: