I met a strange issue when run a Spark job in DataProc Image 2.0 which Spark Version is 3.1.3. Let’s introduce this problem and how I can debug and resolve it.
How to reproduce this bug
1, Prepare test data as a CSV file
File name: test.csv, File content:
cust_id,prmry_reside_cntry_code
1,1_code
2,2_code
3,3_code
4,4_code
5,5_code
6,6_code
7,7_code
8,8_code
9,9_code
10,10_code
2, upload the test.csv to GCS and remember the GCS file path
3, Run below Spark code with DataProc Image 2.0:
spark.read.option("header", true).csv("gs://the/path/you/upload/test.csv").createOrReplaceTempView("crs_recent_30d_SF_dim_cust_info")
spark.sql(
"""
|select
| distinct cust_id,
| prmry_reside_cntry_code as devc_name_norm,
| prmry_reside_cntry_code
|from crs_recent_30d_SF_dim_cust_info
|""".stripMargin).createOrReplaceTempView("device_driver_info_0")
spark.sql(
"""
|select
| cust_id,
| concat(prmry_reside_cntry_code, devc_name_norm) as Device_Name_Country
|from device_driver_info_0
|""".stripMargin).createOrReplaceTempView("device_driver_info")
spark.sql(
"""
|select
| cust_id,
| Device_Name_Country
|from device_driver_info
|group by 1,2;
|""".stripMargin).createOrReplaceTempView("device_name_SF_final_acct_info")
val df = spark.sql(
"""
|select * from device_name_SF_final_acct_info limit 10
|""".stripMargin)
df.show()
Then we will get below error:
org.apache.spark.sql.catalyst.errors.package$TreeNodeException: execute, tree:
ShuffleQueryStage 1
+- Exchange hashpartitioning(cust_id#199, Device_Name_Country#207, 200), ENSURE_REQUIREMENTS, [id=#656]
+- *(2) HashAggregate(keys=[cust_id#199, Device_Name_Country#207], functions=[], output=[cust_id#199, Device_Name_Country#207])
+- CustomShuffleReader coalesced
+- ShuffleQueryStage 0
+- Exchange hashpartitioning(cust_id#199, devc_name_norm#203, prmry_reside_cntry_code#200, 200), ENSURE_REQUIREMENTS, [id=#621]
+- *(1) HashAggregate(keys=[cust_id#199, devc_name_norm#203, prmry_reside_cntry_code#200], functions=[], output=[cust_id#199, devc_name_norm#203, prmry_reside_cntry_code#200])
+- *(1) Project [cust_id#199, prmry_reside_cntry_code#200 AS devc_name_norm#203, prmry_reside_cntry_code#200]
+- FileScan csv [cust_id#199,prmry_reside_cntry_code#200] Batched: false, DataFilters: [], Format: CSV, Location: InMemoryFileIndex[gs://xxxx/test.csv], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<cust_id:string,prmry_reside_cntry_code:string>
at org.apache.spark.sql.catalyst.errors.package$.attachTree(package.scala:56)
at org.apache.spark.sql.execution.adaptive.ShuffleQueryStageExec.doMaterialize(QueryStageExec.scala:162)
at org.apache.spark.sql.execution.adaptive.QueryStageExec.$anonfun$materialize$1(QueryStageExec.scala:80)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:218)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:215)
at org.apache.spark.sql.execution.adaptive.QueryStageExec.materialize(QueryStageExec.scala:80)
at org.apache.spark.sql.execution.adaptive.AdaptiveSparkPlanExec.$anonfun$getFinalPhysicalPlan$4(AdaptiveSparkPlanExec.scala:196)
at org.apache.spark.sql.execution.adaptive.AdaptiveSparkPlanExec.$anonfun$getFinalPhysicalPlan$4$adapted(AdaptiveSparkPlanExec.scala:194)
at scala.collection.immutable.List.foreach(List.scala:431)
at org.apache.spark.sql.execution.adaptive.AdaptiveSparkPlanExec.$anonfun$getFinalPhysicalPlan$1(AdaptiveSparkPlanExec.scala:194)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:775)
at org.apache.spark.sql.execution.adaptive.AdaptiveSparkPlanExec.getFinalPhysicalPlan(AdaptiveSparkPlanExec.scala:180)
at org.apache.spark.sql.execution.adaptive.AdaptiveSparkPlanExec.executeCollect(AdaptiveSparkPlanExec.scala:278)
at org.apache.spark.sql.Dataset.collectFromPlan(Dataset.scala:3709)
at org.apache.spark.sql.Dataset.$anonfun$head$1(Dataset.scala:2735)
at org.apache.spark.sql.Dataset.$anonfun$withAction$1(Dataset.scala:3700)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:103)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:163)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:90)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:775)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3698)
at org.apache.spark.sql.Dataset.head(Dataset.scala:2735)
at org.apache.spark.sql.Dataset.take(Dataset.scala:2942)
at org.apache.spark.sql.Dataset.getRows(Dataset.scala:302)
at org.apache.spark.sql.Dataset.showString(Dataset.scala:339)
at org.apache.spark.sql.Dataset.show(Dataset.scala:826)
at org.apache.spark.sql.Dataset.show(Dataset.scala:785)
at org.apache.spark.sql.Dataset.show(Dataset.scala:794)
... 51 elided
Caused by: org.apache.spark.sql.catalyst.errors.package$TreeNodeException: Binding attribute, tree: Device_Name_Country#207
at org.apache.spark.sql.catalyst.errors.package$.attachTree(package.scala:56)
at org.apache.spark.sql.catalyst.expressions.BindReferences$$anonfun$bindReference$1.applyOrElse(BoundAttribute.scala:75)
at org.apache.spark.sql.catalyst.expressions.BindReferences$$anonfun$bindReference$1.applyOrElse(BoundAttribute.scala:74)
at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDown$1(TreeNode.scala:318)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:74)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:318)
at org.apache.spark.sql.catalyst.trees.TreeNode.transform(TreeNode.scala:307)
at org.apache.spark.sql.catalyst.expressions.BindReferences$.bindReference(BoundAttribute.scala:74)
at org.apache.spark.sql.catalyst.expressions.BindReferences$.$anonfun$bindReferences$1(BoundAttribute.scala:96)
at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:286)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at scala.collection.TraversableLike.map(TraversableLike.scala:286)
at scala.collection.TraversableLike.map$(TraversableLike.scala:279)
at scala.collection.AbstractTraversable.map(Traversable.scala:108)
at org.apache.spark.sql.catalyst.expressions.BindReferences$.bindReferences(BoundAttribute.scala:96)
at org.apache.spark.sql.execution.aggregate.HashAggregateExec.doConsumeWithKeys(HashAggregateExec.scala:828)
at org.apache.spark.sql.execution.aggregate.HashAggregateExec.doConsume(HashAggregateExec.scala:156)
at org.apache.spark.sql.execution.CodegenSupport.constructDoConsumeFunction(WholeStageCodegenExec.scala:221)
at org.apache.spark.sql.execution.CodegenSupport.consume(WholeStageCodegenExec.scala:192)
at org.apache.spark.sql.execution.CodegenSupport.consume$(WholeStageCodegenExec.scala:149)
at org.apache.spark.sql.execution.InputAdapter.consume(WholeStageCodegenExec.scala:496)
at org.apache.spark.sql.execution.InputRDDCodegen.doProduce(WholeStageCodegenExec.scala:483)
at org.apache.spark.sql.execution.InputRDDCodegen.doProduce$(WholeStageCodegenExec.scala:456)
at org.apache.spark.sql.execution.InputAdapter.doProduce(WholeStageCodegenExec.scala:496)
at org.apache.spark.sql.execution.CodegenSupport.$anonfun$produce$1(WholeStageCodegenExec.scala:95)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:218)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:215)
at org.apache.spark.sql.execution.CodegenSupport.produce(WholeStageCodegenExec.scala:90)
at org.apache.spark.sql.execution.CodegenSupport.produce$(WholeStageCodegenExec.scala:90)
at org.apache.spark.sql.execution.InputAdapter.produce(WholeStageCodegenExec.scala:496)
at org.apache.spark.sql.execution.aggregate.HashAggregateExec.doProduceWithKeys(HashAggregateExec.scala:733)
at org.apache.spark.sql.execution.aggregate.HashAggregateExec.doProduce(HashAggregateExec.scala:148)
at org.apache.spark.sql.execution.CodegenSupport.$anonfun$produce$1(WholeStageCodegenExec.scala:95)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:218)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:215)
at org.apache.spark.sql.execution.CodegenSupport.produce(WholeStageCodegenExec.scala:90)
at org.apache.spark.sql.execution.CodegenSupport.produce$(WholeStageCodegenExec.scala:90)
at org.apache.spark.sql.execution.aggregate.HashAggregateExec.produce(HashAggregateExec.scala:47)
at org.apache.spark.sql.execution.WholeStageCodegenExec.doCodeGen(WholeStageCodegenExec.scala:655)
at org.apache.spark.sql.execution.WholeStageCodegenExec.doExecute(WholeStageCodegenExec.scala:718)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$execute$1(SparkPlan.scala:180)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:218)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:215)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:176)
at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec.inputRDD$lzycompute(ShuffleExchangeExec.scala:118)
at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec.inputRDD(ShuffleExchangeExec.scala:118)
at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec.mapOutputStatisticsFuture$lzycompute(ShuffleExchangeExec.scala:122)
at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec.mapOutputStatisticsFuture(ShuffleExchangeExec.scala:121)
at org.apache.spark.sql.execution.adaptive.ShuffleQueryStageExec.$anonfun$doMaterialize$1(QueryStageExec.scala:162)
at org.apache.spark.sql.catalyst.errors.package$.attachTree(package.scala:52)
... 80 more
Caused by: java.lang.RuntimeException: Couldn't find Device_Name_Country#207 in [cust_id#199,devc_name_norm#203,prmry_reside_cntry_code#200]
at scala.sys.package$.error(package.scala:30)
at org.apache.spark.sql.catalyst.expressions.BindReferences$$anonfun$bindReference$1.$anonfun$applyOrElse$1(BoundAttribute.scala:81)
at org.apache.spark.sql.catalyst.errors.package$.attachTree(package.scala:52)
... 134 more
How to debug the issue
After setting the two configs spark.sql.adaptive.logLevel and spark.sql.planChangeLog.level to WARN, Spark 3 can logger the PhysicalPlan changed after each AQE replanning and applying Rule[SparkPlan].
Then after going through the log, looks like the PhysicalPlan goes wrong after calling the below code:
val logicalPlan = replaceWithQueryStagesInLogicalPlan(currentLogicalPlan, stagesToReplace)
val (newPhysicalPlan, newLogicalPlan) = reOptimize(logicalPlan)
So I write a personal Strategy to print the LogicalPlan so that we can know more about what happen in reOptimize function:
case object PrintLogicalPlan extends Strategy with Serializable {
def apply(plan: LogicalPlan): Seq[SparkPlan] = {
logWarning("======= Walt print logical plan rule========\n" + plan.treeString)
plan match {
case q: LogicalQueryStage =>
logWarning("===LogicalQueryStage.logicalPlan===\n" + q.logicalPlan)
logWarning("===LogicalQueryStage.physicalPlan===\n" + q.physicalPlan)
case _ => Nil
}
Nil
}
}
spark.experimental.extraStrategies = PrintLogicalPlan :: Nil
Then it shows:

We can see that LogicalQueryStage.physicalPlan is already wrong. It points to a ShuffleQueryStage instead of a HashAggregate.
Then I do more research about LogicalQueryStage. It looks like the logicalLink of HashAggregate from currentPhysicalPlan is wrong so that LogicalQueryStage’s physicalPlan point to the wrong node.
But why currentPhysicalPlan is wrong? Then I found there is a ‘ghost’ Rule[SparkPlan] called org.apache.spark.sql.execution.CollapseAggregates. This rule will remove some HashAggregate Nodes in PhysicalPlan. So I suspect this class messes the logicalLinks of PhysicalPlan when it collapses HashAggregate.
How to prove my guess?
1. define a print function
I define a new function printHashAggregateExec which can iterate all nodes of one SparkPlan(as known as PhysicalPlan) and print the input/output information if the node is HashAggregateExec:
import org.apache.spark.sql.execution.SparkPlan
import org.apache.spark.sql.execution.aggregate.HashAggregateExec
def printHashAggregateExec(sparkPlan: SparkPlan) {
println(sparkPlan)
sparkPlan.foreach {
case ha: HashAggregateExec =>
println("=====================HashAggregateExec=======================")
println(ha)
println("====groupingExpressions:\n" + ha.groupingExpressions)
println("====resultExpressions: \n" + ha.resultExpressions)
println("")
case _ => print("")
}
}
2. check sparkPlan
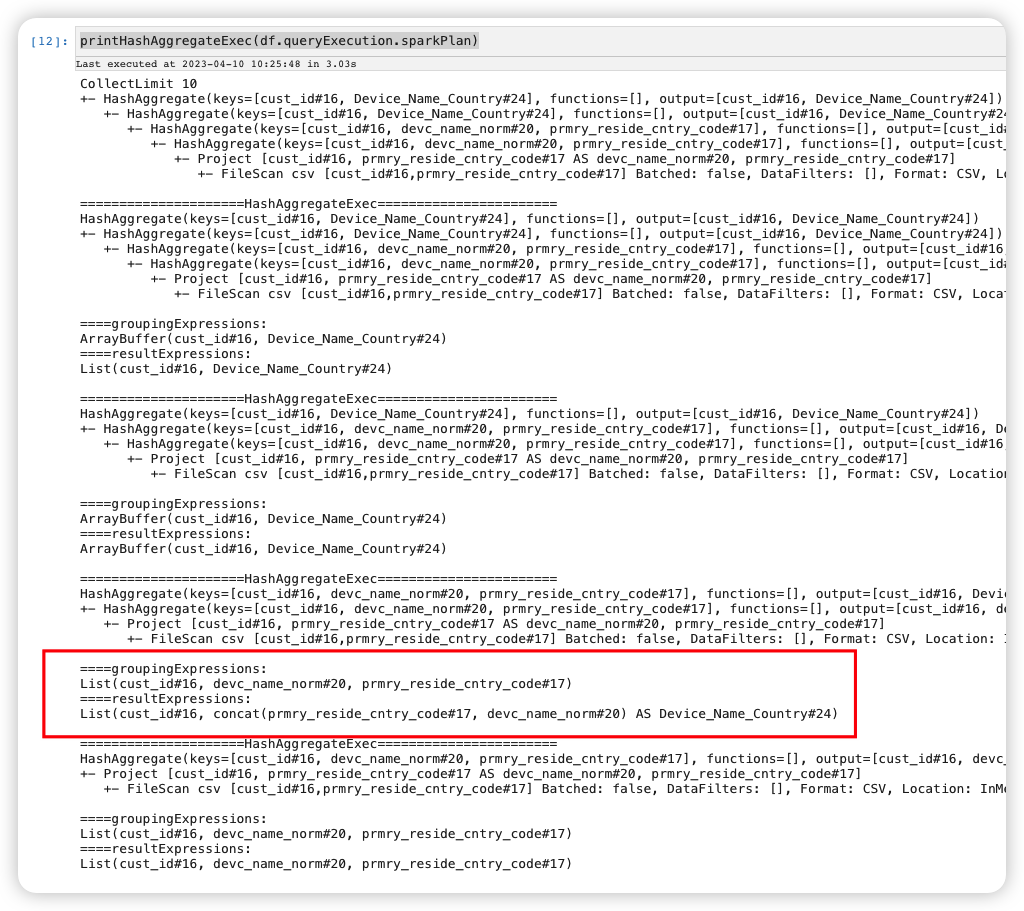
Check df.queryExecution.sparkPlan which is directly transformed from OptimizedLogicalPlan and not apply any PhysicalPlan optimization rules:
printHashAggregateExec(df.queryExecution.sparkPlan)
Its HashAggregateExec are all good:
3. check executedPlan
Checking df.queryExecution.executedPlan which is the PhysicalPlan after applying all PhysicalPlan Optimization rules in QueryExecution.preparations.
printHashAggregateExec(df.queryExecution.executedPlan)
Now you can see the plan is broken. The concat informations is lost in the resultExpressions of one HashAggregateExec:
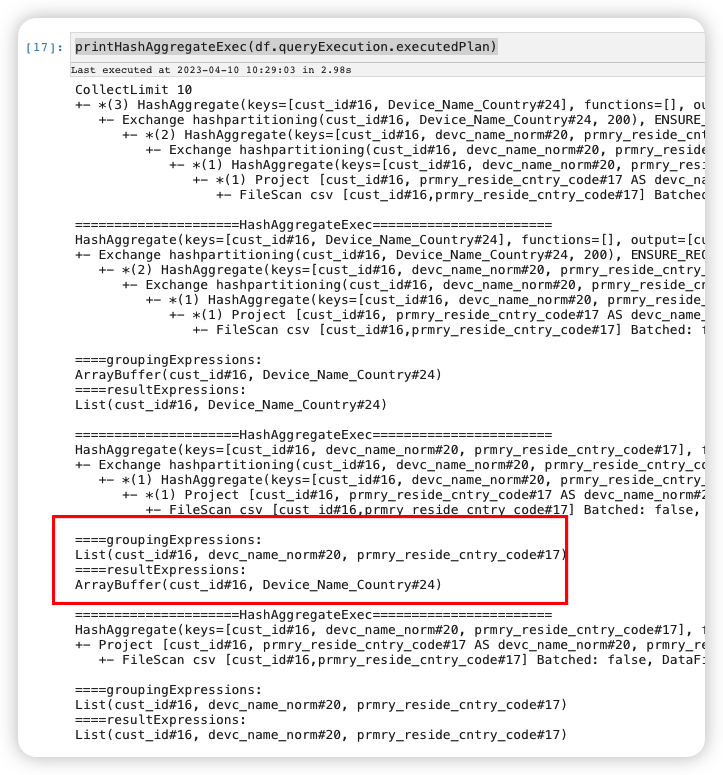
So we can confirm the issue happens when applying the rules in QueryExecution.preparations.
Then I try to apply these rules one by one. Finally, I found CollapseAggregates will break the plan after calling the rule EnsureRequirements:


In the end, we can confirm this issue is definitely involved by CollapseAggregates.
Solution
It’s query simply, just set spark.sql.execution.collapseAggregateNodes=false to bypass the org.apache.spark.sql.execution.CollapseAggregates.
how to find the solution
By searching internet, I find this Spark PR https://github.com/apache/spark/pull/30426. It contains the source code of CollapseAggregates. And don’t why this patch is not in Spark 3.1.3 version but in GCP DataProc Image 2.0. Then by going through that PR’s source code, I found this solution.